
Abstract
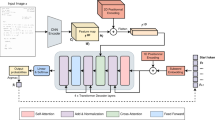
Due to their remarkable performance, general-purpose multimodal pre-trained language models have gained widespread adoption for Document Understanding tasks. The majority of pre-trained language models rely on serialized text, extracted using either Optical Character Recognition (OCR) or PDF parsing. However, accurately determining the reading order of visually-rich documents (VrDs) is challenging, potentially affecting the accuracy of the extracted text and leading to sub-optimal performance in downstream tasks. For information extraction tasks, where entity recognition is commonly framed as a sequence-labeling task, incorrect reading order can hinder entity labeling. In this work, we avoid reading order issues by discarding sequential position information. Based on the intuition that layout contains the information for correct reading order, we present Layout2Pos – a shallow Transformer designed to generate position embeddings from layout. Incorporated into a BART architecture, our approach demonstrates competitiveness with models dependent on reading order across three benchmark datasets for information extraction. We also show that evaluating models using a reading order different from the one seen during training can result in substantial performance drops, thereby highlighting the importance of not relying on the reading order of documents.
Laura Nguyen’s work was conducted under an industrial PhD contract between reciTAL and Sorbonne Université.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
Additionally, the task extends to classifying the relationships between these recognized entities (relation extraction). In this work, we do not focus on this task.
- 2.
This difficulty in accurately predicting the next word is further attributed to the OCR engines’ misinterpretation of certain words.
- 3.
It is noteworthy that a global reading order is unnecessary; there is no requirement to establish an order between two words that belong to segments that have no relation to each other.
- 4.
- 5.
For further information regarding the validation of this architecture, see Sect. 6.1.
- 6.
While we do observe marginal variations for BART+Layout2Pos, we attribute these variances to two factors: 1) longer documents than the maximum sequence length may be segmented into sequences that deviate from the original reading order, and 2) rearranging the sequence might yield tokens that differ from those in the original sequence.
References
Appalaraju, S., Jasani, B., Kota, B.U., Xie, Y., Manmatha, R.: Docformer: end-to-end transformer for document understanding. arXiv preprint arXiv:2106.11539 (2021)
Gu, Z., et al.: Xylayoutlm: towards layout-aware multimodal networks for visually-rich document understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4583–4592 (2022)
Ha, J., Haralick, R.M., Phillips, I.T.: Recursive XY cut using bounding boxes of connected components. In: Proceedings of 3rd International Conference on Document Analysis and Recognition, vol. 2, pp. 952–955, IEEE (1995)
Huang, Z., et al.: ICDAR2019 competition on scanned receipt OCR and information extraction. In: 2019 International Conference on Document Analysis and Recognition (ICDAR), pp. 1516–1520. IEEE (2019)
Jaume, G., Ekenel, H.K., Thiran, J.P.: FUNSD: a dataset for form understanding in noisy scanned documents. In: 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), vol. 2, pp. 1–6. IEEE (2019)
Kay, A.: Tesseract: an open-source optical character recognition engine. Linux J. 2007(159), 2 (2007). ISSN 1075-3583
Kim, G., et al.: OCR-free document understanding transformer. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13688, pp. 498–517. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19815-1_29
Lewis, D., Agam, G., Argamon, S., Frieder, O., Grossman, D., Heard, J.: Building a test collection for complex document information processing. In: Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 665–666 (2006)
Lewis, M., et al.: Bart: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461 (2019)
Mindee: doctr: Document text recognition (2021). https://github.com/mindee/doctr
Park, S., et al.: Cord: a consolidated receipt dataset for post-OCR parsing. In: Workshop on Document Intelligence at NeurIPS 2019 (2019)
Peng, Q., et al.: Ernie-layout: layout knowledge enhanced pre-training for visually-rich document understanding. arXiv preprint arXiv:2210.06155 (2022)
Powalski, R., Borchmann, Ł., Jurkiewicz, D., Dwojak, T., Pietruszka, M., Pałka, G.: Going full-tilt boogie on document understanding with text-image-layout transformer. arXiv preprint arXiv:2102.09550 (2021)
Raffel, C., et al.: Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21(1), 5485–5551 (2020)
Ramshaw, L.A., Marcus, M.P.: Text chunking using transformation-based learning. In: Armstrong, S., Church, K., Isabelle, P., Manzi, S., Tzoukermann, E., Yarowsky, D. (eds.) Natural Language Processing Using Very Large Corpora, pp. 157–176. Springer, Dordrecht (1999). https://doi.org/10.1007/978-94-017-2390-9_10
Sage, C., Aussem, A., Eglin, V., Elghazel, H., Espinas, J.: End-to-end extraction of structured information from business documents with pointer-generator networks. In: Proceedings of the Fourth Workshop on Structured Prediction for NLP, pp. 43–52 (2020)
See, A., Liu, P.J., Manning, C.D.: Get to the point: summarization with pointer-generator networks. arXiv preprint arXiv:1704.04368 (2017)
Townsend, B., Ito-Fisher, E., Zhang, L., May, M.: Doc2dict: information extraction as text generation. arXiv preprint arXiv:2105.07510 (2021)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Wang, Z., Xu, Y., Cui, L., Shang, J., Wei, F.: Layoutreader: pre-training of text and layout for reading order detection (2021)
Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., Zhou, M.: Layoutlm: pre-training of text and layout for document image understanding. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 1192–1200 (2020)
Xu, Y., et al.: Layoutlmv2: multi-modal pre-training for visually-rich document understanding. arXiv preprint arXiv:2012.14740 (2020)
Zhang, C., et al.: Reading order matters: information extraction from visually-rich documents by token path prediction. arXiv preprint arXiv:2310.11016 (2023)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Nguyen, L., Piwowarski, B., Laborde, J., Moyse, G. (2024). Learning Reading Order via Document Layout with Layout2Pos. In: Antonacopoulos, A., et al. Linking Theory and Practice of Digital Libraries. TPDL 2024. Lecture Notes in Computer Science, vol 15177. Springer, Cham. https://doi.org/10.1007/978-3-031-72437-4_1
Download citation
DOI: https://doi.org/10.1007/978-3-031-72437-4_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-72436-7
Online ISBN: 978-3-031-72437-4
eBook Packages: Computer ScienceComputer Science (R0)