
Abstract
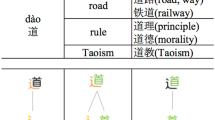
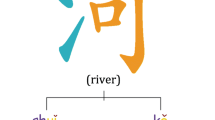
In this paper, we present a method to leverage radical for learning Chinese character embedding. Radical is a semantic and phonetic component of Chinese character. It plays an important role for modelling character semantics as characters with the same radical usually have similar semantic meaning and grammatical usage. However, most existing character (or word) embedding learning algorithms typically only model the syntactic contexts but ignore the radical information. As a result, they do not explicitly capture the inner semantic connections of characters via radical into the embedding space of characters. To solve this problem, we propose to incorporate the radical information for enhancing the Chinese character embedding. We present a dedicated neural architecture with a hybrid loss function, and integrate the radical information through softmax upon each character. To verify the effectiveness of the learned character embedding, we apply it on Chinese word segmentation. Experiment results on two benchmark datasets show that, our radical-enhanced method outperforms two widely-used context-based embedding learning algorithms.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
Collobert, R., Weston, J.: A unified architecture for natural language processing: Deep neural networks with multitask learning. In: Proceedings of the 25th International Conference on Machine Learning, pp. 160–167. ACM (2008)
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. In: ICLR (2013)
Mansur, M., Pei, W., Chang, B.: Feature-based neural language model and chinese word segmentation. In: IJCNLP (2013)
Zheng, X., Chen, H., Xu, T.: Deep learning for chinese word segmentation and pos tagging. In: EMNLP (2013)
Fu, R., Qin, B., Liu, T.: Exploiting multiple sources for open-domain hypernym discovery. In: EMNLP, pp. 1224–1234 (2013)
Jin, P., Carroll, J., Wu, Y., McCarthy, D.: Improved word similarity computation for chinese using sub-word information. In: 2011 Seventh International Conference on Computational Intelligence and Security (CIS), pp. 459–462. IEEE (2011)
Jin, P., Carroll, J., Wu, Y., McCarthy, D.: Distributional similarity for chinese: Exploiting characters and radicals. In: Mathematical Problems in Engineering (2012)
Zhang, M., Zhang, Y., Che, W., Liu, T.: Chinese parsing exploiting characters. In: Proc. ACL (Volume 1: Long Papers), Sofia, Bulgaria, pp. 125–134. Association for Computational Linguistics (August 2013)
Turney, P.D., Pantel, P., et al.: From frequency to meaning: Vector space models of semantics. Journal of Artificial Intelligence Research 37(1), 141–188 (2010)
Turian, J., Ratinov, L., Bengio, Y.: Word representations: a simple and general method for semi-supervised learning. ACL (2010)
Bengio, Y.: Deep learning of representations: Looking forward. arXiv preprint arXiv:1305.0445 (2013)
Bengio, Y., Ducharme, R., Vincent, P., Janvin, C.: A neural probabilistic language model. The Journal of Machine Learning Research 3, 1137–1155 (2003)
Mikolov, T., Karafiát, M., Burget, L., Cernockỳ, J., Khudanpur, S.: Recurrent neural network based language model. In: INTERSPEECH, pp. 1045–1048 (2010)
Huang, E.H., Socher, R., Manning, C.D., Ng, A.Y.: Improving word representations via global context and multiple word prototypes. In: Proc. ACL, pp. 873–882. Association for Computational Linguistics (2012)
Tang, D., Wei, F., Yang, N., Zhou, M., Liu, T., Qin, B.: Learning sentiment-specific word embedding for twitter sentiment classification. In: Proc. ACL (Volume 1: Long Papers), Baltimore, Maryland, pp. 1555–1565. Association for Computational Linguistics (June 2014)
Luong, M.-T., Socher, R., Manning, C.D.: Better word representations with recursive neural networks for morphology. In: CoNLL 2013, p. 104 (2013)
Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., Kuksa, P.: Natural language processing (almost) from scratch. The Journal of Machine Learning Research 12, 2493–2537 (2011)
Forney Jr., G.D.: The viterbi algorithm. Proceedings of the IEEE 61(3), 268–278 (1973)
Jiang, W., Huang, L., Liu, Q., Lü, Y.: A cascaded linear model for joint chinese word segmentation and part-of-speech tagging. In: Proc. ACL. Citeseer (2008)
Wang, Y., Jun’ichi Kazama, Y.T., Tsuruoka, Y., Chen, W., Zhang, Y., Torisawa, K.: Improving chinese word segmentation and pos tagging with semi-supervised methods using large auto-analyzed data. In: IJCNLP, pp. 309–317 (2011)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer International Publishing Switzerland
About this paper
Cite this paper
Sun, Y., Lin, L., Yang, N., Ji, Z., Wang, X. (2014). Radical-Enhanced Chinese Character Embedding. In: Loo, C.K., Yap, K.S., Wong, K.W., Teoh, A., Huang, K. (eds) Neural Information Processing. ICONIP 2014. Lecture Notes in Computer Science, vol 8835. Springer, Cham. https://doi.org/10.1007/978-3-319-12640-1_34
Download citation
DOI: https://doi.org/10.1007/978-3-319-12640-1_34
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-12639-5
Online ISBN: 978-3-319-12640-1
eBook Packages: Computer ScienceComputer Science (R0)