
Abstract
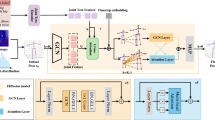
Reconstructing hand-held objects from a single RGB image is a challenging task in computer vision. In contrast to prior works that utilize deterministic modeling paradigms, we employ a point cloud denoising diffusion model to account for the probabilistic nature of this problem. In the core, we introduce centroid-fixed Dual-Stream Conditional diffusion for monocular hand-held object reconstruction (D-SCo), tackling two predominant challenges. First, to avoid the object centroid from deviating, we utilize a novel hand-constrained centroid fixing paradigm, enhancing the stability of diffusion and reverse processes and the precision of feature projection. Second, we introduce a dual-stream denoiser to semantically and geometrically model hand-object interactions with a novel unified hand-object semantic embedding, enhancing the reconstruction performance of the hand-occluded region of the object. Experiments on the synthetic ObMan dataset and three real-world datasets HO3D, MOW and DexYCB demonstrate that our approach can surpass all other state-of-the-art methods.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Boukhayma, A., Bem, R., Torr, P.H.: 3D hand shape and pose from images in the wild. In: CVPR, pp. 10843–10852 (2019)
Brahmbhatt, S., Tang, C., Twigg, C.D., Kemp, C.C., Hays, J.: ContactPose: a dataset of grasps with object contact and hand pose. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12358, pp. 361–378. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58601-0_22
Calli, B., Singh, A., Walsman, A., Srinivasa, S., Abbeel, P., Dollar, A.M.: The YCB object and model set: towards common benchmarks for manipulation research. In: 2015 International Conference on Advanced Robotics (ICAR), pp. 510–517. IEEE (2015)
Cao, Z., Radosavovic, I., Kanazawa, A., Malik, J.: Reconstructing hand-object interactions in the wild. In: ICCV, pp. 12417–12426 (2021)
Chang, A.X., et al.: ShapeNet: an information-rich 3D model repository. arXiv preprint arXiv:1512.03012 (2015)
Chao, Y.W., et al.: DexYCB: a benchmark for capturing hand grasping of objects. In: CVPR (2021)
Chen, Y., et al.: Joint hand-object 3d reconstruction from a single image with cross-branch feature fusion. IEEE TIP 30, 4008–4021 (2021)
Chen, Z., Chen, S., Schmid, C., Laptev, I.: gSDF: geometry-driven signed distance functions for 3D hand-object reconstruction. In: CVPR, pp. 12890–12900 (2023)
Chen, Z., Hasson, Y., Schmid, C., Laptev, I.: AlignSDF: pose-aligned signed distance fields for hand-object reconstruction. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision, ECCV 2022. LNCS, vol. 13661, pp. 231–248. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19769-7_14
Chen, Z., Zhang, H.: Learning implicit fields for generative shape modeling. In: CVPR, pp. 5939–5948 (2019)
Choe, J., Joung, B., Rameau, F., Park, J., Kweon, I.S.: Deep point cloud reconstruction. In: ICLR (2021)
Choy, C.B., Xu, D., Gwak, J.Y., Chen, K., Savarese, S.: 3D-R2N2: a unified approach for single and multi-view 3D object reconstruction. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 628–644. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_38
Corona, E., Pumarola, A., Alenya, G., Moreno-Noguer, F., Rogez, G.: GanHand: predicting human grasp affordances in multi-object scenes. In: CVPR, pp. 5031–5041 (2020)
Damen, D., et al.: The epic-kitchens dataset: collection, challenges and baselines. IEEE TPAMI 43(11), 4125–4141 (2021). https://doi.org/10.1109/TPAMI.2020.2991965
Damen, D., et al.: Scaling egocentric vision: the dataset. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11208, pp. 753–771. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01225-0_44
Di, Y., et al.: CCD-3DR: consistent conditioning in diffusion for single-image 3D reconstruction. arXiv preprint arXiv:2308.07837 (2023)
Doosti, B., Naha, S., Mirbagheri, M., Crandall, D.J.: HOPE-Net: a graph-based model for hand-object pose estimation. In: CVPR, pp. 6608–6617 (2020)
Dosovitskiy, A., et al.: An image is worth 16\(\times \)16 words: transformers for image recognition at scale. In: ICLR (2021)
Edelsbrunner, H., Kirkpatrick, D., Seidel, R.: On the shape of a set of points in the plane. IEEE Trans. Inf. Theor. 29(4), 551–559 (1983)
Edsinger, A., Kemp, C.C.: Human-robot interaction for cooperative manipulation: handing objects to one another. In: The 16th IEEE International Symposium on Robot and Human Interactive Communication, RO-MAN 2007, pp. 1167–1172. IEEE (2007)
Fan, H., Su, H., Guibas, L.J.: A point set generation network for 3D object reconstruction from a single image. In: CVPR, pp. 605–613 (2017)
Gao, H., Ji, S.: Graph U-Nets. In: ICML, pp. 2083–2092. PMLR (2019)
Gao, Q., Chen, Y., Ju, Z., Liang, Y.: Dynamic hand gesture recognition based on 3D hand pose estimation for human-robot interaction. IEEE Sens. J. 22(18), 17421–17430 (2021)
Girdhar, R., Fouhey, D.F., Rodriguez, M., Gupta, A.: Learning a predictable and generative vector representation for objects. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9910, pp. 484–499. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46466-4_29
Gkioxari, G., Malik, J., Johnson, J.: Mesh R-CNN. In: ICCV, pp. 9785–9795 (2019)
Grady, P., Tang, C., Twigg, C.D., Vo, M., Brahmbhatt, S., Kemp, C.C.: ContactOpt: optimizing contact to improve grasps. In: CVPR, pp. 1471–1481 (2021)
Groueix, T., Fisher, M., Kim, V.G., Russell, B.C., Aubry, M.: A papier-mâché approach to learning 3D surface generation. In: CVPR, pp. 216–224 (2018)
Hampali, S., Rad, M., Oberweger, M., Lepetit, V.: HOnnotate: a method for 3D annotation of hand and object poses. In: CVPR, pp. 3196–3206 (2020)
Hartley, R., Zisserman, A.: Multiple View Geometry in Computer Vision. Cambridge University Press (2003)
Hasson, Y., Tekin, B., Bogo, F., Laptev, I., Pollefeys, M., Schmid, C.: Leveraging photometric consistency over time for sparsely supervised hand-object reconstruction. In: CVPR, pp. 571–580 (2020)
Hasson, Y., et al.: Learning joint reconstruction of hands and manipulated objects. In: CVPR, pp. 11807–11816 (2019)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR, pp. 770–778 (2016)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS, vol. 33, pp. 6840–6851 (2020)
Iqbal, U., Molchanov, P., Breuel, T., Gall, J., Kautz, J.: Hand pose estimation via latent 2.5D heatmap regression. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11215, pp. 125–143. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01252-6_8
Kanazawa, A., Tulsiani, S., Efros, A.A., Malik, J.: Learning category-specific mesh reconstruction from image collections. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11219, pp. 386–402. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01267-0_23
Kar, A., Tulsiani, S., Carreira, J., Malik, J.: Category-specific object reconstruction from a single image. In: CVPR, pp. 1966–1974 (2015)
Karunratanakul, K., Yang, J., Zhang, Y., Black, M.J., Muandet, K., Tang, S.: Grasping field: learning implicit representations for human grasps. In: 3DV, pp. 333–344. IEEE (2020)
Leng, Z., Chen, J., Shum, H.P., Li, F.W., Liang, X.: Stable hand pose estimation under tremor via graph neural network. In: 2021 IEEE Virtual Reality and 3D User Interfaces (VR), pp. 226–234. IEEE (2021)
Lin, C.H., Kong, C., Lucey, S.: Learning efficient point cloud generation for dense 3D object reconstruction. In: AAAI, vol. 32 (2018)
Liu, S., Jiang, H., Xu, J., Liu, S., Wang, X.: Semi-supervised 3D hand-object poses estimation with interactions in time. In: CVPR, pp. 14687–14697 (2021)
Liu, Z., Tang, H., Lin, Y., Han, S.: Point-voxel CNN for efficient 3D deep learning. In: NeurIPS, vol. 32 (2019)
Luo, S., Hu, W.: Diffusion probabilistic models for 3D point cloud generation. In: CVPR, pp. 2837–2845 (2021)
Luo, S., Hu, W.: Diffusion probabilistic models for 3D point cloud generation. In: CVPR, June 2021, pp. 2837–2845 (2021)
Melas-Kyriazi, L., Rupprecht, C., Vedaldi, A.: PC\(^2\): projection-conditioned point cloud diffusion for single-image 3D reconstruction. In: CVPR, June 2023, pp. 12923–12932 ()
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: NeRF: representing scenes as neural radiance fields for view synthesis. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12346, pp. 405–421. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58452-8_24
Miller, A.T., Allen, P.K.: Graspit! a versatile simulator for robotic grasping. IEEE Robot. Autom. Mag. 11(4), 110–122 (2004)
Mueller, F., et al.: GANerated hands for real-time 3D hand tracking from monocular RGB. In: CVPR, pp. 49–59 (2018)
Mueller, F., et al.: Real-time pose and shape reconstruction of two interacting hands with a single depth camera. ACM TOG 38(4), 1–13 (2019)
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: ICML, pp. 8162–8171. PMLR (2021)
Ortenzi, V., Cosgun, A., Pardi, T., Chan, W.P., Croft, E., Kulić, D.: Object handovers: a review for robotics. IEEE Trans. Rob. 37(6), 1855–1873 (2021)
Panteleris, P., Oikonomidis, I., Argyros, A.: Using a single RGB frame for real time 3D hand pose estimation in the wild. In: WACV, pp. 436–445. IEEE (2018)
Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: DeepSDF: learning continuous signed distance functions for shape representation. In: CVPR, pp. 165–174 (2019)
Pham, T.H., Kyriazis, N., Argyros, A.A., Kheddar, A.: Hand-object contact force estimation from markerless visual tracking. IEEE TPAMI 40(12), 2883–2896 (2017)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: PointNet: deep learning on point sets for 3D classification and segmentation. In: CVPR, pp. 652–660 (2017)
Qian, X., He, F., Hu, X., Wang, T., Ramani, K.: ARnnotate: an augmented reality interface for collecting custom dataset of 3D hand-object interaction pose estimation. In: Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, pp. 1–14 (2022)
Rantamaa, H.R., Kangas, J., Kumar, S.K., Mehtonen, H., Järnstedt, J., Raisamo, R.: Comparison of a VR stylus with a controller, hand tracking, and a mouse for object manipulation and medical marking tasks in virtual reality. Appl. Sci. 13(4), 2251 (2023)
Ravi, N., et al.: Accelerating 3d deep learning with PyTorch3D. arXiv preprint arXiv:2007.08501 (2020)
Rogez, G., Khademi, M., Supančič III, J.S., Montiel, J.M.M., Ramanan, D.: 3D hand pose detection in egocentric RGB-D images. In: Agapito, L., Bronstein, M.M., Rother, C. (eds.) ECCV 2014. LNCS, vol. 8925, pp. 356–371. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-16178-5_25
Rogez, G., Supancic, J.S., Ramanan, D.: Understanding everyday hands in action from RGB-D images. In: ICCV, pp. 3889–3897 (2015)
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: modeling and capturing hands and bodies together. ACM TOG 36(6) (2017)
Rong, Y., Shiratori, T., Joo, H.: FrankMocap: a monocular 3D whole-body pose estimation system via regression and integration. In: ICCVW (2021)
Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: CVPR (2016)
Schönberger, J.L., Zheng, E., Frahm, J.-M., Pollefeys, M.: Pixelwise view selection for unstructured multi-view stereo. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9907, pp. 501–518. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46487-9_31
Seitz, S.M., Curless, B., Diebel, J., Scharstein, D., Szeliski, R.: A comparison and evaluation of multi-view stereo reconstruction algorithms. In: CVPR, vol. 1, pp. 519–528. IEEE (2006)
Shan, D., Geng, J., Shu, M., Fouhey, D.F.: Understanding human hands in contact at internet scale. In: CVPR, pp. 9869–9878 (2020)
Sridhar, S., Mueller, F., Oulasvirta, A., Theobalt, C.: Fast and robust hand tracking using detection-guided optimization. In: CVPR, pp. 3213–3221 (2015)
Sridhar, S., Mueller, F., Zollhöfer, M., Casas, D., Oulasvirta, A., Theobalt, C.: Real-time joint tracking of a hand manipulating an object from RGB-D input. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 294–310. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_19
Tatarchenko, M., Richter, S.R., Ranftl, R., Li, Z., Koltun, V., Brox, T.: What do single-view 3D reconstruction networks learn? In: CVPR, pp. 3405–3414 (2019)
Tekin, B., Bogo, F., Pollefeys, M.: H+O: unified egocentric recognition of 3D hand-object poses and interactions. In: CVPR, June 2019 (2019)
Tulsiani, S., Kar, A., Carreira, J., Malik, J.: Learning category-specific deformable 3D models for object reconstruction. IEEE TPAMI 39(4), 719–731 (2016)
Tzionas, D., Ballan, L., Srikantha, A., Aponte, P., Pollefeys, M., Gall, J.: Capturing hands in action using discriminative salient points and physics simulation. IJCV 118, 172–193 (2016). https://doi.org/10.1007/s11263-016-0895-4
Tzionas, D., Gall, J.: 3D object reconstruction from hand-object interactions. In: ICCV, pp. 729–737 (2015)
Wu, J., Zhang, C., Xue, T., Freeman, B., Tenenbaum, J.: Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In: NeurIPS, vol. 29 (2016)
Xie, H., Yao, H., Sun, X., Zhou, S., Zhang, S.: Pix2Vox: context-aware 3D reconstruction from single and multi-view images. In: ICCV, pp. 2690–2698 (2019)
Xie, H., Yao, H., Zhang, S., Zhou, S., Sun, W.: Pix2Vox++: multi-scale context-aware 3D object reconstruction from single and multiple images. IJCV 128(12), 2919–2935 (2020). https://doi.org/10.1007/s11263-020-01347-6
Yang, L., et al.: ArtiBoost: boosting articulated 3D hand-object pose estimation via online exploration and synthesis. In: CVPR, pp. 2750–2760 (2022)
Yang, L., Zhan, X., Li, K., Xu, W., Li, J., Lu, C.: CPF: learning a contact potential field to model the hand-object interaction. In: ICCV, pp. 11097–11106 (2021)
Ye, Y., Gupta, A., Tulsiani, S.: What’s in your hands? 3D reconstruction of generic objects in hands. In: CVPR, June 2022, pp. 3895–3905 (2022)
Zeng, X., et al.: LION: latent point diffusion models for 3D shape generation. In: NeurIPS (2022)
Zhang, C., et al.: DDF-HO: hand-held object reconstruction via conditional directed distance field. In: NeurIPS, vol. 36 (2024)
Zhang, C., et al.: MOHO: learning single-view hand-held object reconstruction with multi-view occlusion-aware supervision. arXiv preprint arXiv:2310.11696 (2024)
Zhang, X., Li, Q., Mo, H., Zhang, W., Zheng, W.: End-to-end hand mesh recovery from a monocular RGB image. In: ICCV, pp. 2354–2364 (2019)
Zhou, L., Du, Y., Wu, J.: 3D shape generation and completion through point-voxel diffusion. In: ICCV, October 2021, pp. 5826–5835 (2021)
Zhou, Q.Y., Park, J., Koltun, V.: Open3D: a modern library for 3D data processing. arXiv preprint arXiv:1801.09847 (2018)
Zhou, Y., Habermann, M., Xu, W., Habibie, I., Theobalt, C., Xu, F.: Monocular real-time hand shape and motion capture using multi-modal data. In: CVPR, pp. 5346–5355 (2020)
Zimmermann, C., Brox, T.: Learning to estimate 3d hand pose from single RGB images. In: ICCV, pp. 4903–4911 (2017)
Acknowledgements
This work was supported in part by the China Scholarship Council and in part by the Shuimu-Zhiyuan Tsinghua Scholar Program.
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Fu, B. et al. (2025). D-SCo: Dual-Stream Conditional Diffusion for Monocular Hand-Held Object Reconstruction. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds) Computer Vision – ECCV 2024. ECCV 2024. Lecture Notes in Computer Science, vol 15087. Springer, Cham. https://doi.org/10.1007/978-3-031-73397-0_22
Download citation
DOI: https://doi.org/10.1007/978-3-031-73397-0_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-73396-3
Online ISBN: 978-3-031-73397-0
eBook Packages: Computer ScienceComputer Science (R0)