
Abstract
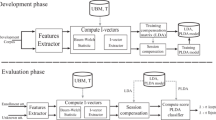
Current state-of-the-art speaker identification is a well-established research problem but reverberation is still a major issue used in real meeting scenarios. Dereverberation is essential for many applications such as speaker identification and speech recognition to improve the quality and intelligibility of speech signal interrupted by real reverberation environments. The classical approaches were focused on estimating desired speech signal with dereverberation by beamforming which is crucial for hands-free distant-speech interaction. Its performance degradation is caused when beamforming equipment is unable to comply with the restriction of being symmetric in time or synchronous in structure under real condition. In this paper, a new de-reverberated merging feature is presented for text-independent speaker identification issue applied as an important component of Multiple Distance Microphones (MDM) system used in real meeting scenario. This scenario poses new challenges: farfield, limited and short training and test data, and almost severe reverberation. To tackle this, we introduce a dimensionality reduction approach to extract informative low-dimension features from four kinds of MDM-based features. Experimental results on the MDM system processed reverberated signal show the effectiveness of the new approach and the presented performance evaluation demonstrates the robustness and effectiveness of the proposed approach with short test utterances.
Chapter PDF
Similar content being viewed by others

Keywords
References
Bhardwaj, S., Srivastava, S.: GFM-Based Methods for Speaker Identification. IEEE Trans. Systems, Man, and Cybernetics Society, 1–12 (2012)
Habets, E.A.P.: A Two-Stage Beamforming Approach for Noise Reduction and Dereverberation. IEEE Trans. Audio, Speech, and Language Processing 21(5), 945–958 (2003)
He, H., Wu, L., Lu, J., Qiu, X., Chen, J.: Time Difference of Arrival Estimation Exploiting Multichannel Spatio-Temporal Prediction. IEEE Trans. Audio, Speech, And Language Processing 21(3), 463–475 (2013)
Pardo, J.M., Anguera, X., Wooters, C.: Speaker Diarization for Multiple-Distant-Microphone Meetings Using Several Sources of Information. IEEE Trans. Computers 56(9), 1212–1224 (2007)
Anguera, X., Wooters, C., Hernando, J.: Speaker Diarization For Multi-Party Meetings Using Acoustic Fusion. In: IEEE Workshop on Automatic Speech Recognition and Understanding, pp. 426–431 (November 2005)
Davis, S.B., Mermelstein, P.: Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust., Speech, and Signal Process. 28(4), 357–366 (1980)
Virtanen, T., Singh, R., Raj, B.: Techniques for Noise Robustness in Automatic Speech Recognition. John Wiley&Sons, United Kingdom (2013)
Habets, E.A.P.: Single- and Multi-Microphone Speech Dereverberation using Spectral Enhancement., Ph.D thesis, Technische Universiteit Eindhoven (2007)
Kumar, K., Stern, R.M.: Maximum-Likelihood-Based Cepstral Inverse Filtering for Blind Speech Dereverberation. In: International Conference on Acoustics Speech and Signal Processing (ICASSP 2010), pp. 4282–4285 (March 2010)
Prince, S.J.D., Elder, J.H.: Probabilistic linear discriminant analysis for inferences about identity. Computer Vision, 1–8 (2007)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer International Publishing Switzerland
About this paper
Cite this paper
Yang, Y., Liu, J. (2014). Dereverberation for Speaker Identification in Meeting. In: Stephanidis, C. (eds) HCI International 2014 - Posters’ Extended Abstracts. HCI 2014. Communications in Computer and Information Science, vol 435. Springer, Cham. https://doi.org/10.1007/978-3-319-07854-0_103
Download citation
DOI: https://doi.org/10.1007/978-3-319-07854-0_103
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-07853-3
Online ISBN: 978-3-319-07854-0
eBook Packages: Computer ScienceComputer Science (R0)