
Abstract
With the rapid advancement of generative AI, multimodal deepfakes, which manipulate both audio and visual modalities, have drawn increasing public concern. Currently, deepfake detection has emerged as a crucial strategy in countering these growing threats. However, as a key factor in training and validating deepfake detectors, most existing deepfake datasets primarily focus on the visual modal, and the few that are multimodal employ outdated techniques, and their audio content is limited to a single language, thereby failing to represent the cutting-edge advancements and globalization trends in current deepfake technologies. To address this gap, we propose a novel, multilingual, and multimodal deepfake dataset: PolyGlotFake. It includes content in seven languages, created using a variety of cutting-edge and popular Text-to-Speech, voice cloning, and lip-sync technologies. We conduct comprehensive experiments using state-of-the-art detection methods on PolyGlotFake dataset. These experiments demonstrate the dataset’s significant challenges and its practical value in advancing research into multimodal deepfake detection. PolyGlotFake dataset and its associated code are publicly available at: https://github.com/tobuta/PolyGlotFake.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
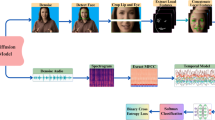

References
Deepswap - ai-powered DeepFake technology (2023). https://www.deepswap.net/. Accessed 24 Dec 2023
Afchar, D., Nozick, V., Yamagishi, J., Echizen, I.: MesoNet: a compact facial video forgery detection network. In: 2018 IEEE International Workshop on Information Forensics and Security (WIFS), pp. 1–7. IEEE (2018)
AI, C.: Github repository for coqui AI text-to-speech (2023). https://github.com/coqui-ai/tts. Accessed 29 Dec 2023
AI, R.: Rask AI official website (2023). https://zh.rask.ai/. Accessed 29 Dec 2023
AI, S.: Github repository for suno ai’s bark project (2023). https://github.com/suno-ai/bark. Accessed 29 Dec 2023
Cao, J., Ma, C., Yao, T., Chen, S., Ding, S., Yang, X.: End-to-end reconstruction-classification learning for face forgery detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4113–4122 (2022)
Cheng, K., et al.: Videoretalking: audio-based lip synchronization for talking head video editing in the wild. In: SIGGRAPH Asia 2022 Conference Papers, pp. 1–9 (2022)
Chung, J.S., Nagrani, A., Zisserman, A.: Voxceleb2: deep speaker recognition. arXiv preprint arXiv:1806.05622 (2018)
Coccomini, D.A., Messina, N., Gennaro, C., Falchi, F.: Combining efficientNet and vision transformers for video DeepFake detection. In: Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F. (eds.) ICIAP 2022. LNCS, vol. 13233, pp. 219–229. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-06433-3_19
Dang, H., Liu, F., Stehouwer, J., Liu, X., Jain, A.K.: On the detection of digital face manipulation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5781–5790 (2020)
Dolhansky, B., et al.: The DeepFake detection challenge (DFDC) dataset. arXiv preprint arXiv:2006.07397 (2020)
Dong, S., Wang, J., Ji, R., Liang, J., Fan, H., Ge, Z.: Implicit identity leakage: the stumbling block to improving DeepFake detection generalization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3994–4004 (2023)
Heygen: Heygen official website (2023). https://www.heygen.com/. Accessed 29 Dec 2023
Hou, Y., Guo, Q., Huang, Y., Xie, X., Ma, L., Zhao, J.: Evading DeepFake detectors via adversarial statistical consistency. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12271–12280 (2023)
Jemine, C.: Real-time-voice-cloning. University of Liége, Liége, Belgium p. 3 (2019)
Jia, S., Ma, C., Yao, T., Yin, B., Ding, S., Yang, X.: Exploring frequency adversarial attacks for face forgery detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4103–4112 (2022)
Jiang, L., Li, R., Wu, W., Qian, C., Loy, C.C.: Deeperforensics-1.0: a large-scale dataset for real-world face forgery detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2889–2898 (2020)
Juefei-Xu, F., Wang, R., Huang, Y., Guo, Q., Ma, L., Liu, Y.: Countering malicious DeepFake: survey, battleground, and horizon. Int. J. Comput. Vision 130(7), 1678–1734 (2022)
Khalid, H., Kim, M., Tariq, S., Woo, S.S.: Evaluation of an audio-video multimodal deepfake dataset using unimodal and multimodal detectors. In: Proceedings of the 1st Workshop on Synthetic Multimedia-audiovisual DeepFake Generation and Detection, pp. 7–15 (2021)
Khalid, H., Tariq, S., Kim, M., Woo, S.S.: Fakeavceleb: a novel audio-video multimodal deepfake dataset. arXiv preprint arXiv:2108.05080 (2021)
Korshunov, P., Marcel, S.: DeepFakes: a new threat to face recognition? assessment and detection. arXiv preprint arXiv:1812.08685 (2018)
Kwon, P., You, J., Nam, G., Park, S., Chae, G.: Kodf: a large-scale Korean DeepFake detection dataset. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10744–10753 (2021)
Li, J., Tu, W., Xiao, L.: Freevc: towards high-quality text-free one-shot voice conversion. In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE (2023)
Li, Y., Lyu, S.: Exposing DeepFake videos by detecting face warping artifacts. arXiv preprint arXiv:1811.00656 (2018)
Li, Y., Yang, X., Sun, P., Qi, H., Lyu, S.: Celeb-DF: a large-scale challenging dataset for DeepFake forensics. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3207–3216 (2020)
Liz-López, H., Keita, M., Taleb-Ahmed, A., Hadid, A., Huertas-Tato, J., Camacho, D.: Generation and detection of manipulated multimodal audiovisual content: advances, trends and open challenges. Inf. Fusion 103, 102103 (2024)
Lu, S.: faceswap-GAN: A GAN-based faceswap project on github (2023). https://github.com/shaoanlu/faceswap-GAN. Accessed 24 Dec 2023
Luo, Y., Zhang, Y., Yan, J., Liu, W.: Generalizing face forgery detection with high-frequency features. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16317–16326 (2021)
Microsoft: Microsoft azure text-to-speech services (2023). https://azure.microsoft.com/en-us/products/ai-services/text-to-speech. Accessed 29 Dec 2023
Mittag, G., Naderi, B., Chehadi, A., Möller, S.: Nisqa: a deep CNN-self-attention model for multidimensional speech quality prediction with crowdsourced datasets. arXiv preprint arXiv:2104.09494 (2021)
Mittal, A., Moorthy, A.K., Bovik, A.C.: No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 21(12), 4695–4708 (2012)
Narayan, K., Agarwal, H., Thakral, K., Mittal, S., Vatsa, M., Singh, R.: DF-platter: Multi-face heterogeneous DeepFake dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9739–9748 (2023)
Neekhara, P., Dolhansky, B., Bitton, J., Ferrer, C.C.: Adversarial threats to DeepFake detection: a practical perspective. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 923–932 (2021)
Nguyen, H.H., Yamagishi, J., Echizen, I.: Use of a capsule network to detect fake images and videos. arXiv preprint arXiv:1910.12467 (2019)
Ni, Y., Meng, D., Yu, C., Quan, C., Ren, D., Zhao, Y.: Core: consistent representation learning for face forgery detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12–21 (2022)
OpenAI: Github repository for openai whisper project (2023). https://github.com/openai/whisper. Accessed 29 Dec 2023
Polyak, A., Wolf, L., Taigman, Y.: Tts skins: speaker conversion via asr. arXiv preprint arXiv:1904.08983 (2019)
Prajwal, K., Mukhopadhyay, R., Namboodiri, V.P., Jawahar, C.: A lip sync expert is all you need for speech to lip generation in the wild. In: Proceedings of the 28th ACM International Conference on Multimedia, pp. 484–492 (2020)
Qian, Y., Yin, G., Sheng, L., Chen, Z., Shao, J.: Thinking in frequency: face forgery detection by mining frequency-aware clues. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12357, pp. 86–103. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58610-2_6
Rössler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.: Faceforensics: a large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:1803.09179 (2018)
Tan, M., Le, Q.: EfficientNet: rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning, pp. 6105–6114. PMLR (2019)
Wang, C., et al.: Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111 (2023)
Wang, J., et al.: M2tr: multi-modal multi-scale transformers for DeepFake detection. In: Proceedings of the 2022 International Conference on Multimedia Retrieval, pp. 615–623 (2022)
Wang, Y., et al.: Tacotron: towards end-to-end speech synthesis. arXiv preprint arXiv:1703.10135 (2017)
Xu, Y., Liang, J., Jia, G., Yang, Z., Zhang, Y., He, R.: Tall: thumbnail layout for DeepFake video detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 22658–22668 (2023)
Yang, X., Li, Y., Lyu, S.: Exposing deep fakes using inconsistent head poses. In: ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 8261–8265. IEEE (2019)
Zhou, T., Wang, W., Liang, Z., Shen, J.: Face forensics in the wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5778–5788 (2021)
Acknowledgements
This work was supported by JST SPRING, Grant Number JPMJSP2136.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Ethics declarations
Ethics Statement
Access to the dataset is restricted to academic institutions and is intended solely for research use. It complies with YouTube’s fair use policy through its transformative, non-commercial use, by including only brief excerpts (approximately 20 s) from each YouTube video, and ensuring that these excerpts do not adversely affect the copyright owners’ ability to earn revenue from their original content. Should any copyright owner feel their rights have been infringed, we are committed to promptly removing the contested material from our dataset.
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Hou, Y., Fu, H., Chen, C., Li, Z., Zhang, H., Zhao, J. (2025). PolyGlotFake: A Novel Multilingual and Multimodal DeepFake Dataset. In: Antonacopoulos, A., Chaudhuri, S., Chellappa, R., Liu, CL., Bhattacharya, S., Pal, U. (eds) Pattern Recognition. ICPR 2024. Lecture Notes in Computer Science, vol 15314. Springer, Cham. https://doi.org/10.1007/978-3-031-78341-8_12
Download citation
DOI: https://doi.org/10.1007/978-3-031-78341-8_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-78340-1
Online ISBN: 978-3-031-78341-8
eBook Packages: Computer ScienceComputer Science (R0)
