
Abstract
The visual detection and tracking of surface terrain is required for spacecraft to safely land on or navigate within close proximity to celestial objects. Current approaches rely on template matching with pre-gathered patch-based features, which are expensive to obtain and a limiting factor in perceptual capability. While recent literature has focused on in-situ detection methods to enhance navigation and operational autonomy, robust description is still needed. In this work, we explore metric learning as the lightweight feature description mechanism and find that current solutions fail to address inter-class similarity and multi-view observational geometry. We attribute this to the view-unaware attention mechanism and introduce Multi-view Attention Regularizations (MARs) to constrain the channel and spatial attention across multiple feature views, regularizing the what and where of attention focus. We thoroughly analyze many modern metric learning losses with and without MARs and demonstrate improved terrain-feature recognition performance by upwards of 85%. We additionally introduce the Luna-1 dataset, consisting of Moon crater landmarks and reference navigation frames from NASA mission data to support future research in this difficult task. Luna-1 and source code are publicly available at https://droneslab.github.io/mars/ .
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
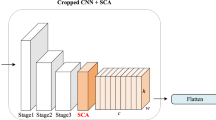
Similar content being viewed by others


References
Ali, S., Sullivan, J., Maki, A., Carlsson, S.: A baseline for visual instance retrieval with deep convolutional networks. In: Proceedings of International Conference on Learning Representations (2015)
Ali-Bey, A., Chaib-Draa, B., Giguere, P.: MixVPR: feature mixing for visual place recognition. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 2998–3007 (2023)
An, X., et al.: Unicom: universal and compact representation learning for image retrieval. arXiv preprint arXiv:2304.05884 (2023)
Bai, S., Bai, X.: Sparse contextual activation for efficient visual re-ranking. IEEE Trans. Image Process. 25(3), 1056–1069 (2016)
Bera, A., Wharton, Z., Liu, Y., Bessis, N., Behera, A.: SR-GNN: spatial relation-aware graph neural network for fine-grained image categorization. IEEE Trans. Image Process. 31, 6017–6031 (2022)
Berton, G., Masone, C., Caputo, B.: Rethinking visual geo-localization for large-scale applications. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4878–4888 (2022)
Berton, G., Trivigno, G., Caputo, B., Masone, C.: EigenPlaces: training viewpoint robust models for visual place recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 11080–11090 (2023)
Blender Online Community: Blender - A 3D Modelling and Rendering Package. Blender Foundation (2018). http://www.blender.org
Bowles, M., Bromley, M., Allen, M., Scaife, A.: E (2) equivariant self-attention for radio astronomy. arXiv preprint arXiv:2111.04742 (2021)
Brewer, C., et al.: NASA spacecube intelligent multi-purpose system for enabling remote sensing, communication, and navigation in mission architectures. In: Proceedings of the Small Satellite Conference. No. SSC20-VI-07, AIAA/USU (2020)
Bruintjes, R.J., Motyka, T., van Gemert, J.: What affects learned equivariance in deep image recognition models? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4838–4846 (2023)
Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., Joulin, A.: Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural. Inf. Process. Syst. 33, 9912–9924 (2020)
Chase, T., Goodwill, J., Dantu, K., Wilson, C.: Profiling vision-based deep learning architectures on NASA spacecube platforms. In: 2024 IEEE Aerospace Conference, pp. 1–16 (2024). https://doi.org/10.1109/AERO58975.2024.10521096
Chase Jr, T., Gnam, C., Crassidis, J., Dantu, K.: You only crash once: improved object detection for real-time, sim-to-real hazardous terrain detection and classification for autonomous planetary landings. arXiv preprint arXiv:2303.04891 (2023)
Chen, N., Villar, S.: Se (3)-equivariant self-attention via invariant features. In: Machine Learning for Physics NeurIPS Workshop (2022)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: International Conference on Machine Learning, pp. 1597–1607. PMLR (2020)
Chen, W., et al.: Deep learning for instance retrieval: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 45(6), 7270–7292 (2023). https://doi.org/10.1109/TPAMI.2022.3218591
Chen, W., et al.: Beyond appearance: a semantic controllable self-supervised learning framework for human-centric visual tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15050–15061 (2023)
Cheng, G., Han, J., Lu, X.: Remote sensing image scene classification: benchmark and state of the art. Proc. IEEE 105(10), 1865–1883 (2017)
Chou, P.Y., Kao, Y.Y., Lin, C.H.: Fine-grained visual classification with high-temperature refinement and background suppression. arXiv preprint arXiv:2303.06442 (2023)
Chung, H., Nam, W.J., Lee, S.W.: Rotation invariant aerial image retrieval with group convolutional metric learning (2020)
Cohen, T.S., Welling, M.: Steerable cnns. arXiv preprint arXiv:1612.08498 (2016)
Dai, J., et al.: Deformable convolutional networks (2017)
Darvish, M., Pouramini, M., Bahador, H.: Towards fine-grained image classification with generative adversarial networks and facial landmark detection. In: 2022 International Conference on Machine Vision and Image Processing (MVIP), pp. 1–6. IEEE (2022)
Deng, J., Guo, J., Liu, T., Gong, M., Zafeiriou, S.: Sub-center ArcFace: boosting face recognition by large-scale noisy web faces. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020, Part XI. LNCS, vol. 12356, pp. 741–757. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58621-8_43
Diao, Q., Jiang, Y., Wen, B., Sun, J., Yuan, Z.: MetaFormer: a unified meta framework for fine-grained recognition. arXiv preprint arXiv:2203.02751 (2022)
Dieleman, S., De Fauw, J., Kavukcuoglu, K.: Exploiting cyclic symmetry in convolutional neural networks. In: International Conference on Machine Learning, pp. 1889–1898. PMLR (2016)
Do, T.T., Cheung, N.M.: Embedding based on function approximation for large scale image search. IEEE Trans. Pattern Anal. Mach. Intell. 40(3), 626–638 (2017)
Doran, G., Lu, S., Mandrake, L., Wagstaff, K.: Mars orbital image (HiRISE) labeled data set version 3 (2019). https://doi.org/10.5281/zenodo.2538136
Downes, L., Steiner, T.J., How, J.P.: Deep learning crater detection for lunar terrain relative navigation. In: AIAA Scitech 2020 Forum (2020). https://doi.org/10.2514/6.2020-1838. https://arc.aiaa.org/doi/abs/10.2514/6.2020-1838
Dunkel, E., et al.: Benchmarking deep learning inference of remote sensing imagery on the qualcomm snapdragon and intel movidius myriad X processors onboard the international space station. In: IGARSS 2022 - 2022 IEEE International Geoscience and Remote Sensing Symposium, pp. 5301–5304 (2022). https://doi.org/10.1109/IGARSS46834.2022.9884906
Ermolov, A., Mirvakhabova, L., Khrulkov, V., Sebe, N., Oseledets, I.: Hyperbolic vision transformers: combining improvements in metric learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7409–7419 (2022)
Esteves, C., Allen-Blanchette, C., Zhou, X., Daniilidis, K.: Polar transformer networks. arXiv preprint arXiv:1709.01889 (2017)
Fu, D., et al.: Unsupervised pre-training for person re-identification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14750–14759 (2021)
Gaskell, R.W., et al.: Characterizing and navigating small bodies with imaging data. Meteorit. Planet. Sci. 43(6) (2008)
Geist, A., et al.: SpaceCube V3. 0 NASA next-generation high-performance processor for science applications. In: Proceedings of the Small Satellite Conference. No. SSC19-XII-02. AIAA/USU (2019)
Geist, A., et al.: NASA spacecube next-generation artificial-intelligence computing for STP-H9-scenic on ISS. In: Proceedings of the Small Satellite Conference. No. SSC23-P1-32, AIAA/USU (2023)
Gentil, C.L., Vayugundla, M., Giubilato, R., Sturzl, W., Vidal-Calleja, T., Triebel, R.: Gaussian process gradient maps for loop-closure detection in unstructured planetary environments. In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1895–1902 (2020)
Giubilato, R., Gentil, C.L., Vayugundla, M., Schuster, M.J., Vidal-Calleja, T., Triebel, R.: GPGM-SLAM: a robust slam system for unstructured planetary environments with gaussian process gradient maps. arXiv preprint arXiv:2109.06596 (2021)
Giubilato, R., Sturzl, W., Wedler, A., Triebel, R.: Challenges of slam in extremely unstructured environments: the DLR planetary stereo, solid-state lidar, inertial dataset. IEEE Robot. Autom. Lett. 7, 8721–8728 (2022)
Gong, Y., Huang, L., Chen, L.: Eliminate deviation with deviation for data augmentation and a general multi-modal data learning method. arXiv preprint arXiv:2101.08533 (2021)
Goodwill, J., et al.: NASA spacecube edge TPU smallsat card for autonomous operations and onboard science-data analysis. In: Small Satellite Conference (2021)
Gordo, A., Almazán, J., Revaud, J., Larlus, D.: Deep image retrieval: learning global representations for image search. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016, Part VI. LNCS, vol. 9910, pp. 241–257. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46466-4_15
Grill, J.B., et al.: Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural. Inf. Process. Syst. 33, 21271–21284 (2020)
Gu, G., Ko, B., Kim, H.G.: Proxy synthesis: learning with synthetic classes for deep metric learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 1460–1468 (2021)
Guzewich, S.D., et al.: Mars science laboratory observations of the 2018/mars year 34 global dust storm. Geophys. Res. Lett. 46(1), 71–79 (2019). https://doi.org/10.1029/2018GL080839
Habte, S.B., Ibenthal, A., Bekele, E.T., Debelee, T.G.: Convolution filter equivariance/invariance in convolutional neural networks: a survey. In: Girma Debelee, T., Ibenthal, A., Schwenker, F. (eds.) PanAfriCon AI 2022. CCIS, vol. 1800, pp. 191–205. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-31327-1_11
Hausler, S., Garg, S., Xu, M., Milford, M., Fischer, T.: Patch-NetVLAD: multi-scale fusion of locally-global descriptors for place recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14141–14152 (2021)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Henkel, C., Singer, P.: Supporting large-scale image recognition with out-of-domain samples. arXiv preprint arXiv:2010.01650 (2020)
Henriques, J.F., Vedaldi, A.: Warped convolutions: efficient invariance to spatial transformations. In: International Conference on Machine Learning, pp. 1461–1469. PMLR (2017)
Hou, Q., Zhou, D., Feng, J.: Coordinate attention for efficient mobile network design (2021)
Hu, J., Shen, L., Albanie, S., Sun, G., Wu, E.: Squeeze-and-excitation networks (2019)
Hutchinson, M.J., Le Lan, C., Zaidi, S., Dupont, E., Teh, Y.W., Kim, H.: LieTransformer: equivariant self-attention for lie groups. In: International Conference on Machine Learning, pp. 4533–4543. PMLR (2021)
Jiang, R., Mei, S.: Polar coordinate convolutional neural network: from rotation-invariance to translation-invariance. In: 2019 IEEE International Conference on Image Processing (ICIP), pp. 355–359. IEEE (2019)
Johnson, A.E., et al.: The lander vision system for mars 2020 entry descent and landing. In: AAS Guidance Navigation and Control Conference (2017)
Johnson, J., Douze, M., Jégou, H.: Billion-scale similarity search with GPUs. IEEE Trans. Big Data 7(3), 535–547 (2019)
Kang, J., Fernandez-Beltran, R., Wang, Z., Sun, X., Ni, J., Plaza, A.: Rotation-invariant deep embedding for remote sensing images. IEEE Trans. Geosci. Remote Sens. 60, 1–13 (2022). https://doi.org/10.1109/TGRS.2021.3088398
Keetha, N., et al.: AnyLoc: towards universal visual place recognition. IEEE Robot. Autom. Lett. 9, 1286–1293 (2023)
Kha Vu, C.: Deep metric learning: a (long) survey (2021). https://hav4ik.github.io/articles/deep-metric-learning-survey. Accessed 11 Nov 2023
Khosla, P., et al.: Supervised contrastive learning. Adv. Neural. Inf. Process. Syst. 33, 18661–18673 (2020)
Ki, M., Uh, Y., Choe, J., Byun, H.: Contrastive attention maps for self-supervised co-localization. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 2783–2792 (2021). https://doi.org/10.1109/ICCV48922.2021.00280
Kim, S., Kim, D., Cho, M., Kwak, S.: Proxy anchor loss for deep metric learning (2020)
Krause, J., Deng, J., Stark, M., Fei-Fei, L.: Collecting a large-scale dataset of fine-grained cars (2013)
Lauretta, D.S., et al.: Episodes of particle ejection from the surface of the active asteroid (101955) Bennu. Science 366(6470), eaay3544 (2019). https://doi.org/10.1126/science.aay3544. https://www.science.org/doi/abs/10.1126/science.aay3544
Lee, C.: Automated crater detection on mars using deep learning. Planet. Space Sci. 170, 16–28 (2019). https://doi.org/10.1016/j.pss.2019.03.008. https://www.sciencedirect.com/science/article/pii/S0032063318303945
Li, J., Yang, Z., Liu, H., Cai, D.: Deep rotation equivariant network. Neurocomputing 290, 26–33 (2018)
Li, S., Sun, L., Li, Q.: CLIP-ReID: exploiting vision-language model for image re-identification without concrete text labels. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, pp. 1405–1413 (2023)
Li, W., Zhou, B., Hsu, C.Y., Li, Y., Ren, F.: Recognizing terrain features on terrestrial surface using a deep learning model: an example with crater detection. In: Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery, GeoAI 2017, pp. 33–36. Association for Computing Machinery, New York (2017). https://doi.org/10.1145/3149808.3149814
Li, X., Larson, M., Hanjalic, A.: Pairwise geometric matching for large-scale object retrieval. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5153–5161 (2015)
Li, Y., Yang, M., Zhang, Z.: A survey of multi-view representation learning. IEEE Trans. Knowl. Data Eng. 31(10), 1863–1883 (2018)
Li, Z., et al.: Rethinking the optimization of average precision: only penalizing negative instances before positive ones is enough. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 1518–1526 (2022)
Liu, D., Zhao, L., Wang, Y., Kato, J.: Learn from each other to classify better: cross-layer mutual attention learning for fine-grained visual classification. Pattern Recogn. 140, 109550 (2023)
Liu, Y., Guo, Y., Wu, S., Lew, M.S.: DeepIndex for accurate and efficient image retrieval. In: Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, pp. 43–50 (2015)
Mo, H., Zhao, G.: RIC-CNN: rotation-invariant coordinate convolutional neural network. Pattern Recogn. 146, 109994 (2024)
Mohan, D.D., Sankaran, N., Fedorishin, D., Setlur, S., Govindaraju, V.: Moving in the right direction: a regularization for deep metric learning. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14579–14587 (2020). https://doi.org/10.1109/CVPR42600.2020.01460
Motyka, T.: Learned equivariance in convolutional neural networks (2022)
Muhammad, M.B., Yeasin, M.: Eigen-CAM: class activation map using principal components. In: 2020 International Joint Conference on Neural Networks (IJCNN), pp. 1–7. IEEE (2020)
Musgrave, K., Belongie, S.J., Lim, S.N.: Pytorch metric learning. ArXiv abs/2008.09164 (2020)
National Aeronautics and Space Administration, University of Arizona, Lockheed Martin: Osiris-rex operations timeline. https://www.asteroidmission.org/asteroid-operations/. Accessed 1 June 2023
Norman, C., et al.: Autonomous navigation performance using natural feature tracking during the OSIRIS-Rex touch-and-go sample collection event. Planet. Sci. J. 3(5), 101 (2022)
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018)
Oquab, M., et al.: DINOv2: learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
Ozaki, K., Yokoo, S.: Large-scale landmark retrieval/recognition under a noisy and diverse dataset. arXiv preprint arXiv:1906.04087 (2019)
Radenović, F., Tolias, G., Chum, O.: Fine-tuning CNN image retrieval with no human annotation. IEEE Trans. Pattern Anal. Mach. Intell. 41(7), 1655–1668 (2019). https://doi.org/10.1109/TPAMI.2018.2846566
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: unified, real-time object detection (2016)
Romero, D.W., Lohit, S.: Learning partial equivariances from data. Adv. Neural. Inf. Process. Syst. 35, 36466–36478 (2022)
Salvador, A., Giró-i Nieto, X., Marqués, F., Satoh, S.: Faster R-CNN features for instance search. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 9–16 (2016)
Shabanov, A., Tarasov, A., Nikolenko, S.: STIR: Siamese transformer for image retrieval postprocessing. arXiv preprint arXiv:2304.13393 (2023)
Silburt, A., et al.: Lunar crater identification via deep learning. Icarus 317, 27–38 (2019). https://doi.org/10.1016/j.icarus.2018.06.022. https://www.sciencedirect.com/science/article/pii/S0019103518301386
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Srivastava, S., Sharma, G.: OmniVec: learning robust representations with cross modal sharing. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 1236–1248 (2024)
Sun, S., Zhou, W., Tian, Q., Li, H.: Scalable object retrieval with compact image representation from generic object regions. ACM Trans. Multimedia Comput. Commun. Appl. (TOMM) 12(2), 1–21 (2015)
Sun, Y., et al.: Circle loss: a unified perspective of pair similarity optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6398–6407 (2020)
Tan, F., Yuan, J., Ordonez, V.: Instance-level image retrieval using reranking transformers. In: proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12105–12115 (2021)
Teh, E.W., DeVries, T., Taylor, G.W.: ProxyNCA++: revisiting and revitalizing proxy neighborhood component analysis. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020, Prt XXIV. LNCS, vol. 12369, pp. 448–464. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58586-0_27
The Planetary Society: Cost of OSIRIS-Rex. https://www.planetary.org/space-policy/cost-of-osiris-rex. Accessed 1 June 2023
Wang, G., Lai, J., Huang, P., Xie, X.: Spatial-temporal person re-identification. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 8933–8940 (2019)
Wang, Q., Lai, J., Yang, Z., Xu, K., Kan, P., Liu, W., Lei, L.: Improving cross-dimensional weighting pooling with multi-scale feature fusion for image retrieval. Neurocomputing 363, 17–26 (2019)
Wang, X., Han, X., Huang, W., Dong, D., Scott, M.R.: Multi-similarity loss with general pair weighting for deep metric learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5022–5030 (2019)
Wang, Y., Zhang, J., Kan, M., Shan, S., Chen, X.: Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12275–12284 (2020)
Wei, X.S.: Fine-grained image analysis with deep learning: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 44(12), 8927–8948 (2021)
Weiler, M., Cesa, G.: General E (2)-equivariant steerable CNNs. Adv. Neural Inf. Process. Syst. 32 (2019)
Welinder, P., et bal.: Caltech-UCSD birds 200. Technical report. CNS-TR-201, Caltech (2010). /se3/wp-content/uploads/2014/09/WelinderEtal10_CUB-200.pdf. http://www.vision.caltech.edu/visipedia/CUB-200.html
Weng, L.: Contrastive representation learning (2021). https://lilianweng.github.io/posts/2021-05-31-contrastive/#parallel-augmentation. Accessed 11 Nov 2023
Weyand, T., Araujo, A., Cao, B., Sim, J.: Google landmarks dataset V2-a large-scale benchmark for instance-level recognition and retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2575–2584 (2020)
Wilson, C., George, A.: CSP hybrid space computing. J. Aerosp. Inf. Syst. 15(4), 215–227 (2018)
Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: CBAM: convolutional block attention module (2018)
Wright, C.A., Eepoel, J.V., Liounis, A.J., Shoemaker, M.A., Deweese, K., Getzandanner, K.M.: Relative terrain imaging navigation (RETINA) tool for the asteroid redirect robotic mission (ARRM). In: AAS Guidance Navigation and Control Conference (2016)
Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks (2017)
Xu, Q., Wang, J., Jiang, B., Luo, B.: Fine-grained visual classification via internal ensemble learning transformer. IEEE Trans. Multimedia 25, 9015–9028 (2023)
Yang, F., Matei, B., Davis, L.S.: Re-ranking by multi-feature fusion with diffusion for image retrieval. In: 2015 IEEE Winter Conference on Applications of Computer Vision, pp. 572–579. IEEE (2015)
Yang, F., Li, J., Wei, S., Zheng, Q., Liu, T., Zhao, Y.: Two-stream attentive CNNs for image retrieval. In: Proceedings of the 25th ACM International Conference on Multimedia, pp. 1513–1521 (2017)
Yu, T., Wu, Y., Bhattacharjee, S., Yuan, J.: Efficient object instance search using fuzzy objects matching. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31 (2017)
Zbontar, J., Jing, L., Misra, I., LeCun, Y., Deny, S.: Barlow twins: self-supervised learning via redundancy reduction. In: International Conference on Machine Learning, pp. 12310–12320. PMLR (2021)
Zhang, X., Wang, L., Su, Y.: Visual place recognition: a survey from deep learning perspective. Pattern Recognit. 113, 107760 (2021). https://doi.org/10.1016/j.patcog.2020.107760. https://www.sciencedirect.com/science/article/pii/S003132032030563X
Zheng, L., Shen, L., Tian, L., Wang, S., Wang, J., Tian, Q.: Scalable person re-identification: a benchmark. In: IEEE International Conference on Computer Vision (2015)
Zheng, L., Yang, Y., Tian, Q.: Sift meets CNN: a decade survey of instance retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 40(5), 1224–1244 (2017)
Zheng, L., Zhao, Y., Wang, S., Wang, J., Tian, Q.: Good practice in CNN feature transfer. arXiv preprint arXiv:1604.00133 (2016)
Zhou, W., Li, H., Tian, Q.: Recent advance in content-based image retrieval: a literature survey. arXiv preprint arXiv:1706.06064 (2017)
Zhu, Z., et al.: Viewpoint-aware loss with angular regularization for person re-identification (2019)
Zitnick, C.L., Dollár, P.: Edge boxes: locating object proposals from edges. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014, Part V. LNCS, vol. 8693, pp. 391–405. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_26
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Chase, T., Dantu, K. (2025). MARs: Multi-view Attention Regularizations for Patch-Based Feature Recognition of Space Terrain. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds) Computer Vision – ECCV 2024. ECCV 2024. Lecture Notes in Computer Science, vol 15122. Springer, Cham. https://doi.org/10.1007/978-3-031-73039-9_13
Download citation
DOI: https://doi.org/10.1007/978-3-031-73039-9_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-73038-2
Online ISBN: 978-3-031-73039-9
eBook Packages: Computer ScienceComputer Science (R0)