
Abstract
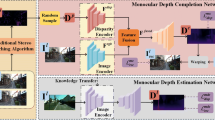
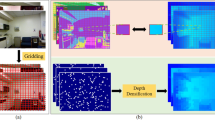
In the area of self-supervised monocular depth estimation, models that utilize rich-resource inputs, such as high-resolution and multi-frame inputs, typically achieve better performance than models that use ordinary single image input. However, these rich-resource inputs may not always be available, limiting the applicability of these methods in general scenarios. In this paper, we propose Rich-resource Prior Depth estimator (RPrDepth), which only requires single input image during the inference phase but can still produce highly accurate depth estimations comparable to rich-resource based methods. Specifically, we treat rich-resource data as prior information and extract features from it as reference features in an offline manner. When estimating the depth for a single-image image, we search for similar pixels from the rich-resource features and use them as prior information to estimate the depth. Experimental results demonstrate that our model outperform other single-image model and can achieve comparable or even better performance than models with rich-resource inputs, only using low-resolution single-image input.
This work was supported in part by the FDCT grants 0102/2023/RIA2, 0154/2022/A3, and 001/2024/SKL, the MYRG-CRG2022-00013-IOTSC-ICI grant and the SRG2022-00023-IOTSC grant.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Agarwal, A., Arora, C.: Depthformer: multiscale vision transformer for monocular depth estimation with local global information fusion. arXiv preprint arXiv:2207.04535 (2022)
Bae, J., Moon, S., Im, S.: Monoformer: towards generalization of self-supervised monocular depth estimation with transformers. arXiv preprint arXiv:2205.11083 (2022)
van Dijk, T., de Croon, G.: How do neural networks see depth in single images? In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2183–2191 (2019)
Eigen, D., Fergus, R.: Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: ICCV (2015)
Feng, Z., Yang, L., Jing, L., Wang, H., Tian, Y.L., Li, B.: Disentangling object motion and occlusion for unsupervised multi-frame monocular depth. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13692, pp. 228–244. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19824-3_14
Garg, R., B.G., V.K., Carneiro, G., Reid, I.: Unsupervised CNN for single view depth estimation: geometry to the rescue. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 740–756. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_45
Godard, C., Mac Aodha, O., Firman, M., Brostow, G.J.: Digging into self-supervised monocular depth estimation. In: ICCV (2019)
Gordon, A., Li, H., Jonschkowski, R., Angelova, A.: Depth from videos in the wild: unsupervised monocular depth learning from unknown cameras. In: ICCV, pp. 8977–8986 (2019)
Guizilini, V., Ambrus, R., Pillai, S., Raventos, A, Gaidon, A.: 3D packing for self-supervised monocular depth estimation. In: CVPR (2020)
Guizilini, V., Ambruş, R., Chen, D., Zakharov, S., Gaidon, A.: Multi-frame self-supervised depth with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 160–170 (2022)
Han, W., Yin, J., Shen, J.: Self-supervised monocular depth estimation by direction-aware cumulative convolution network. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8613–8623 (2023)
Hui, T.-W.: RM-depth: unsupervised learning of recurrent monocular depth in dynamic scenes. In: CVPR (2022)
Kumar, V.R., Yogamani, S., Bach, M., Witt, C., Milz, S., Mäder, P.: Unrectdepthnet: self-supervised monocular depth estimation using a generic framework for handling common camera distortion models. In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 8177–8183. IEEE (2020)
Laga, H., Jospin, L.V., Boussaid, F., Bennamoun, M.: A survey on deep learning techniques for stereo-based depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. (2020)
Lee, J.H., Han, M.K., Ko, D.W., Suh, I.H.: From big to small: multi-scale local planar guidance for monocular depth estimation. arXiv preprint arXiv:1907.10326 (2019)
Li, B., Shen, C., Dai, Y., Van Den Hengel, A., He, M.: Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In: CVPR (2015)
Li, H., Gordon, A., Zhao, H., Casser, V., Angelova, A.: Unsupervised monocular depth learning in dynamic scenes. In: Conference on Robot Learning, pp. 1908–1917. PMLR (2021)
Liu, K., Zhou, C., Wei, S., Wang, S., Fan, X., Ma, J.: Optimized stereo matching in binocular three-dimensional measurement system using structured light. Appl. Opt. 53(26), 6083–6090 (2014)
Lyu, X., et al.: HR-depth: high resolution self-supervised monocular depth estimation. CoRR abs/2012.07356 (2020)
Masoumian, A., Marei, D.G.F., Abdulwahab, S., Cristiano, J., Puig, D., Rashwan, H.A.: Absolute distance prediction based on deep learning object detection and monocular depth estimation models. In: CCIA, pp. 325–334 (2021)
Pillai, S., Ambruş, R., Gaidon, A.: Superdepth: self-supervised, super-resolved monocular depth estimation. In: ICRA (2019)
Poggi, M., Aleotti, F., Tosi, F., Mattoccia, S.: On the uncertainty of self-supervised monocular depth estimation. In: CVPR (2020)
Poggi, M., Tosi, F., Mattoccia, S.: Learning monocular depth estimation with unsupervised trinocular assumptions. In: 3DV (2018)
Qi, X., Liao, R., Liu, Z., R., Urtasun, Z., Jia, J.: Geonet: geometric neural network for joint depth and surface normal estimation. In: CVPR (2018)
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V.: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. (2020)
Ranjan, A., et al.: Competitive collaboration: joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. In: CVPR (2019)
Sun, K., et al.: High-resolution representations for labeling pixels and regions. arXiv preprint arXiv:1904.04514 (2019)
Swami, K., Muduli, A., Gurram, U., Bajpai, P.: Do what you can, with what you have: scale-aware and high quality monocular depth estimation without real world labels. In: CVPR (2022)
Ummenhofer, B., et al.: Demon: depth and motion network for learning monocular stereo. In: CVPR (2017)
Wang, J., Zhang, G., Wu, Z., Li, X., Liu, L.: Self-supervised joint learning framework of depth estimation via implicit cues. arXiv preprint arXiv:2006.09876 (2020)
Watson, J., Firman, M., Brostow, G.J., Turmukhambetov, D.: Self-supervised monocular depth hints. In: ICCV, pp. 2162–2171 (2019)
Watson, J., Aodha, O.M., Prisacariu, V., Brostow, G., Firman, M.: The temporal opportunist: self-supervised multi-frame monocular depth. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1164–1174 (2021)
Watson, J., Mac Aodha, O., Prisacariu, V., Brostow, G., Firman, M.: The temporal opportunist: self-supervised multi-frame monocular depth. In: CVPR (2021)
Wencheng, H., Junbo, Y., Xiaogang, J., Xiangdong, D., Jianbing, S.: Brnet: exploring comprehensive features for monocular depth estimation. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13698, pp. 586–602. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19839-7_34
Xu, C., Huang, B., Elson, D.S.: Self-supervised monocular depth estimation with 3-D displacement module for laparoscopic images. IEEE Trans. Med. Robot. Bionics 4(2), 331–334 (2022)
Zhang, N., Nex, F., Vosselman, G., Kerle, N.: Lite-mono: a lightweight CNN and transformer architecture for self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18537–18546 (2023)
Zhao, C., et al.: Monovit: self-supervised monocular depth estimation with a vision transformer. In: 2022 International Conference on 3D Vision (3DV), pp. 668–678. IEEE (2022)
Zhou, H., Greenwood, D., Taylor, S.: Self-supervised monocular depth estimation with internal feature fusion. In: British Machine Vision Conference (BMVC) (2021)
Zhou, T., Brown, M., Snavely, N., Lowe, D.G.: Unsupervised learning of depth and ego-motion from video. In: CVPR (2017)
Zhou, Z., Dong, Q.: Self-distilled feature aggregation for self-supervised monocular depth estimation. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13661, pp. 709–726. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19769-7_41
Zhou, Z., Fan, X., Shi, P., Xin, Y.: R-msfm: recurrent multi-scale feature modulation for monocular depth estimating. In: ICCV (2021)
Zou, Y., Luo, Z., Huang, J.-B.: DF-net: unsupervised joint learning of depth and flow using cross-task consistency. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11209, pp. 38–55. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01228-1_3
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Han, W., Shen, J. (2025). High-Precision Self-supervised Monocular Depth Estimation with Rich-Resource Prior. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds) Computer Vision – ECCV 2024. ECCV 2024. Lecture Notes in Computer Science, vol 15089. Springer, Cham. https://doi.org/10.1007/978-3-031-72751-1_9
Download citation
DOI: https://doi.org/10.1007/978-3-031-72751-1_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-72750-4
Online ISBN: 978-3-031-72751-1
eBook Packages: Computer ScienceComputer Science (R0)