
Abstract
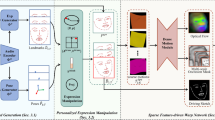
Achieving disentangled control over multiple facial motions and accommodating diverse input modalities greatly enhances the application and entertainment of the talking head generation. This necessitates a deep exploration of the decoupling space for facial features, ensuring that they a) operate independently without mutual interference and b) can be preserved to share with different modal inputs-both aspects often neglected in existing methods. To address this gap, this paper proposes a novel Efficient Disentanglement framework for Talking head generation (EDTalk). Our framework enables individual manipulation of mouth shape, head pose, and emotional expression, conditioned on video or audio inputs. Specifically, we employ three lightweight modules to decompose the facial dynamics into three distinct latent spaces representing mouth, pose, and expression, respectively. Each space is characterized by a set of learnable bases whose linear combinations define specific motions. To ensure independence and accelerate training, we enforce orthogonality among bases and devise an efficient training strategy to allocate motion responsibilities to each space without relying on external knowledge. The learned bases are then stored in corresponding banks, enabling shared visual priors with audio input. Furthermore, considering the properties of each space, we propose an Audio-to-Motion module for audio-driven talking head synthesis. Experiments are conducted to demonstrate the effectiveness of EDTalk. The code and pretrained models are released at: https://tanshuai0219.github.io/EDTalk/
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Afouras, T., Chung, J.S., Senior, A., Vinyals, O., Zisserman, A.: Deep audio-visual speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. 44(12), 8717–8727 (2018)
Blanz, V., Vetter, T.: A morphable model for the synthesis of 3d faces. In: Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, pp. 187–194 (1999)
Bregler, C., Covell, M., Slaney, M.: Video rewrite: driving visual speech with audio. In: Seminal Graphics Papers: Pushing the Boundaries, vol. 2, pp. 715–722 (2023)
Chen, L., et al.: Talking-head generation with rhythmic head motion. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12354, pp. 35–51. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58545-7_3
Chen, L., Li, Z., Maddox, R.K., Duan, Z., Xu, C.: Lip movements generation at a glance. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 520–535 (2018)
Chen, L., Maddox, R.K., Duan, Z., Xu, C.: Hierarchical cross-modal talking face generation with dynamic pixel-wise loss. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7832–7841 (2019)
Chen, L., et al.: Vast: vivify your talking avatar via zero-shot expressive facial style transfer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2977–2987 (2023)
Chung, J.S., Nagrani, A., Zisserman, A.: Voxceleb2: deep speaker recognition. arXiv preprint arXiv:1806.05622 (2018)
Chung, J.S., Zisserman, A.: Lip reading in the wild. In: Lai, S.-H., Lepetit, V., Nishino, K., Sato, Y. (eds.) ACCV 2016. LNCS, vol. 10112, pp. 87–103. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-54184-6_6
Chung, J.S., Zisserman, A.: Out of time: automated lip sync in the wild. In: Chen, C.-S., Lu, J., Ma, K.-K. (eds.) ACCV 2016. LNCS, vol. 10117, pp. 251–263. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-54427-4_19
Daněček, R., Black, M.J., Bolkart, T.: Emoca: emotion driven monocular face capture and animation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20311–20322 (2022)
Das, D., Biswas, S., Sinha, S., Bhowmick, B.: Speech-driven facial animation using cascaded GANs for learning of motion and texture. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12375, pp. 408–424. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58577-8_25
Ekman, P., Friesen, W.V.: Facial action coding system. Environ. Psychol. Nonverbal Behav. (1978)
Gan, Y., Yang, Z., Yue, X., Sun, L., Yang, Y.: Efficient emotional adaptation for audio-driven talking-head generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 22634–22645 (2023)
Goyal, S., et al.: Emotionally enhanced talking face generation. In: Proceedings of the 1st International Workshop on Multimedia Content Generation and Evaluation: New Methods and Practice, pp. 81–90 (2023)
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729–9738 (2020)
Hong, F.T., Zhang, L., Shen, L., Xu, D.: Depth-aware generative adversarial network for talking head video generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3397–3406 (2022)
Hsu, W.N., Bolte, B., Tsai, Y.H.H., Lakhotia, K., Salakhutdinov, R., Mohamed, A.: Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 29, 3451–3460 (2021)
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1501–1510 (2017)
Ji, X., et al.: Eamm: one-shot emotional talking face via audio-based emotion-aware motion model. In: ACM SIGGRAPH 2022 Conference Proceedings, pp. 1–10 (2022)
Ji, X., Zhou, H., Wang, K., Wu, W., Loy, C.C., Cao, X., Xu, F.: Audio-driven emotional video portraits. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14080–14089 (2021)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 694–711. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_43
Khakhulin, T., Sklyarova, V., Lempitsky, V., Zakharov, E.: Realistic one-shot mesh-based head avatars. In: European Conference on Computer Vision, pp. 345–362. Springer, Heidelberg (2022). https://doi.org/10.1007/978-3-031-20086-1_20
Khosla, P., et al.: Supervised contrastive learning. Adv. Neural. Inf. Process. Syst. 33, 18661–18673 (2020)
Kim, T., Vossen, P.: Emoberta: speaker-aware emotion recognition in conversation with roberta. arXiv preprint arXiv:2108.12009 (2021)
Li, D., et al.: Ae-nerf: audio enhanced neural radiance field for few shot talking head synthesis. arXiv preprint arXiv:2312.10921 (2023)
Liang, B., et al.: Expressive talking head generation with granular audio-visual control. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3387–3396 (2022)
Liu, T., et al.: Anitalker: animate vivid and diverse talking faces through identity-decoupled facial motion encoding. arXiv preprint arXiv:2405.03121 (2024)
Liu, X., Xu, Y., Wu, Q., Zhou, H., Wu, W., Zhou, B.: Semantic-aware implicit neural audio-driven video portrait generation. In: European Conference on Computer Vision, pp. 106–125. Springer, Heidelberg (2022). https://doi.org/10.1007/978-3-031-19836-6_7
Ma, Y., et al.: Talkclip: talking head generation with text-guided expressive speaking styles. arXiv preprint arXiv:2304.00334 (2023)
Ma, Y., et al.: Styletalk: one-shot talking head generation with controllable speaking styles. arXiv preprint arXiv:2301.01081 (2023)
Meng, D., Peng, X., Wang, K., Qiao, Y.: Frame attention networks for facial expression recognition in videos. In: 2019 IEEE International Conference on Image Processing (ICIP), pp. 3866–3870. IEEE (2019)
Pang, Y., et al.: DPE: disentanglement of pose and expression for general video portrait editing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 427–436 (2023)
Park, S.J., Kim, M., Hong, J., Choi, J., Ro, Y.M.: Synctalkface: talking face generation with precise lip-syncing via audio-lip memory. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 2062–2070 (2022)
Pataranutaporn, P., et al.: Ai-generated characters for supporting personalized learning and well-being. Nat. Mach. Intell. 3(12), 1013–1022 (2021)
Prajwal, K., Mukhopadhyay, R., Namboodiri, V.P., Jawahar, C.: A lip sync expert is all you need for speech to lip generation in the wild. In: Proceedings of the 28th ACM International Conference on Multimedia, pp. 484–492 (2020)
Rezende, D., Mohamed, S.: Variational inference with normalizing flows. In: International Conference on Machine Learning, pp. 1530–1538. PMLR (2015)
Seitzer, M.: pytorch-fid: FID Score for PyTorch (2020). https://github.com/mseitzer/pytorch-fid. version 0.3.0
Shen, S., Li, W., Zhu, Z., Duan, Y., Zhou, J., Lu, J.: Learning dynamic facial radiance fields for few-shot talking head synthesis. In: European Conference on Computer Vision, pp. 666–682. Springer, Heidelberg (2022). https://doi.org/10.1007/978-3-031-19775-8_39
Shen, S., et al.: Difftalk: crafting diffusion models for generalized audio-driven portraits animation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1982–1991 (2023)
Siarohin, A., Lathuilière, S., Tulyakov, S., Ricci, E., Sebe, N.: First order motion model for image animation. Adv. Neural Inf. Process. Syst. 32 (2019)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Sinha, S., Biswas, S., Yadav, R., Bhowmick, B.: Emotion-controllable generalized talking face generation. In: International Joint Conference on Artificial Intelligence. IJCAI (2021)
Song, Y., Zhu, J., Li, D., Wang, A., Qi, H.: Talking face generation by conditional recurrent adversarial network. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (2019). https://doi.org/10.24963/ijcai.2019/129
Tan, S., Ji, B., Pan, Y.: Emmn: emotional motion memory network for audio-driven emotional talking face generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 22146–22156 (2023)
Thies, J., Elgharib, M., Tewari, A., Theobalt, C., Nießner, M.: Neural voice puppetry: audio-driven facial reenactment. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12361, pp. 716–731. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58517-4_42
Wang, D., Deng, Y., Yin, Z., Shum, H.Y., Wang, B.: Progressive disentangled representation learning for fine-grained controllable talking head synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17979–17989 (2023)
Wang, J., Qian, X., Zhang, M., Tan, R.T., Li, H.: Seeing what you said: talking face generation guided by a lip reading expert. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14653–14662 (2023)
Wang, J., et al.: Lipformer: high-fidelity and generalizable talking face generation with a pre-learned facial codebook. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13844–13853 (2023)
Wang, K., et al.: MEAD: a large-scale audio-visual dataset for emotional talking-face generation. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12366, pp. 700–717. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58589-1_42
Wang, S., Li, L., Ding, Y., Fan, C., Yu, X.: Audio2head: audio-driven one-shot talking-head generation with natural head motion. In: International Joint Conference on Artificial Intelligence. IJCAI (2021)
Wang, S., Li, L., Ding, Y., Yu, X.: One-shot talking face generation from single-speaker audio-visual correlation learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 2531–2539 (2022)
Wang, Y., Yang, D., Bremond, F., Dantcheva, A.: Latent image animator: learning to animate images via latent space navigation. In: International Conference on Learning Representations (2021)
Wang, Y., Boumadane, A., Heba, A.: A fine-tuned wav2vec 2.0/hubert benchmark for speech emotion recognition, speaker verification and spoken language understanding. arXiv preprint arXiv:2111.02735 (2021)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004)
Yang, K., Chen, K., Guo, D., Zhang, S.H., Guo, Y.C., Zhang, W.: Face2face \(\rho \): Real-time high-resolution one-shot face reenactment. In: European Conference on Computer Vision, pp. 55–71. Springer, Heidelberg (2022). https://doi.org/10.1007/978-3-031-19778-9_4
Yin, F., et al.: Styleheat: One-shot high-resolution editable talking face generation via pre-trained stylegan. In: European Conference on Computer Vision, pp. 85–101. Springer, Heidelberg (2022). https://doi.org/10.1007/978-3-031-19790-1_6
Yu, Z., Yin, Z., Zhou, D., Wang, D., Wong, F., Wang, B.: Talking head generation with probabilistic audio-to-visual diffusion priors. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7645–7655 (2023)
Zakharov, E., Shysheya, A., Burkov, E., Lempitsky, V.: Few-shot adversarial learning of realistic neural talking head models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9459–9468 (2019)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 586–595 (2018)
Zhang, W., et al.: Sadtalker: learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8652–8661 (2023)
Zhang, Z., Li, L., Ding, Y., Fan, C.: Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3661–3670 (2021)
Zhong, W., et al.: Identity-preserving talking face generation with landmark and appearance priors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729–9738 (2023)
Zhou, H., Liu, Y., Liu, Z., Luo, P., Wang, X.: Talking face generation by adversarially disentangled audio-visual representation. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 9299–9306 (2019)
Zhou, H., Sun, Y., Wu, W., Loy, C.C., Wang, X., Liu, Z.: Pose-controllable talking face generation by implicitly modularized audio-visual representation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4176–4186 (2021)
Zhou, Y., Han, X., Shechtman, E., Echevarria, J., Kalogerakis, E., Li, D.: Makelttalk: speaker-aware talking-head animation. ACM Trans. Graph. (TOG) 39(6), 1–15 (2020)
Acknowledgements
This work was supported by National Natural Science Foundation of China (NSFC, NO. 62102255), NetEase Fuxi Lab Industry-University Collaboration Research Funding.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Tan, S., Ji, B., Bi, M., Pan, Y. (2025). EDTalk: Efficient Disentanglement for Emotional Talking Head Synthesis. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds) Computer Vision – ECCV 2024. ECCV 2024. Lecture Notes in Computer Science, vol 15064. Springer, Cham. https://doi.org/10.1007/978-3-031-72658-3_23
Download citation
DOI: https://doi.org/10.1007/978-3-031-72658-3_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-72657-6
Online ISBN: 978-3-031-72658-3
eBook Packages: Computer ScienceComputer Science (R0)