
Abstract
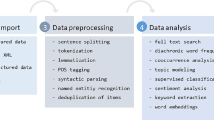
Unstructured data accounts for more than 80 % of enterprise data and is growing at an annual exponential rate of 60 %. Text mining refers to the process of discovering new, previously unknown and potentially useful information from a variety of unstructured data including user-generated text content (UGTC). Given that Portuguese language is one of the most common languages in the world, and it is also the second most frequent language on Twitter, the goal of this work is to plot the landscape of current studies that relates the application of text mining to UGTC in the Portuguese language. The systematic mapping review method was applied to search, select, and to extract data from the included studies. Our manual and automated searches retrieved 6075 studies up to year 2014, from which 35 were included in the study. Text classification concentrates 79 % of all text mining tasks, having the Naïve Bayes as the main classifier and Twitter as the main data source.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


References
Marine-Roig, E., Anton Clavé, S.: Tourism analytics with massive user-generated content: A case study of Barcelona. J. Destin. Mark. Manag. 1–11 (2015).
Delen, D., Crossland, M.D.: Seeding the survey and analysis of research literature with text mining. Expert Syst. Appl. 34, 1707–1720 (2008).
Hotho, A., Andreas, N., Paaß, G., Augustin, S.: A Brief Survey of Text Mining. (2005).
Tan, A.: Text Mining : The state of the art and the challenges Concept-based. Proc. PAKDD 1999 Work. Knowl. Disocovery from Adv. Databases. 65–70 (1999).
Pardo, T., Gasperin, C., Caseli, H., Nunes, M. das G. V.: Computational Linguistics in Brazil : an overview. Proc. NAACL HLT 2010 Am. 1–7 (2010).
Poblete, B., Garcia, R., Mendoza, M., Jaimes, A.: Do All Birds Tweet the Same ? Characterizing Twitter Around the World. Society. 1025–1030 (2011).
Petersen, K., Feldt, R., Mujtaba, S., Mattsson, M.: Systematic Mapping Studies in Software Engineering. (2007).
Kitchenham, B., Charters, S.: Guidelines for performing Systematic Literature Reviews in Software Engineering. Tech. Rep. EBSE-2007-01, (2007).
Hotho, A., Nürnberger, A., Paaß, G.: A Brief Survey of Text Mining. Ldv Forum. (2005).
da Silva Conrado, M., Felippo, A., Salgueiro Pardo, T., Rezende, S.: A survey of automatic term extraction for Brazilian Portuguese. J. Brazilian Comput. Soc. 20, 12 (2014).
Lu, W., Stepchenkova, S.: User-Generated Content as a Research Mode in Tourism and Hospitality Applications: Topics, Methods, and Software. J. Hosp. Mark. Manag. (2015).
Laboreiro, G., Bošnjak, M., Sarmento, L., Rodrigues, E.M., Oliveira, E.: Determining language variant in microblog messages. In: Proceedings of the 28th Annual ACM Symposium on Applied Computing - p. 902. ACM Press, USA (2013).
Evangelista, T.R., Padilha, T.P.P.: Monitoramento de Posts Sobre Empresas de E-Commerce em Redes Sociais Utilizando Análise de Sentimentos. (2013).
Takçı, H., Güngör, T.: A high performance centroid-based classification approach for language identification. Pattern Recognit. Lett. 33, 2077–2084 (2012).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Souza, E., Castro, D., Vitório, D., Teles, I., Oliveira, A.L.I., Gusmão, C. (2016). Characterizing User-Generated Text Content Mining: A Systematic Mapping Study of the Portuguese Language. In: Rocha, Á., Correia, A., Adeli, H., Reis, L., Mendonça Teixeira, M. (eds) New Advances in Information Systems and Technologies. Advances in Intelligent Systems and Computing, vol 444. Springer, Cham. https://doi.org/10.1007/978-3-319-31232-3_96
Download citation
DOI: https://doi.org/10.1007/978-3-319-31232-3_96
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-31231-6
Online ISBN: 978-3-319-31232-3
eBook Packages: EngineeringEngineering (R0)