
Abstract
The sparse matrix-vector (SpMV) multiplication is one of the key kernels in scientific computing. We present the foundations of its implementation on CUDA- and OpenCL-enabled devices. After introducing the subject, we briefly present three most popular formats: COO, CRS and ELL. They serve as exemplary data structures on which we discuss hardware-related issues associated with efficient SpMV kernel design, such as matrix size, ordering of data, memory boundedness, storage overhead, thread divergence, and coalescence of memory transfers. Next, we present three widely available libraries with stable and validated SpMV kernels: cuSPARSE, CUSP and Paralution. We present and discuss complete codes of several SpMV kernels for both basic SpMV formats and some of its derivatives, including CMRS, and briefly discuss the principles beyond other popular format extensions.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

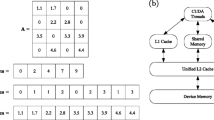
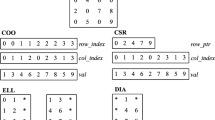
References
Bell, N., Garland, M.: Implementing sparse matrix-vector multiplication on throughput-oriented processors. In: SC’09: Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis, pp. 1–11. ACM, New York (2009). doi:http://doi.acm.org/10.1145/1654059.1654078
Choi, J.W., Singh, A., Vuduc, R.W.: Model-driven autotuning of sparse matrix-vector multiply on GPUs. SIGPLAN Not. 45(5), 115–126 (2010). http://doi.acm.org/10.1145/1837853.1693471
Dziekonski, A., Lamecki, A., Mrozowski, M.: A memory efficient and fast sparse matrix vector product on a GPU. Prog. Electromagn. Res. 116, 49–63 (2011). http://www.jpier.org/PIER/pier116/03.11031607.pdf
Feng, X., Jin, H., Zheng, R., Hu, K., Zeng, J., Shao, Z.: Optimization of sparse matrix-vector multiplication with variant CSR on GPUs. In: 2011 IEEE 17th International Conference on Parallel and Distributed Systems (ICPADS), pp. 165–172. IEEE, Tainan (2011)
Koza, Z., Matyka, M., Szkoda, S., Mirosław, Ł.: Compressed multirow storage format for sparse matrices on graphics processing units. SIAM J. Sci. Comput. 36(2), 219–239 (2014). http://dx.doi.org/10.1137/120900216
Monakov, A., Lokhmotov, A., Avetisyan, A.: Automatically tuning sparse matrix-vector multiplication for GPU architectures. In: Patt, Y., Foglia, P., Duesterwald, E., Faraboschi, P., Martorell, X. (eds.) High Performance Embedded Architectures and Compilers. Lecture Notes in Computer Science, vol. 5952, pp. 111–125. Springer, Heidelberg (2010). http://dx.doi.org/10.1007/978-3-642-11515-8_10.
Mukunoki, D., Takahashi, D.: Optimization of sparse matrix-vector multiplication for CRS format on NVIDIA Kepler architecture GPUs. In: Murgante, B., Misra, S., Carlini, M., Torre, C.M., Nguyen, H.Q., Taniar, D., Apduhan, B.O., Gervasi, O. (eds.) Computational Science and Its Applications – ICCSA 2013. Lecture Notes in Computer Science, vol. 7975, pp. 211–223. Springer, Heidelberg (2013). http://dx.doi.org/10.1007/978-3-642-39640-3_15
Su, B.Y., Keutzer, K.: clSpMV: a cross-platform opencl spmv framework on GPUs. In: Proceedings of the International Conference on Supercomputing, ICS ’12 (2012)
Vázquez, F., Garzón, E.M., Martınez, J.A., Fernández, J.: Accelerating sparse matrix vector product with GPUs. In: Proceedings of the International Conference on Computational and Mathematical Methods in Science and Engineering (CMMSE 2009), pp. 1081–1092. CMMSE, Gijón (2009)
Vázquez, F., Fernández, J.J., Garzón, E.M.: Automatic tuning of the sparse matrix vector product on GPUs based on the ELLR-T approach. Parallel Comput. 38(8), 408–420 (2012). doi:10.1016/j.parco.2011.08.003. http://www.sciencedirect.com/science/article/pii/S0167819111001050
Vuduc, R.W.: Automatic performance tuning of sparse matrix kernels. Ph.D. thesis, University of California (2003)
Yang, X., Parthasarathy, S., Sadayappan, P.: Fast sparse matrix-vector multiplication on GPUs: implications for graph mining. Proc. VLDB Endowment 4(4), 231–242 (2011)
Yoshizawa, H., Takahashi, D.: Automatic tuning of sparse matrix-vector multiplication for CRS format on GPUs. In: 2012 IEEE 15th International Conference on Computational Science and Engineering, pp. 130–136 (2012). doi:http://doi.ieeecomputersociety.org/10.1109/ICCSE.2012.28
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Koza, Z., Matyka, M., Mirosław, Ł., Poła, J. (2014). Sparse Matrix-Vector Product. In: Kindratenko, V. (eds) Numerical Computations with GPUs. Springer, Cham. https://doi.org/10.1007/978-3-319-06548-9_6
Download citation
DOI: https://doi.org/10.1007/978-3-319-06548-9_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-06547-2
Online ISBN: 978-3-319-06548-9
eBook Packages: Computer ScienceComputer Science (R0)