
Abstract
Proper benchmarking and resource measurement is an important topic, because benchmarking is a widely-used method for the comparative evaluation of tools and algorithms in many research areas. It is essential for researchers, tool developers, and users, as well as for competitions. We formulate a set of requirements that are indispensable for reproducible benchmarking and reliable resource measurement of automatic solvers, verifiers, and similar tools, and discuss limitations of existing methods and benchmarking tools. Fulfilling these requirements in a benchmarking framework is complex and can (on Linux) currently only be done by using the cgroups feature of the kernel. We provide

, a ready-to-use, tool-independent, and free implementation of a benchmarking framework that fulfills all presented requirements, making reproducible benchmarking and reliable resource measurement easy. Our framework is able to work with a wide range of different tools and has proven its reliability and usefulness in the International Competition on Software Verification.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others



Notes
- 1.
- 2.
- 3.
- 4.
Our experience from competition organization shows that developers of complex tools are not always aware of how their system spawns child processes and how to properly terminate them.
- 5.
- 6.
We experienced this when organizing SV-COMP’13, for a portfolio-based verifier. Initial CPU time measurements were significantly too low, which was luckily discovered by chance. The verifier had to be patched to wait for its sub-processes and the benchmarks had to be re-run.
- 7.
- 8.
Actually, independent hierarchies are currently supported. We restrict ourselves to the single-hierarchy case because independent hierarchies are going to be deprecated.
- 9.
- 10.
- 11.
Or clear the caches with drop_caches.
- 12.
- 13.
- 14.
- 15.
Tools that do not support this specification format can also be benchmarked. In this case, the specification is used by
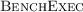
only to determine the expected result.
- 16.
- 17.
For example,
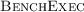
is used to automatically check for regressions in the integration test-suite of
.
- 18.
We successfully use
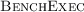
on four different clusters, each under different administrative control and with software as old as SuSE Enterprise 11 and Linux 3.0, and on the machines of the student computer pool of our department.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
c.f. verify.sh in the
package
- 26.
git revision 9d58031 from 2013-09-13, c.f. https://github.com/tkren/vcwc/
- 27.
- 28.
- 29.
- 30.
- 31.





References
Balint, A., Belov, A., Heule, M., Järvisalo, M.: Proceedings of SAT competition 2013: Solver and benchmark descriptions. Technical report B-2013-1, University of Helsinki (2013)
Barrett, C., Deters, M., de Moura, L., Oliveras, A., Stump, A.: 6 years of SMT-COMP. J. Autom. Reasoning 50(3), 243–277 (2012)
Beyer, D.: Software verification and verifiable witnesses. In: Baier, C., Tinelli, C. (eds.) TACAS 2015. LNCS, vol. 9035, pp. 401–416. Springer, Heidelberg (2015)
Beyer, D., Dresler, G., Wendler, P.: Software verification in the Google App-Engine Cloud. In: Biere, A., Bloem, R. (eds.) CAV 2014. LNCS, vol. 8559, pp. 327–333. Springer, Heidelberg (2014)
Charwat, G., Ianni, G., Krennwallner, T., Kronegger, M., Pfandler, A., Redl, C., Schwengerer, M., Spendier, L.K., Wallner, J.P., Xiao, G.: VCWC: a versioning competition workflow compiler. In: Cabalar, P., Son, T.C. (eds.) LPNMR 2013. LNCS, vol. 8148, pp. 233–238. Springer, Heidelberg (2013)
Handigol, N., Heller, B., Jeyakumar, V., Lantz, B., McKeown, N.: Reproducible network experiments using container-based emulation. In: CoNEXT 2012. pp. 253–264. ACM, New York (2012). http://www.dblp.org/rec/bibtex/conf/conext/HandigolHJLM12
JCGM Working Group 2. International vocabulary of metrology - basic and general concepts and associated terms (VIM), 3rd edn. Technical report JCGM 200:2012, BIPM (2012)
Kordon, F., Hulin-Hubard, F.: BenchKit, a tool for massive concurrent benchmarking. In: ACSD 2014. pp. 159–165. IEEE (2014)
Mytkowicz, T., Diwan, A., Hauswirth, M., Sweeney, P.F.: Producing wrong data without doing anything obviously wrong! In: ASPLOS, pp. 265–276. ACM, New York (2009). http://www.dblp.org/rec/bibtex/conf/asplos/MytkowiczDHS09
Roussel, O.: Controlling a solver execution with the runsolver tool. J. Satisfiability, Boolean Model. Comput. 7, 139–144 (2011)
Singh, B., Srinivasan, V.: Containers: challenges with the memory resource controller and its performance. In: Ottawa Linux Symposium (OLS), p. 209. (2007)
Stump, A., Sutcliffe, G., Tinelli, C.: StarExec: a cross-community infrastructure for logic solving. In: Demri, S., Kapur, D., Weidenbach, C. (eds.) IJCAR 2014. LNCS, vol. 8562, pp. 367–373. Springer, Heidelberg (2014)
Tichy, W.F.: Should computer scientists experiment more? IEEE Comput. 31(5), 32–40 (1998)
Acknowledgement
We thank Hubert Garavel, Jiri Slaby, and Aaron Stump for their helpful comments regarding BenchKit, cgroups, and StarExec, respectively.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix: Impact of Hyper-threading and NUMA
Appendix: Impact of Hyper-threading and NUMA
To show that hyper-threading and non-uniform memory access (NUMA) can have a negative influence on benchmarking if not handled appropriately, we executed benchmarks using the predicate analysis of the verifier

Footnote 29 in revision 15 307 from the project repositoryFootnote 30. We used 4011 C programs from SV-COMP’15 [3] (excluding categories not supported by

) and a CPU-time limit of 900 s. Tables with the full results and the raw data are available on our supplementary webpage.Footnote 31
Note that the actual performance impact will differ according to the resource-usage characteristics of the benchmarked tool. For example, a tool that uses only very little memory but fully utilizes its CPU core(s) will be influenced more by hyper-threading than by non-local memory, whereas for a tool that relies more on memory accesses it might be the other way around. In particular, the results for

that are shown here are not generalizable and show only that there is such an impact. Because the quantitative amount of the impact is not predictable and might be non-deterministic, it is important to rule out these factors for reproducible benchmarking in any case.

Scatter plot showing the influence of hyper-threading for 2 472 runs of

Impact of Hyper-threading. To show the impact of hyper-threading, we executed benchmarks on a machine with a single Intel Core i7-4770 3.4 GHz CPU socket (with four physical cores and hyper-threading) and 33 GB of memory. We executed the verifier twice in parallel and assigned one virtual core and 4.0 GB of memory to each run. In one instance of the benchmark, we assigned each of the two parallel runs a virtual core from separate physical cores. In a second instance of the benchmark, we assigned each of the two parallel runs one virtual core from the same physical core, such that both runs had to share the hardware resources of one physical core. A scatter plot with the results is shown in Fig. 1. For the 2 472 programs from the benchmark set that

could solve on this machine, 13 h of CPU time were necessary using two separate physical cores and 19 h of CPU time were necessary using the same physical core, an increase of 41 % caused by the inappropriate core assignment.
Impact of NUMA. To show the impact of non-uniform memory access, we executed benchmarks on a NUMA machine with two Intel Xeon E5-2690 v2 2.6 GHz CPUs with 63 GB of local memory each. We executed the verifier twice in parallel, assigning all cores of one CPU socket and 60 GB of memory to each of the two runs. In one instance of the benchmark, we assigned memory to each run that was local to the CPU the run was executed on. In a second instance of the benchmark, we deliberately forced each of the two runs to use only memory from the other CPU socket, such that all memory accesses were indirect. For the 2 483 programs from the benchmark set that

could solve on this machine, 19 h of CPU time were necessary using local memory and 21 h of CPU time were necessary using remote memory, an increase of 11 % caused by the inappropriate memory assignment. The wall time also increased by 9.5 %.
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Beyer, D., Löwe, S., Wendler, P. (2015). Benchmarking and Resource Measurement. In: Fischer, B., Geldenhuys, J. (eds) Model Checking Software. SPIN 2015. Lecture Notes in Computer Science(), vol 9232. Springer, Cham. https://doi.org/10.1007/978-3-319-23404-5_12
Download citation
DOI: https://doi.org/10.1007/978-3-319-23404-5_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-23403-8
Online ISBN: 978-3-319-23404-5
eBook Packages: Computer ScienceComputer Science (R0)