
Abstract
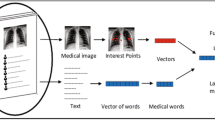
We present in this paper a model representation of a report extracted from a radiological collaborative social network, which combines textual and visual descriptors. The text and the medical image, which compose a report, are each described by a vector of TF-IDF weights following an approach “bag-of-words”. The model used, allows for multimodal queries to research medical information. Our model is evaluated on the basis imageCLEFMed’ 2015 for which we have the ground truth. Many experiments were conducted with various descriptors and many combinations of modalities. Analysis of the results shows that the model, which is based on two modalities allows to increase the performance of a search system based on only one modality, that it be textual or visual.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Bouslimi, R., Akaichi, J.: Automatic medical image annotation on social network of physician collaboration. J. Netw. Model. Anal. Health Inform. Bioinform. 4(10), 219–228 (2015)
Csurka, G., Dance, C., Fan, L., Willamowski, J., Bray, C.: Visual categorization with bags of keypoints. In: ECCV 2004 Workshop on Statistical Learning in Computer Vision, pp. 59–74 (2004)
de Herrera, S.G.A., Muller, H., Bromuri, S.: Overview of the imageclef 2015 medical classification task. In: Working Notes of CLEF (Cross Language Evaluation Forum) (2015)
Jurie, F., Triggs, W.: Creating efficient codebooks for visual recognition. In: ICCV (2005)
Larlus, D., Dork, G., Jurie, F.: Cration de vocabulaires visuels efficaces pour la catgorisation d’images. Reconnaissance des Formes et Intelligence Artificielle (2006)
Lowe, D.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 60(2), 91–110 (2004)
Matas, J., Chum, O., Martin, U., Pajdla, T.: Robust wide baseline stereo from maximally stable extremal regions. In: Proceedings of the British Machine Vision Conference, pp. 384–393 (2002)
Messoudi, A., Bouslimi, R., Akaichi, J.: Indexing medical images based on collaborative experts reports. Int. J. Comput. Appl. 70(5), 0975–8887 (2013)
Mikolajczyk, K., Tuytelaars, T., Schmid, C., Zisserman, A., Matas, J., Schaffalitzky, F., Kadir, T., Van Gool, L.: A comparison of affine region detectors. Int. J. Comput. Vis. 65, 43–72 (2005)
Robertson, S., Walker, S., Hancock-Beaulieu, M., Gull, A., Lau, M.: Okapi at trec-3. In: Text REtrieval Conference, pp. 21–30 (1994)
Salton, G., Wong, A., Yang, C.: A vector space model for automatic indexing. Commun. ACM 18(11), 613–620 (1975)
Vidal-Naquet, M., Ullman, S.: Object recognition with informative features and linear classification. In: ICCV, pp. 281–288 (2003)
Zhai, C.: Notes on the lemur tfidf model (2001)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Bouslimi, R., Ayadi, M.G., Akaichi, J. (2016). Content Modelling in Radiological Social Network Collaboration. In: Kozielski, S., Mrozek, D., Kasprowski, P., Małysiak-Mrozek, B., Kostrzewa, D. (eds) Beyond Databases, Architectures and Structures. Advanced Technologies for Data Mining and Knowledge Discovery. BDAS BDAS 2015 2016. Communications in Computer and Information Science, vol 613. Springer, Cham. https://doi.org/10.1007/978-3-319-34099-9_38
Download citation
DOI: https://doi.org/10.1007/978-3-319-34099-9_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-34098-2
Online ISBN: 978-3-319-34099-9
eBook Packages: Computer ScienceComputer Science (R0)