
Abstract
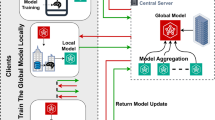
Federated Learning is a distributed machine learning paradigm that enables model training without sharing clients’ raw data. This approach enhances user privacy but incurs large communication overhead due to the extensive number of messages exchanged between clients and the server. Quantization emerges as a prominent solution to mitigate this issue by representing model parameters with fewer bits. However, conventional strategies typically implement quantization at the client level with fixed and unified internal quantization, disregarding the varying significance of different model parameters. In this paper, we explore quantization at both inter-client and intra-client levels, to propose the FedMQ, an innovative framework that implements a balance between communication efficiency and model accuracy. Initially, we devise a multi-grained quantization strategy that determines the quantization bit-depth for model parameters, considering both their importance and the clients’ communication conditions. Subsequently, we design a phased aggregation tactic that enhances model convergence by modulating the influence of quantization errors on aggregated weights in a phased manner. Moreover, we introduce an accuracy compensation technique that periodically adjusts the learning rate to further counteract the accuracy degradation attributable to quantization. Comprehensive evaluations, conducted across a variety of models and datasets, substantiate the advantages of FedMQ. Evaluation results reveal that FedMQ achieves a reduction in communication time ranging from 19.35% to 87.65% while maintaining model accuracy compared to existing baselines.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Wang, Y., et al.: Theoretical convergence guaranteed resource-adaptive federated learning with mixed heterogeneity. In: SIGKDD, pp. 2444–2455 (2023)
Zou, Y., et al.: Value of information: a comprehensive metric for client selection in federated edge learning. IEEE Trans. Comput. (2024)
McMahan, B., Moore, E., et al.: Communication-efficient learn. of deep networks from decentralized data. In: AISTATS, vol. 54, pp. 1273–1282 (2017)
Cao, M., Zhang, Y., et al.: C2s: class-aware client selection for effective aggregation in federated learn. HCC 2(3), 100068 (2022)
Cao, M., Zhao, M., Zhang, T., Yu, N., Lu, J.: FedQL: Q-learning guided aggregation for federated learning. In: ICA3PP, vol. 14487, pp. 263–282 (2023)
Iandola, F.N., et al.: Firecaffe: near-linear acceleration of deep neural network training on compute clusters. In CVPR, pp. 2592–2600 (2016)
Xu, J., Du, W., et al.: Ternary compression for communication-efficient federated learn. TNNLS 33(3), 1162–1176 (2022)
Liu, H., et al.: Communication-efficient federated learn. for heterogeneous edge devices based on adaptive gradient quantization. In: INFOCOM, pp. 1–10 (2023)
Choi, J., Wang, Z., et al.: Pact: parameterized clipping activation for quantized neural networks. arXiv:1805.06085 (2018)
Zhang, C., Li, S., et al.: BatchCrypt: efficient homomorphic encryption for cross-silo federated learn. In: USENIX, pp. 493–506 (2020)
Guo, Y., et al.: A survey on methods and theories of quantized neural networks. arXiv:1808.04752 (2018)
Alistarh, D., Grubic, D., et al.: QSGD: communication-efficient SGD via gradient quantization and encoding. NeurIPS 30, 1709–1720 (2017)
Ramezani, A., et al.: NuqSGD: provably communication-efficient data-parallel SGD via nonuniform quantization. JMLR 22(1), 5074–5116 (2021)
Reisizadeh, A., Mokhtari, A., et al.: FedPaq: a communication-efficient federated learn. method with periodic averaging and quantization. In: AISTATS, vol. 108, pp. 2021–2031 (2020)
Liu, P., Jiang, J., et al.: Training time minimization for federated edge learn. with optimized gradient quantization and bandwidth allocation. FITEE 23(8), 1247–1263 (2022)
Liu, Y.-J., Feng, G., et al.: Ensemble distillation based adaptive quantization for supporting federated learn. in wireless networks. IEEE TWC 22(6), 4013–4027 (2023)
Park, E., Yoo, S., Vajda, P.: Value-aware quantization for training and inference of neural networks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11208, pp. 608–624. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01225-0_36
Li, T., Sahu, A.K., et al.: Federated optimization in heterogeneous networks. In: MLSys (2020)
Aji, A.F., et al.: Sparse communication for distributed gradient descent. In: EMNLS, pp. 440–445 (2017)
Li, Y., Guo, Y., et al.: Joint optimal quantization and aggregation of federated learn. scheme in vanets. T-ITS 23(10), 19:852–19:863 (2022)
Deng, J., Dong, W., et al.: Imagenet: a large-scale hierarchical image database. In: CVPR, pp. 248–255 (2009)
Acknowledgements
This paper is supported by National Natural Science Foundation of China (Grant No. 61973214), Shandong Provincial Natural Science Foundation (Grant No. ZR2020MF069), and Shandong Provincial Postdoctoral Innovation Project (Grant No. 202003005).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Cao, M., Zhang, T., Zhang, B., Lu, J., Shen, Z., Zhao, M. (2025). FedMQ: Multi-grained Quantization for Heterogeneous Federated Learning. In: Cai, Z., Takabi, D., Guo, S., Zou, Y. (eds) Wireless Artificial Intelligent Computing Systems and Applications. WASA 2024. Lecture Notes in Computer Science, vol 14998. Springer, Cham. https://doi.org/10.1007/978-3-031-71467-2_1
Download citation
DOI: https://doi.org/10.1007/978-3-031-71467-2_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-71466-5
Online ISBN: 978-3-031-71467-2
eBook Packages: Computer ScienceComputer Science (R0)