
Abstract
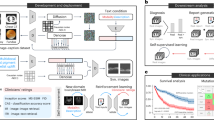
Text-conditional medical image generation is vital for radiology, augmenting small datasets, preserving data privacy, and enabling patient-specific modeling. However, its applications in 3D medical imaging, such as CT and MRI, which are crucial for critical care, remain unexplored. In this paper, we introduce GenerateCT, the first approach to generating 3D medical imaging conditioned on free-form medical text prompts. GenerateCT incorporates a text encoder and three key components: a novel causal vision transformer for encoding 3D CT volumes, a text-image transformer for aligning CT and text tokens, and a text-conditional super-resolution diffusion model. Without directly comparable methods in 3D medical imaging, we benchmarked GenerateCT against cutting-edge methods, demonstrating its superiority across all key metrics. Importantly, we explored GenerateCT’s clinical applications by evaluating its utility in a multi-abnormality classification task. First, we established a baseline by training a multi-abnormality classifier on our real dataset. To further assess the model’s generalization to external datasets and its performance with unseen prompts in a zero-shot scenario, we employed an external dataset to train the classifier, setting an additional benchmark. We conducted two experiments in which we doubled the training datasets by synthesizing an equal number of volumes for each set using GenerateCT. The first experiment demonstrated an \(11\%\) improvement in the AP score when training the classifier jointly on real and generated volumes. The second experiment showed a \(7\%\) improvement when training on both real and generated volumes based on unseen prompts. Moreover, GenerateCT enables the scaling of synthetic training datasets to arbitrary sizes. As an example, we generated 100,000 3D CT volumes, fivefold the number in our real dataset, and trained the classifier exclusively on these synthetic volumes. Impressively, this classifier surpassed the performance of the one trained on all available real data by a margin of \(8\%\). Lastly, domain experts evaluated the generated volumes, confirming a high degree of alignment with the text prompts. Access our code, model weights, training data, and generated data at https://github.com/ibrahimethemhamamci/GenerateCT.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., Schmid, C.: Vivit: a video vision transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6836–6846 (2021)
Balaji, Y., et al.: eDiff-I: text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324 (2022)
Beltagy, I., Peters, M.E., Cohan, A.: Longformer: the long-document transformer. arXiv preprint arXiv:2004.05150 (2020)
Blattmann, A., et al.: Align your latents: high-resolution video synthesis with latent diffusion models. arXiv preprint arXiv:2304.08818 (2023)
Chambon, P., et al.: Roentgen: vision-language foundation model for chest x-ray generation. arXiv preprint arXiv:2211.12737 (2022)
Chang, H., Zhang, H., Jiang, L., Liu, C., Freeman, W.T.: Maskgit: masked generative image transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11315–11325 (2022)
Chen, W., Hu, H., Saharia, C., Cohen, W.W.: Re-imagen: retrieval-augmented text-to-image generator. arXiv preprint arXiv:2209.14491 (2022)
Clark, A., Donahue, J., Simonyan, K.: Adversarial video generation on complex datasets. arXiv preprint arXiv:1907.06571 (2019)
DenOtter, T.D., Schubert, J.: Hounsfield unit (2019)
Ding, M., et al.: Cogview: mastering text-to-image generation via transformers. In: Advances in Neural Information Processing Systems, vol. 34, pp. 19822–19835 (2021)
Draelos, R.L., et al.: Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes. Med. Image Anal. 67, 101857 (2021)
Gu, S., et al.: Vector quantized diffusion model for text-to-image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10696–10706 (2022)
Hamamci, I.E., et al.: A foundation model utilizing chest CT volumes and radiology reports for supervised-level zero-shot detection of abnormalities. arXiv preprint arXiv:2403.17834 (2024)
Hamamci, I.E., et al.: Diffusion-based hierarchical multi-label object detection to analyze panoramic dental X-rays. In: Greenspan, H., et al. (eds.) MICCAI 2023. LNCS, vol. 14225, pp. 389–399. Springer, Cham (2023). https://doi.org/10.1007/978-3-031-43987-2_38
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: GANs trained by a two time-scale update rule converge to a local nash equilibrium. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Ho, J., et al.: Imagen video: high definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
Ho, J., Saharia, C., Chan, W., Fleet, D.J., Norouzi, M., Salimans, T.: Cascaded diffusion models for high fidelity image generation. J. Mach. Learn. Res. 23(47), 1–33 (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. arXiv preprint arXiv:2204.03458 (2022)
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: large-scale pretraining for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868 (2022)
Johnson, A.E., et al.: MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Sci. Data 6(1), 317 (2019)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 694–711. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_43
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of stylegan. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8110–8119 (2020)
Kebaili, A., Lapuyade-Lahorgue, J., Ruan, S.: Deep learning approaches for data augmentation in medical imaging: a review. J. Imaging 9(4), 81 (2023)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Lamba, R., et al.: CT hounsfield numbers of soft tissues on unenhanced abdominal CT scans: variability between two different manufacturers’ MDCT scanners. AJR Am. J. Roentgenol. 203(5), 1013 (2014)
Lee, H., et al.: Unified chest X-ray and radiology report generation model with multi-view chest X-rays. arXiv preprint arXiv:2302.12172 (2023)
Linna, N., Kahn Jr, C.E.: Applications of natural language processing in radiology: a systematic review. Int. J. Med. Inform. 104779 (2022)
Nichol, A., et al.: Glide: towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021)
Radford, A., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning, pp. 8748–8763. PMLR (2021)
Raffel, C., et al.: Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21(1), 5485–5551 (2020)
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684–10695 (2022)
Saharia, C., et al.: Palette: image-to-image diffusion models. In: ACM SIGGRAPH 2022 Conference Proceedings, pp. 1–10 (2022)
Saharia, C., et al.: Photorealistic text-to-image diffusion models with deep language understanding. In: Advances in Neural Information Processing Systems, vol. 35, pp.36479–36494 (2022)
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: FVD: a new metric for video generation (2019)
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Villegas, R., et al.: Phenaki: variable length video generation from open domain textual description. arXiv preprint arXiv:2210.02399 (2022)
Voleti, V., Jolicoeur-Martineau, A., Pal, C.: Masked conditional video diffusion for prediction, generation, and interpolation. arXiv preprint arXiv:2205.09853 (2022)
Willemink, M.J., Noël, P.B.: The evolution of image reconstruction for CT–from filtered back projection to artificial intelligence. Eur. Radiol. 29, 2185–2195 (2019)
Wu, C., et al.: Godiva: generating open-domain videos from natural descriptions. arXiv preprint arXiv:2104.14806 (2021)
Wu, C., et al.: Nüwa: visual synthesis pre-training for neural visual world creation. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13676, pp. 720–736. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19787-1_41
Yan, W., Zhang, Y., Abbeel, P., Srinivas, A.: Videogpt: video generation using VQ-VAE and transformers. arXiv preprint arXiv:2104.10157 (2021)
Yang, R., Srivastava, P., Mandt, S.: Diffusion probabilistic modeling for video generation. arXiv preprint arXiv:2203.09481 (2022)
Yu, J., et al.: Vector-quantized image modeling with improved VQGAN. arXiv preprint arXiv:2110.04627 (2021)
Yu, J., et al.: Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789 (2022)
Zhang, C., Zhang, C., Zhang, M., Kweon, I.S.: Text-to-image diffusion model in generative AI: a survey. arXiv preprint arXiv:2303.07909 (2023)
Acknowledgments
We thank the Helmut Horten Foundation for their support and Istanbul Medipol University for providing the CT-RATE dataset.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary material 2 (mp4 6896 KB)
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Hamamci, I.E. et al. (2025). GenerateCT: Text-Conditional Generation of 3D Chest CT Volumes. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds) Computer Vision – ECCV 2024. ECCV 2024. Lecture Notes in Computer Science, vol 15137. Springer, Cham. https://doi.org/10.1007/978-3-031-72986-7_8
Download citation
DOI: https://doi.org/10.1007/978-3-031-72986-7_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-72985-0
Online ISBN: 978-3-031-72986-7
eBook Packages: Computer ScienceComputer Science (R0)