
Abstract
Estimating statistical information about the most recent parts of a stream is an important problem in network and cloud monitoring. Modern cloud infrastructures generate in high volume and high velocity various measurements on CPU, memory and storage utilization, and also different types of application specific metrics. Tracking the quantiles of these measurements in a fast and space-efficient manner is an essential task in monitoring the health of the overall system. There are space-efficient algorithms for estimating approximate quantiles under the “sliding window” model of streams. However, they are slow in query time, which makes them less desirable for monitoring applications. In this paper we extend the popular Greenwald-Khanna algorithm for approximating quantiles in the unbounded stream model into the sliding window model, getting improved runtime guarantees over the existing algorithm for this problem. These improvements are confirmed by experiment.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
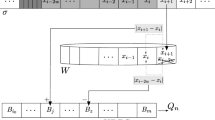
For convenience of analysis we treat W as fixed; however, like many algorithms in this model, ours is easily adapted to answer queries about any window size \(w \le W\). For applications, W can thus be thought of as the maximum history length of interest.
- 2.
References
Arasu, A., Manku, G.S.: Approximate counts and quantiles over sliding windows. In: PODS, pp. 286–296. ACM (2004)
Buragohain, C., Suri, S.: Quantiles on streams. In: Liu, L., Özsu, M.T. (eds.) Encyclopedia of Database Systems, pp. 2235–2240. Springer, New York (2009)
Cormode, G., Muthukrishnan, S.: An improved data stream summary: the count-min sketch and its applications. J. Algorithms 55(1), 58–75 (2005)
Datar, M., Gionis, A., Indyk, P., Motwani, R.: Maintaining stream statistics over sliding windows. SIAM J. Comput. 31(6), 1794–1813 (2002)
Greenwald, M., Khanna, S.: Space-efficient online computation of quantile summaries. In: ACM SIGMOD Record, vol. 30, pp. 58–66. ACM (2001)
Lin, X., Hongjun, L., Jian, X., Yu, J.X.: Continuously maintaining quantile summaries of the most recent n elements over a data stream. In: ICDE, pp. 362–373. IEEE (2004)
Mousavi, H., Zaniolo, C.: Fast and accurate computation of equi-depth histograms over data streams. In: EDBT, pp. 69–80. ACM (2011)
Mousavi, H., Zaniolo, C.: Fast computation of approximate biased histograms on sliding windows over data streams. In: SSDBM, p. 13. ACM (2013)
Papapetrou, O., Garofalakis, M., Deligiannakis, A.: Sketch-based querying of distributed sliding-window data streams. Proc. VLDB Endowment 5(10), 992–1003 (2012)
Shrivastava, N., Buragohain, C., Agrawal, D., Suri, S.: Medians and beyond: new aggregation techniques for sensor networks. In: SenSys, pp. 239–249. ACM (2004)
Zhang, Q., Wang, W.: A fast algorithm for approximate quantiles in high speed data streams. In: SSDBM, p. 29. IEEE (2007)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix: Correctness Analysis
Appendix: Correctness Analysis
1.1 Proof of Theorem 5
We use \(\mathbb {G}_i\), \(\mathbb {D}_i\) to refer to the sets of elements being tracked by the EH sketches \(G_i\) and \(D_i\). We can define \(\mathbb {G}_i\) and \(\mathbb {D}_i\) as the value-timestamp pairs \(\{(v,t), (v',t'), \ldots \}\) of all elements ever added to the EH sketches \(G_i\) and \(D_i\). We use \(\mathbb {G}_i(t)\) and \(\mathbb {D}_i(t)\) to denote the set of value-timestamp pairs in \(\mathbb {G}_i\) and \(\mathbb {D}_i\) that has not expired at time t. We can think of \(\mathbb {G}_i(t)\) and \(\mathbb {D}_i(t)\) as exact versions of the EH sketches \(G_i\) and \(D_i\), and they are useful in establishing our correctness claims.
We state without proof the following two claims:
Claim 1:
At all time t, the set of \(\mathbb {G}_i(t)\)’s partition the set of all observations in the current window \([t-W,t]\).
Claim 2:
At all time t, for all i, \(\mathbb {D}_i(t) \subseteq \cup _{j>i} \mathbb {G}_j(t)\).
Claim 1 is true because all elements inserted started out as singleton sets of \(\mathbb {G}_i(t)\), and subsequent merging in \(\mathtt{{COM}}\mathtt{{PRESS}}\) always preserves the disjointness of the \(\mathbb {G}_i(t)\) and never drops any elements. Claim 2 is true because by the insertion rule, at the time of insertion \(\mathbb {D}_i(t)\) is constructed from merging some \(\mathbb {G}_{i+1}(t)\) and \(\mathbb {D}_{i+1}(t)\). By unrolling this argument, \(\mathbb {D}_{i+1}(t)\) is constructed from \(\mathbb {G}_j(t)\) and \(\mathbb {D}_j(t)\) with \(j>i+1\). Since \(\mathbb {D}_i(t)\) starts as an empty set initially and none of the insertion and merge operations we do reorder the sets \(\mathbb {G}_i(t)\), the elements in \(\mathbb {D}_i(t)\) have to come from the sets \(\mathbb {G}_j(t)\) for \(j>i\).
Lemma 11
At all t, for all i, all elements in \(\cup _{j>i} \mathbb {G}_j\!(t) {\setminus } \mathbb {D}_i(t)\) have values greater than or equal to \(v_i(t)\).
Proof
We prove this by induction on t, and show that the statement is preserved after \(\mathtt{{IN}}\mathtt{{SERT}}\), expiration, and \(\mathtt{{COM}}\mathtt{{PRESS}}\). As the base case for induction, the statement clearly holds initially before any \(\mathtt{{COM}}\mathtt{{PRESS}}\) operation, when all \(\mathbb {G}_j\) are singletons and \(\mathbb {D}_j\) are empty.
We assume at time t, an element is inserted, then an expiring element is deleted, then the timestamp increments.
\(\mathtt{{IN}}\mathtt{{SERT}}\): Suppose an observation v is inserted at time t between \((v_{i-1}, G_{i-1}, D_i)\) and \((v_i, G_i, D_i)\). We insert the new tuple \((v, EH(v,t), \mathtt {merge}(D_i, \mathtt {tail}(G_i)))\) into our summary. Here EH(v, t) refers to the EH sketch with a single element v added at time t. In the set notation, this corresponds to inserting \((v, \mathbb {G}=\{(v,t)\}, \mathbb {D}=(\mathbb {G}_i{\setminus }\{v_i\})\cup \mathbb {D}_i)\).
We assume the statement holds before insertion of v. For \(r<i\), before insertion we know elements in \(\cup _{j>r} \mathbb {G}_j(t) {\setminus } \mathbb {D}_r(t)\) are all greater than or equal to \(v_r\) by the inductive hypothesis. After insertion the new set becomes \((\cup _{j>r} \mathbb {G}_j(t) {\setminus } \mathbb {D}_r(t)) \cup \{(v,t)\}\), which maintains the statement because by the insertion rule we know \(v_r \le v\) for all \(r<i\).
For \(r\ge i\), insertion of v does not change the set \(\cup _{j>r} \mathbb {G}_j(t) {\setminus } \mathbb {D}_r(t)\) at all, so the statement continues to hold.
At the newly inserted tuple v, we know \(v<v_i\), and all elements in \(\cup _{j>i} \mathbb {G}_j(t) {\setminus } \mathbb {D}_i(t)\) are greater than or equal to \(v_i\) by the inductive hypothesis. So all elements in \(\cup _{j>i} \mathbb {G}_j(t) {\setminus } \mathbb {D}_i(t)\) are greater than v.
At v, the set in the statement becomes
All elements in this set are greater than or equal to v, so the statement holds for v as well.
\(\mathtt {EXPIRE}\): When the timestamp increments to \(t+1\), one of the elements v expires. Pick any \(v_i\), the expiring element v can be in any one of the following 3 sets:
-
1.
\(\cup _{j\le i} \mathbb {G}_j(t)\)
-
2.
\(\mathbb {D}_i(t)\)
-
3.
\(\cup _{j>i} \mathbb {G}_j(t){\setminus } \mathbb {D}_i(t)\)
By Claims 1 and 2, these 3 sets are disjoint and contain all observations in the current window. Assuming \(v\ne v_i\), if v comes from set 1, then \(\cup _{j\le i} \mathbb {G}_j(t+1)\) decrease by 1 but does not affect the set \(\cup _{j> i} \mathbb {G}_j(t+1){\setminus } \mathbb {D}_i(t+1)\) in our statement. If v comes from set 2, then \(\cup _{j> i} \mathbb {G}_j(t+1){\setminus } \mathbb {D}_i(t+1)\) remains unchanged as v is contained in both \(\mathbb {D}_i(t)\) and \(\cup _{j>i} \mathbb {G}_j(t)\) (Claim 2). If v comes from set 3, then \(\cup _{j> i} \mathbb {G}_j(t+1){\setminus } \mathbb {D}_i(t+1)\) decreases by 1, the number of elements greater than \(v_i\) decreases by 1. The statement still holds in all these cases.
If \(v=v_i\) is the expiring element, then at \(t+1\) there is another observation \(v'\) in the EH \(G_i\) that becomes the maximum element in \(G_i\). But we know \(v'\le v_i\) as \(v_i\) is the maximum element in \(G_i\) before expiration, so the elements in \(\cup _{j> i} \mathbb {G}_j(t+1){\setminus } \mathbb {D}_i(t+1)\) which are greater than \(v_i\) are also greater than \(v'\), and the statement holds.
\(\mathtt{{COM}}\mathtt{{PRESS}}\): Suppose the \(\mathtt{{COM}}\mathtt{{PRESS}}\) step merges two tuples \((v_{i-1}, G_{i-1}, D_{i-1})\) and \((v_i, G_i, D_i)\). For \(r>i\), this does not affect the set \(\cup _{j>r} \mathbb {G}_j(t){\setminus } \mathbb {D}_r(t)\). For \(r<i-1\), this does not affect the set \(\cup _{j>r} \mathbb {G}_j(t){\setminus } \mathbb {D}_r(t)\) as the deletion of \(\mathbb {G}_{i-1}\) is compensated by setting \(\mathbb {G}_i = \mathbb {G}_{i-1}\cup \mathbb {G}_i\). For \(r=i\), if \(v_i = \max (v_{i-1}, v_i)\) then the set \(\cup _{j>i} \mathbb {G}_j(t){\setminus } \mathbb {D}_i(t)\) does not change. Since \(v_i\) does not change either the statement holds after merging.
If \(v_{i-1} = \max (v_{i-1}, v_i)\) (which is possible with inversion), then by inductive hypothesis we know \(\cup _{j>{i-1}} \mathbb {G}_j(t){\setminus } \mathbb {D}_{i-1}(t)\) contains elements that are greater than or equal to \(v_{i-1}\). After merging by setting \(v_i=v_{i-1}, \mathbb {G}_i = \mathbb {G}_{i-1}\cup \mathbb {G}_i, \mathbb {D}_i=\mathbb {D}_{i-1}\), the set in the statement becomes \(\cup _{j>i} \mathbb {G}_j(t){\setminus } \mathbb {D}_{i-1}(t)\), which is a subset of \(\cup _{j>{i-1}} \mathbb {G}_j(t){\setminus } \mathbb {D}_{i-1}(t)\). Therefore all elements in it are greater than or equal to \(v_{i-1}\) after merging. \(\square \)
Lemma 12
At all time t, for all i, at least \(1-\epsilon _2'\) fraction of elements in the set \(\cup _{j\le i} \mathbb {G}_j(t)\) have values less than or equal to \(\max _{j\le i} v_j(t)\).
Proof
For each individual \(\mathbb {G}_{j}(t)\), by the property of tracking approximate maximum by our EH sketch \(G_j\), \(1-\epsilon _2'\) fraction of the elements in \(\mathbb {G}_j(t)\) are less than \(v_j(t)\).
Taking union over \(\mathbb {G}_j(t)\) and maximum over \(v_j(t)\), we obtain the lemma. \(\square \)
Theorem 5
Correctness of Quantile: The query procedure returns a value v with rank between \((q-(\epsilon _1+2\epsilon _2'))W\) and \((q+(\epsilon _1+2\epsilon _2'))W\).
Proof
We maintain the invariant: at all time t, for all i
The function \(\mathtt{{QUAN}}\mathtt{{TILE}}\) returns \(v = \max _{j\le i} v_i(t)\), where i is the minimum index such that \(\sum _{j\le i} g_j(t) \ge (q-\epsilon _1)W\). Suppose \(v = v_p\), \(p\le i\).
By Lemma 12, there are at least \((1-\epsilon _2') \sum _{j\le i} |\mathbb {G}_j(t)|\) elements less than or equal to \(v_i(t)\) (and hence v). Now
Therefore v has minimum rank of \((q - (\epsilon _1+2\epsilon _2'))W\).
By Lemma 11, there are at least \(\sum _{j>p} |G_j(t)| - |D_p(t)|\) elements greater than or equal to \(v = v_p\). The maximum rank of v is
The inequality from the third last line comes from the invariant in Eq. 10 and the fact that \(i\ge p\) is the minimum index with \(\sum _{j\le i} g_j(t) \ge (q-\epsilon _1)W\), so \(\sum _{j<p} g_j(t)\) has to be strictly less than \((q-\epsilon _1)W\). Therefore \(v=v_p\) has maximum rank of \((q+(\epsilon _1+2\epsilon _2'))W\). Together with the minimum rank of v, this shows v gives an \((\epsilon _1+2\epsilon _2')\)-approximation to the quantile query problem on the qth quantile. \(\square \)
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Yu, CN., Crouch, M., Chen, R., Sala, A. (2016). Online Algorithm for Approximate Quantile Queries on Sliding Windows. In: Goldberg, A., Kulikov, A. (eds) Experimental Algorithms. SEA 2016. Lecture Notes in Computer Science(), vol 9685. Springer, Cham. https://doi.org/10.1007/978-3-319-38851-9_25
Download citation
DOI: https://doi.org/10.1007/978-3-319-38851-9_25
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-38850-2
Online ISBN: 978-3-319-38851-9
eBook Packages: Computer ScienceComputer Science (R0)