
Abstract
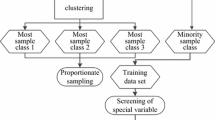
Credit client scoring on medium sized data sets can be accomplished by means of Support Vector Machines (SVM), a powerful and robust machine learning method. However, real life credit client data sets are usually huge, containing up to hundred thousands of records, with good credit clients vastly outnumbering the defaulting ones. Such data pose severe computational barriers for SVM and other kernel methods, especially if all pairwise data point similarities are requested. Hence, methods which avoid extensive training on the complete data are in high demand. A possible solution may be a combined cluster and classification approach. Computationally efficient clustering can compress information from the large data set in a robust way, especially in conjunction with a symbolic cluster representation. Credit client data clustered with this procedure will be used in order to estimate classification models.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Billard, L., & Diday, E. (2006). Symbolic data analysis. New York: Wiley.
Bock, H. -H., & Diday, E. (2000). Analysis of symbolic data: exploratory methods for extracting statistical information from complex data. Berlin: Springer.
Evgeniou, T., & Pontil, M. (2002). Support vector machines with clustering for training with very large datasets. Lectures Notes in Artificial Intelligence, 2308, 346–354.
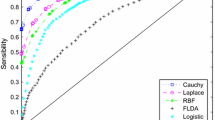
Hanley, A., & McNeil, B. (1982). The meaning and use of the area under a receiver operating characteristics (ROC) curve. Diagnostic Radiology, 143, 29–36.
Japkowicz, N. (2002). Supervised learning with unsupervised output separation. In Proceedings of the 6th International Conference on Artificial Intelligence and Soft Computing (pp. 321–325).
Li, B., Chi, M., Fan, J., & Xue, X. (2007). Support cluster machine. In Proceedings of the 24th international conference on machine learning (pp. 505–512).
MacQueen, J. B. (1967). Some methods for classification and analysis of multivariate observations. In Proceedings of the fifth symposium on math, statistics and probability (pp. 281–297).
Schölkopf, B., & Smola, A. (2002). Learning with kernels. Cambridge: MIT Press.
Shih, L., Rennie, J. D. M., Chang, Y. H., & Karger, D. R. (2003). Text bundling: Statistics-based data reduction. In Twentieth international conference on machine learning (pp. 696–703).
Wang, Y., Zhang, X., Wang, S., & Lai, K. K. (2008). Nonlinear clustering–based support vector machine for large data sets. Optimization Methods & Software – Mathematical Programming in Data Mining and Machine Learning, 23(4), 533–549.
Weiss, G. M. (2004). Mining with rarity: A unifying framework. SIGKDD Explorations, 6(1), 7–19.
Yu, H., Yang, J., & Han, J. (2003). Classifying large data sets using SVM with hierarchical clusters. In Ninth ACM SIGKDD international conference on knowledge discovery and data mining (pp. 306–315).
Yuan, J., Li, J., & Zhang, B. (2006). Learning concepts from large scale imbalanced data sets using support cluster machines. In Proceedings of the ACM international conference on multimedia (pp. 441–450).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer International Publishing Switzerland
About this paper
Cite this paper
Stecking, R., Schebesch, K.B. (2013). Symbolic Cluster Representations for SVM in Credit Client Classification Tasks. In: Giudici, P., Ingrassia, S., Vichi, M. (eds) Statistical Models for Data Analysis. Studies in Classification, Data Analysis, and Knowledge Organization. Springer, Heidelberg. https://doi.org/10.1007/978-3-319-00032-9_40
Download citation
DOI: https://doi.org/10.1007/978-3-319-00032-9_40
Published:
Publisher Name: Springer, Heidelberg
Print ISBN: 978-3-319-00031-2
Online ISBN: 978-3-319-00032-9
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)