
Abstract
We investigate Nash equilibrium learning in a competitive Markov Game (MG) environment, where multiple agents compete, and multiple Nash equilibria can exist. In particular, for an oligopolistic dynamic pricing environment, exact Nash equilibria are difficult to obtain due to the curse-of-dimensionality. We develop a new model-free method to find approximate Nash equilibria. Gradient-free black box optimization is then applied to estimate \(\epsilon \), the maximum reward advantage of an agent unilaterally deviating from any joint policy, and to also estimate the \(\epsilon \)-minimizing policy for any given state. The policy-\(\epsilon \) correspondence and the state to \(\epsilon \)-minimizing policy are represented by neural networks, the latter being the Nash Policy Net. During batch update, we perform Nash Q learning on the system, by adjusting the action probabilities using the Nash Policy Net. We demonstrate that an approximate Nash equilibrium can be learned, particularly in the dynamic pricing domain where exact solutions are often intractable.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

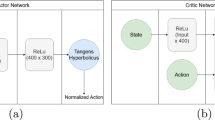
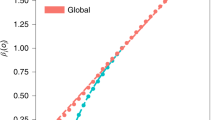
References
Briesch, R.A., et al.: A comparative analysis of reference price models. J. Cons. Res. 24(2), 202–214 (1997)
Ceppi, S., et al.: Local Search Methods for Finding a Nash Equi-librium in Two-Player Games, pp. 335–342 (2010). https://doi.org/10.1109/WI-IAT.2010.57
Daskalakis, C., Goldberg, P.W., Pa-padimitriou, C.H.: The Complexity of Computing a Nash Equilibrium . In: Proceedings of the Thirty-Eighth Annual ACM Symposium on Theory of Computing, STOC 2006, pp. 71–78. Association for Computing Machinery, Seattle, WA, USA (2006). https://doi.org/10.1145/1132516.1132527, isbn: 1595931341
Diouane, Y., et al.: TREGO: a Trust-Region Framework for Efficient Global Optimization. arXiv: org/abs/2101.06808 (2021)
Eriksson, D., et al.: Scalable Global Optimization via Local Bayesian Optimization. arXiv: 1910.01739 (2019)
Ferreira, K.J., Alex Lee, B.H., Simchi-Levi, D.: Analytics for an online retailer: Demand forecasting and price optimization. Manufact. Serv. Operations Manag. 18(1), 69–88 (2016)
Goeree, J.K., Holt, C.A., Palfrey, T/R.: Stochastic game theory for social science: a primer on quantal response equilibrium. Cheltenham. Edward Elgar Publishing, UK (2020). https://www.elgaronline.com/view/edcoll/9781785363320/9781785363320.xml, isbn: 9781785363320
Michael Harrison, J., Bora Keskin, N., Zeevi, A.: Bayesian dynamic pricing policies: learning and earning under a binary prior distribution. Manag. Sci. 58(3), 570–586 (2012)
Junling, H., Wellman, M.P.: Nash Q-Learning for General-Sum Stochastic Games. J. Mach. Learn. Res. 4, 1039–1069 (2003), issn: 1532-4435
Janiszewski, C., Lichtenstein, D.R.: A range theory ac-count of price perception. J. Consumer Res. 25(4), 353–368 (1999)
Liu, J., et al.: Dynamic Pricing on E-commerce Platform with Deep Reinforcement Learning arXiv: 1912.02572 (2019)
Liu, L.: Approximate Nash Equilibrium Learning for n-Player Markov Games in Dynamic Pricing . arXiv preprint arXiv: 2207.06492 (2022)
Jue, Liu., Zhan, Pang., Linggang, Qi.: Dynamic pricing and in-ventory management with demand learning: a bayesian approach. Comput. Operations Re. 124, 105078 (2020). https://doi.org/10.1016/j.cor.2020.105078
Duncan Luce, R.: Individual Choice Behavior: A Theoretical Analysis. Wiley, New York, NY, USA (1959)
Mnih, V., et al.: Human-level control through deep reinforcement learning . Nature 518(7540), 529–533 ( 2015), issn: 00280836
Nash, J.F.: Equilibrium points in n-person games. Proc. Nat. Acad. Sci. 36(1), 48–49 (1950). https://doi.org/10.1073/pnas.36.1.48. https://www.pnas.org/content/36/1/48issn: 0027-8424
Porter, R., Nudelman, E., Shoham, Y.: Simple search methods for finding a Nash equilibrium. Games Econ. Behav. 63(2), 642–662 (2008). Second World Congress of the Game Theory Society
Ramponi, G., et al.: Learning in non-cooperative configurable markov decision processes . In: Beygelzimer, A., et al. (ed.) Advances in Neural Information Processing Systems (2021). https://openreview.net/forum?id=t-0eCf8L4-a
Rao, V.R.: Pricing models in marketing. Handbooks Operat. Res. Manag. Sci. 5, 517–552 (1993)
Raman, K., Bass, F.M., et al.: A general test of reference price theory in the presence of threshold effects. In: Tijdschrift voor Economie en management 47(2), 205–226 (2002)
Regis, R.G.: Trust regions in Kriging-based optimization with expected improvement. Eng. Optimiz. 48(6), 1037–1059 (2016). https://doi.org/10.1080/0305215X.2015.1082350
Sayin, M.O., et al.: Decentralized Q-Learning in Zero-sum Markov Games, arXiv: 2106.02748 (2021)
Thompson, W.R.: On the likelihood that one unknown prob-ability exceeds another in view of evidence of two samples. Biometrika 25(3–4), 285–294 (1933). https://doi.org/10.1093/biomet/25.3-4.285. https://academic.oup.com/biomet/article-pdf/25/3-4/285/513725/25-3-4-285.pdf
Taudes, A., Rudloff, C.: Integrating inventory control and a price change in the presence of reference price effects: a two-period model. Mathem. Methods Operat. Res. 75(1), 29–65 (2012)
Christopher, J.C.H.: Watkins and Peter Dayan Q-learning. Mach. Learn. 8(3), 279–292 (1992). https://doi.org/10.1007/BF00992698
Wang, L., Fonseca, R., Tian, Y.: Learning Search Space Partition for Black-box Optimization using Monte Carlo Tree Search, arXiv: 2007.00708 (2020)
Wang, X., Sandholm, T.: Reinforcement learning to play an optimal nash equilibrium in team markov games . In: Becker, S., Thrun, S., Obermayer, K. (eds.) Advances in Neural Information Processing Systems. Ed. by . Vol. 15. MIT Press (2003). https://proceedings.neurips.cc/paper/2002/file/f8e59f4b2fe7c5705bf878bbd494ccdf-Paper.pdf
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Liu, L. (2025). Approximate Nash Equilibrium Learning for n-Player Markov Games in Dynamic Pricing. In: Santos, M.F., Machado, J., Novais, P., Cortez, P., Moreira, P.M. (eds) Progress in Artificial Intelligence. EPIA 2024. Lecture Notes in Computer Science(), vol 14967. Springer, Cham. https://doi.org/10.1007/978-3-031-73497-7_29
Download citation
DOI: https://doi.org/10.1007/978-3-031-73497-7_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-73496-0
Online ISBN: 978-3-031-73497-7
eBook Packages: Computer ScienceComputer Science (R0)