
Abstract
Large Language Model (LLM) Artificial Intelligence (AI) systems have generated significant enthusiasm in the computer science research community for their potential in various computer language processing tasks, such as source code generation and source-to-source translation. We are particularly interested in using LLMs for automated theorem proving, specifically for proof repair. To this end, we introduce CoqDog Copilot, which leverages the neuro-symbolic interplay between generative AI and the Coq theorem prover to form a productive “generate-and-test” loop, incrementally improving proofs based on failure information and human hints until valid proofs are achieved. Our research introduces innovative solutions to critical challenges in developing CoqDog Copilot, including addressing context limitations, enhancing the soundness of recommendation systems, defining effective metrics for measuring proof repair progress, and designing a statistically robust evaluation system for conversational quality assessment. We present a comprehensive evaluation of CoqDog Copilot’s performance in proof repair across multiple samples from the Copland Coq proofbase, which consists of a total of 21,000 lines of Coq code. We have attained in excess of 60% accuracy for proof generation using GPT-4 in one ‘shot’, with approximately 30% more lemmas proved given one additional user prompt (yielding 90% correctness overall). With three ‘shots’, the overall proof correctness rate increases to 97%. We can generate Coq proofs with up to 50 proof steps using this technique. Our LLM-generated proofbase currently consists of over 1,400 lines of Copland Coq source.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
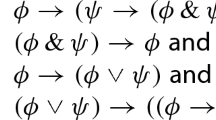


Notes
- 1.
Tables for the other clusters are provided in Appendix A.
References
Amundson, I., Cofer, D.: Resolute assurance arguments for cyber assured systems engineering. In: Design Automation for Cyber-Physical Systems and Internet of Things (DESTION 2021), May 2021
Belt, J., et al.: Model-driven development for the seL4 microkernel using the HAMR framework. J. Syst. Architect. 134, 102789 (2023). https://doi.org/10.1016/j.sysarc.2022.102789. https://www.sciencedirect.com/science/article/pii/S1383762122002740
Chowdhery, A., et al.: PaLM: Scaling language modeling with pathways (2022). https://arxiv.org/pdf/2204.02311.pdf
Cofer, D., et al.: Cyber assured systems engineering at scale. In: IEEE Security & Privacy, pp. 52–64, May/June 2022. https://doi.org/10.1109/MSEC.2022.3151733
Coker, G., et al.: Principles of remote attestation. Int. J. Inf. Secur. 10(2), 63–81 (2011)
First, E., Rabe, M.N., Ringer, T., Brun, Y.: Baldur: Whole-proof generation and repair with large language models (2023). https://arxiv.org/pdf/2303.04910.pdf
Haldar, V., Chandra, D., Franz, M.: Semantic remote attestation – a virtual machine directed approach to trusted computing. In: Proceedings of the Third Virtual Machine Research and Technology Symposium. San Jose, CA, May 2004
Leino, K.R.M.: Developing verified programs with Dafny. In: Proceedings of the 2013 International Conference on Software Engineering. pp. 1488–1490. ICSE ’13, IEEE Press, Piscataway, NJ, USA (2013), http://dl.acm.org/citation.cfm?id=2486788.2487050
Lewkowycz, A., et al.: Solving quantitative reasoning problems with language models (2022). https://arxiv.org/pdf/2206.14858.pdf
Megill, N., Wheeler, D.A.: Metamath: A computer language for mathematical proofs (2019), https://us.metamath.org/downloads/metamath.pdf
OpenAI: Evaluation templates (2023). https://github.com/openai/evals/blob/main/docs/eval-templates.md. Accessed 9 Dec 2023
OpenAI: GPT-4 Technical Report (2023), https://arxiv.org/pdf/2303.08774.pdf
OpenAI: Legacy fine-tuning guide (2023). https://platform.openai.com/docs/guides/legacy-fine-tuning. Accessed 9 Dec 2023
OpenAI: Prompt engineering strategies (2023). https://platform.openai.com/docs/guides/prompt-engineering/strategy-use-external-tools. Accessed 9 Dec 2023
Pearce, H., Ahmad, B., Tan, B., Dolan-Gavitt, B., Karri, R.: Asleep at the keyboard? assessing the security of GitHub Copilot’s code contributions. In: 2022 IEEE Symposium on Security and Privacy, pp. 754–768 (2022). https://doi.org/10.1109/SP46214.2022.9833571
Pei, K., Bieber, D., Shi, K., Sutton, C., Yin, P.: Can large language models reason about program invariants? In: Krause, A., Brunskill, E., Cho, K., Englehardt, B., Sabato, S., Scarlett, J. (eds.) Proceedings of the 40th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 202, pp. 27496–27520. PMLR, July 2023. https://proceedings.mlr.press/v202/pei23a/pei23a.html
Pendergrass, J.A., Helble, S., Clemens, J., Loscocco, P.: Maat: a platform service for measurement and attestation. arXiv preprint arXiv:1709.10147 (2017)
Perry, N., Srivastava, M., Kumar, D., Boneh, D.: Do users write more insecure code with AI assistants? (2022). https://arxiv.org/pdf/2211.03622.pdf
Petz, A., Alexander, P.: An Infrastructure for Faithful Execution of Remote Attestation Protocols. Innovations in Systems and Software Engineering (2022)
Petz, A., Alexander, P.: An infrastructure for faithful execution of remote attestation protocols. In: Proceedings of the 13th NASA Formal Methods Symposium (NFM 2021) (May 2021)
Petz, A., Jurgensen, G., Alexander, P.: Design and formal verification of a Copland-based attestation protocol. In: ACM/IEEE International Conference on Formal Methods and Models for System Design (MEMOCODE 2021), November 2021
Polu, S., Sutskever, I.: Generative language modeling for automated theorem proving (2020). https://arxiv.org/pdf/2009.03393.pdf
Ramsdell, J., et al.: Orchestrating layered attestations. In: Principles of Security and Trust (POST’19). Prague, Czech Republic (April 8-11 2019)
Rowe, P.D.: Bundling evidence for layered attestation. In: Trust and Trustworthy Computing, pp. 119–139. Springer, Cham (2016)
Sun, C., Sheng, Y., Padon, O., Barrett, C.: Clover: closed-loop verifiable code generation (2024). https://arxiv.org/pdf/2310.17807.pdf
Trusted Computing Group: TCG TPM Specification. Trusted Computing Group, 3885 SW 153rd Drive, Beaverton, OR 97006, version 1.2 revision 103 edn., July 2007. https://www.trustedcomputinggroup.org/resources/tpm_main_specification/
Wu, H., Barrett, C., Narodytska, N.: Lemur: Integrating large language models in automated program verification (2023). https://arxiv.org/pdf/2310.04870.pdf
Zhang, S.D., First, E., Ringer, T.: Getting more out of large language models for proofs (2023). https://arxiv.org/pdf/2305.04369.pdf
Acknowledgments
This work was funded by DARPA contract HR00111890001. The views, opinions and/or findings expressed are those of the authors and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
A CQAS Metrics Tables, Statistical Evaluations, and Visualizations
A CQAS Metrics Tables, Statistical Evaluations, and Visualizations

The figure shows an example of CQAS combined quality assessment for three clusters.

CQAS quality assessment measures of central tendency at the sample space level.

The bottom left corner shows that CoqDog can generate tactics on the fly based on Chain-of-Thought conversational pattern detection with the user.
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Tahat, A., Hardin, D., Petz, A., Alexander, P. (2025). Proof Repair Utilizing Large Language Models: A Case Study on the Copland Remote Attestation Proofbase. In: Steffen, B. (eds) Bridging the Gap Between AI and Reality. AISoLA 2024. Lecture Notes in Computer Science, vol 15217. Springer, Cham. https://doi.org/10.1007/978-3-031-75434-0_10
Download citation
DOI: https://doi.org/10.1007/978-3-031-75434-0_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-75433-3
Online ISBN: 978-3-031-75434-0
eBook Packages: Computer ScienceComputer Science (R0)