
Abstract
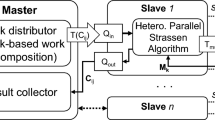
Matrix multiplication (MM) is one of the core problems in the high performance computing domain and its efficiency impacts performances of almost all matrix problems. The high-density multi-GPU architecture escalates the complexities of such classical problem, though it greatly exceeds the capacities of previous homogeneous multicore architectures. In order to fully exploit the potential of such multi-accelerator architectures for multiplying matrices, we systematically evaluate the performances of two prevailing tile-based MM algorithms, standard and Strassen. We use a high-density multi-GPU server, CS-Storm which can support up to eight NVIDIA GPU cards and we test three generations of GPU cards which are K20Xm, K40m and K80. Our results show that (1) Strassen is often faster than standard method on multicore architecture but it is not beneficial for small enough matrices. (2) Strassen is more efficient than standard algorithm on low-density GPU solutions but it quickly loses its superior on high-density GPU solutions. This is a result of more additions needed in Strassen than in standard algorithm. Experimental results indicate that: though Strassen needs less arithmetic operations than standard algorithm, the heterogeneity of computing resources is a key factor of determining the best-practice algorithm.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
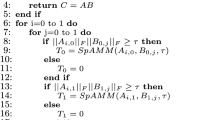

References
Robinson, S.: Toward an optimal algorithm for matrix multiplication. SIAM News 38, 1–3 (2005)
Lancaster, P., Tismenetsky, M.: The Theory of Matrices: with Applications. Academic Press, Waltham (1985)
Dorn, F.: Dynamic programming and fast matrix multiplication. In: Azar, Y., Erlebach, T. (eds.) ESA 2006. LNCS, vol. 4168, pp. 280–291. Springer, Heidelberg (2006)
Gunnels, J.A., Henry, G.M., Van De Geijn, R.A.: A Family of high-performance matrix multiplication algorithms. In: Alexandrov, V.N., Dongarra, J.J., Juliano, B.A., Renner, R.S., Kenneth Tan, C.J. (eds.) ICCS 2001. LNCS, vol. 2073, pp. 51–60. Springer, Heidelberg (2001)
Kurzak, J., Alvaro, W., Dongarra, J.: Optimizing matrix multiplication for a short-vector SIMD architecture–CELL processor. Parallel Comput. 35, 138–150 (2009)
Strassen, V.: Gaussian elimination is not optimal. Numer. Math. 13, 354–356 (1969)
Coppersmith, D., Winograd, S.: Matrix multiplication via arithmetic progressions. In: Proceedings of the Nineteenth Annual ACM Symposium on Theory of Computing, pp. 1–6 (2004)
Williams, V.V.: Multiplying matrices faster than Coppersmith-Winograd. In: Proceedings of the Forty-Fourth Annual ACM Symposium on Theory of Computing, pp. 887–898 (2012)
Chou, C.C., Deng, Y.F., Li, G., Wang, Y.: Parallelizing strassens method for matrix multiplication on distributed-memory mimd architectures. Comput. Math. Appl. 30, 49–69 (1995)
D’Alberto, P., Nicolau, A.: Using recursion to boost ATLAS’s performance. In: Labarta, J., Joe, K., Sato, T. (eds.) ISHPC 2006 and ALPS 2006. LNCS, vol. 4759, pp. 142–151. Springer, Heidelberg (2008)
Ohshima, S., Kise, K., Katagiri, T., Yuba, T.: Parallel processing of matrix multiplication in a CPU and GPU heterogeneous environment. In: Daydé, M., Palma, J.M.L.M., Coutinho, A.L.G.A., Pacitti, E., Lopes, J.C. (eds.) VECPAR 2006. LNCS, vol. 4395, pp. 305–318. Springer, Heidelberg (2007)
Irony, D., Toledo, S., Tiskin, A.: Communication lower bounds for distributed-memory matrix multiplication. J. Parallel Distrib. Comput. 64, 1017–1026 (2004)
Fatahalian, K., Sugerman, J., Hanrahan, P.: Understanding the efficiency of GPU algorithms for matrix-matrix multiplication. In: Proceedings of the ACM SIGGRAPH/EUROGRAPHICS Conference on Graphics Hardware, pp. 133–137 (2004)
Beaumont, O., Boudet, V., Rastello, F., Robert, Y.: Matrix multiplication on heterogeneous platforms. IEEE Trans. Parallel Distrib. Syst. 12, 1033–1051 (2001)
Thottethodi, M., Chatterjee, S., Lebeck, A.R.: Tuning Strassen’s matrix multiplication for memory efficiency. In: Proceedings of the 1998 ACM/IEEE Conference on Supercomputing (CDROM), pp. 1–14 (1998)
Luo, Q., Drake, J.B.: A scalable parallel Strassen’s matrix multiplication algorithm for distributed-memory computers. In: Proceedings of the 1995 ACM Symposium on Applied Computing, pp. 221–226 (1995)
Choi, J., Walker, D.W., Dongarra, J.J.: PUMMA: parallel universal matrix multiplication algorithms on distributed memory concurrent computers. Concurrency: Pract. Experience 6, 543–570 (1994)
Zhang, P., Gao, Y., Fierson, J., Deng, Y.: Eigenanalysis-based task mapping on parallel computers with cellular networks. Math. Comput. 83, 1727–1756 (2014)
Zhang, P., Powell, R., Deng, Y.: Interlacing bypass rings to torus networks for more efficient networks. IEEE Trans. Parallel Distrib. Syst. 22, 287–295 (2011)
Zhang, P., Deng, Y., Feng, R., Luo, X., Wu, J.: Evaluation of various networks configurated by adding bypass or torus links. IEEE Trans. Parallel Distrib. Syst. 26, 984–996 (2015)
Ballard, G., Demmel, J., Holtz, O., Lipshitz, B., Schwartz, O.: Communication-optimal parallel algorithm for strassen’s matrix multiplication. In: Proceedings of the 24th ACM Symposium on Parallelism in Algorithms and Architectures, pp. 193–204 (2012)
Goto, K., Geijn, R.A.: Anatomy of high-performance matrix multiplication. ACM Trans. Math. Softw. (TOMS) 34, 12 (2008)
Barrachina, S., Castillo, M., Igual, F.D., Mayo, R., Quintana-Orti, E.S.: Evaluation and tuning of the level 3 CUBLAS for graphics processors. In: IEEE International Symposium on Parallel and Distributed Processing, IPDPS 2008, pp. 1–8 (2008)
Demmel, J.: LAPACK: a portable linear algebra library for supercomputers. In: IEEE Control Systems Society Workshop on Computer-Aided Control System Design, pp. 1–7 (1989)
CS-Storm specification. (2014). http://www.cray.com/sites/default/files/CrayCS-Storm.pdf
Fang, Y.-C., Gao, Y., Stap, C.: Future enterprise computing looking into 2020. In: Park, J.J., Zomaya, A., Jeong, H.-Y., Obaidat, M. (eds.) Frontier and Innovation in Future Computing and Communications. LNEE, vol. 301, pp. 127–134. Springer, Heidelberg (2014)
Skiena, S.S.: The Algorithm Design Manual, vol. 1. Springer, Heidelberg (1998)
Zhang, P., Ling, L., Deng, Y.: A data-driven paradigm for mapping problems. Parallel Comput. (2015). doi: 10.1016/j.parco.2015.05.002 (In press)
Huss-Lederman, S., Jacobson, E.M., Johnson, J.R., Tsao, A., Turnbull, T.: Implementation of Strassen’s algorithm for matrix multiplication. In: Proceedings of the 1996 ACM/IEEE Conference on Supercomputing, pp. 32–32 (1996)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Zhang, P., Gao, Y. (2015). Matrix Multiplication on High-Density Multi-GPU Architectures: Theoretical and Experimental Investigations. In: Kunkel, J., Ludwig, T. (eds) High Performance Computing. ISC High Performance 2015. Lecture Notes in Computer Science(), vol 9137. Springer, Cham. https://doi.org/10.1007/978-3-319-20119-1_2
Download citation
DOI: https://doi.org/10.1007/978-3-319-20119-1_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-20118-4
Online ISBN: 978-3-319-20119-1
eBook Packages: Computer ScienceComputer Science (R0)