
Abstract
The goal of this work is to automatically detect and classify a set of geoenvironmental zones of interest in panchromatic aerial images. Focused on a specific area, the zones to be detected are vegetation/mangrove, degradation/desertification, interface water-sediment and plain. These zones are very interesting from a geological point of view due to their spatial distribution and interrelation, which contribute to evaluate the natural anthropic impact level. The approach to unsupervisedly extract these zones from an input image has two steps. Firstly, the image is automatically segmented in homogeneous colored regions using the Bounded Irregular Pyramid (BIP). The BIP is a hierarchy of successively reduced graphs which produces accurate segmentation results with a low computational cost. Secondly, each obtained region is classified using texture features to determine if it belongs to one of the geoenvironmental zones of interest. As texture features, we have evaluated two variations of the Local Binary Pattern (LBP) descriptor: the Extended-LBP (ELBP) and the LBP variance (LBPV). Both methods include a local contrast measure. For classifying the obtained features, the Support Vector Machine (SVM) has been employed. At this stage, we have evaluated the use of linear and radial basis function (RBF) kernels. The whole framework was tested using images obtained from our specific area of interest: the location of Carenero, Miranda state (Venezuela), in years 1936 and 1992. They allow to study the variation of the geoenvironmental zones of interest of this location in this period of time. These images are low quality images and present significant variations in illumination. This makes difficult the texture classification of their zones. However, the obtained results show that the proposed approach provides good results in terms of identification of zones of geoenviromental interest in these images.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The study of the anthropic impact produced in a given area is a key issue in geology. For this purpose, aerial and satellite images are being widely used to obtain qualitative and quantitative geologic information [1, 2] because they are non-invasive methods which allow to work in areas of difficult access. To do that, and depending on the geological features of the area to be studied, different geoenvironmental zones and their evolution over the time need to be studied. However, when the goal of an image processing algorithm is to divide the input image in a manner similar to human beings, the adopted strategy cannot simply be the grouping of image pixels into clusters (regions or boundaries) taking into account low-level photometric properties. Aerial and satellite images are generally composed of physically disjoint regions whose associated groups of image pixels may not be visually uniform. Hence, it is very difficult to formulate what should be recovered as a region or boundary or to segment complex regions from the image. With the aim of organizing low-level image features into higher level relational structures, the perceptual organization of the image content is usually thought as a process of grouping visual information into a hierarchy of levels of abstraction. Starting from the lower level of the hierarchy (i.e. the input image or an initial partition), each new layer groups the regions of the level below into a reduced set of regions. This grouping needs to define a region model (the features that describe each image region) and a dissimilarity measure (the metric on those features). This paper proposes a texture-based automatic system to identify a predefined set of geonvironmental zones in panchromatic aerial images. This system is divided in two steps: a pre-segmentation stage that accumulates local evidences from the original image to a single graph. This graph will encode a decomposition of the image into superpixels. This initial stage of the clustering process is guided by the principles described by Levinshtein et al. [11]. Thus, blobs represent connected sets of pixels without overlapping among them. They are compact and their boundaries coincide with the main image edges when the pre-segmentation stops. Then, a second stage categorizes the previously obtained blobs into a reduced set of perceptually significant classes. This stage characterizes every blob using a texture feature and then classifies them into one of a collection of predefined zones. The performance of the texture-based classification scheme has been evaluated using the Banja Luka dataset to measure its ability to deal with real images. After confirming the validity of this stage, the whole system has been applied to the detection and classification of vegetation/mangrove, degradation/desertification, interface water-sediment and plain zones in panchromatic aerial images captured in years 1936 and 1992 in the location of Carenero, Miranda state (Venezuela).
The rest of the paper is organized as follows: Sect. 2 provides an overview of the whole approach and describes how both stages are implemented. Experimental results showing the performance of the approach are presented at Sect. 3. Section 4 draws the conclusions and future work.
2 Proposed Method
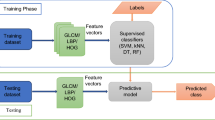
Figure 1 provides an overview of the proposed method. In the pre-segmentation stage, the Bounded Irregular Pyramid [7] has been used for segmenting an equalized version of the input image. Instead of performing image segmentation based on a single representation of the input image, a pyramid segmentation algorithm describes the contents of the image using multiple representations with decreasing resolution. In this hierarchy, each representation or level is built by computing a set of local operations over the level below, being the original image the level 0 or base level of the hierarchy. Pyramid segmentation algorithms exhibit interesting properties with respect to segmentation algorithms based on a single representation. Thus, local operations can adapt the pyramidal hierarchy to the topology of the image, allowing the detection of global features of interest and representing them at low resolution levels. The pre-segmentation divides up the input image into a collection of non-overlapping blobs. These blobs are characterized using two variations of the Local Binary Pattern (LBP) descriptor: the Extended-LBP (ELBP) and the LBP variance (LBPV) [6]. For classifying the blobs as belonging to an specific environmental zone, the Support Vector Machine (SVM) has been employed using linear and radial basis function (RBF) kernels.

Overview of the proposed method
2.1 Pre-segmentation Stage
After equalizing the input image, it is divided up into regions using a specific implementation of the Bounded Irregular pyramid (BIP). The BIP is an irregular, hierarchical procedure for image segmentation. For obtaining a new level from the level below, the BIP combines a regular and an irregular decimation procedures. The final result is the encoding of the image’s content as a hierarchy of simple graphs [7]. Using this scheme, the BIP is able to obtain similar segmentation results to other irregular pyramids but in a faster way. Next, we describe the properties and metric employed for building the hierarchy and the decimation process.
Data Structure: Image Features and Metrics. Let \(G_{l}=(N_l,E_l)\) be a hierarchy level where \(N_l\) stands for the set of regular and irregular nodes and \(E_l\) for the set of intra-level arcs. Let \(\xi _{\mathbf {x}}\) be the neighborhood of the node \(\mathbf {x}\) defined as \(\{\mathbf {y} \in N_l : (\mathbf {x},\mathbf {y}) \in E_l \}\). It can be noted that a given node \(\mathbf {x}\) is not a member of its neighborhood, which can be composed by regular and irregular nodes. Each node \(\mathbf {x}\) has associated a \(\mathbf {v}_{\mathbf {x}}\) value given by the averaged brightness of the image pixels linked to \(\mathbf {x}\). Besides, each regular node has associated a boolean value \(h_{\mathbf {x}}\): the homogeneity [7]. Only regular nodes which have \(h_{\mathbf {x}}\) equal to 1 are considered to be part of the regular structure. Regular nodes with an homogeneity value equal to 0 are not considered for further processing. At the base level of the hierarchy \(G_0\), all nodes are regular, and they have \(h_{\mathbf {x}}\) equal to 1. In order to divide the image into a set of homogeneous blobs, the graph \(G_l\) is transformed in \(G_{l+1}\) using a pairwise comparison of neighboring nodes. At the first levels of the hierarchy, the pairwise comparison function, \(g(\mathbf {v}_{{\mathbf {x_1}}},\mathbf {v}_{{\mathbf {x_2}}})\), is true if the Euclidean distance between the HSV values \(\mathbf {v}_{{\mathbf {x}}_1}\) and \(\mathbf {v}_{{\mathbf {x}}_2}\) is under an user–defined threshold \(\sigma _{color}\). When the hierarchy reaches level \(l_m\) and it is not possible to perform new mergings, the algorithm automatically changes the metric to add to the process the edge information. For this end, the roots of the blobs at level \(l_m\) constitute the first level of the new multiresolution output. Let \(\mathcal {P}_{l_m}\) be the image partition at level \(l_m\) and \(l > l_m \in \mathfrak {R}\) a level of the hierarchy, this second grouping process assigns a partition \(\mathcal {Q}_l\) to the couple \((\mathcal {P}_{l_m},l)\), satisfying that \(\mathcal {Q}_{l_m}\) is equal to \(\mathcal {P}_{l_m}\) and that
That is, the grouping process is iterated until the number of nodes remains constant between two successive levels. In order to achieve the grouping process, a perceptual pairwise comparison function must be defined. In this case, the pairwise comparison function \(g(\mathbf {v}_{{\mathbf {y_i}}}, \mathbf {v}_{{\mathbf {y_j}}})\) is implemented as a thresholding process, i.e. it is true if a distance measure between both nodes is under a given threshold \(\sigma _{percep}\), and false otherwise. The defined distance integrates edge and region descriptors. Thus, it has two main components: the color contrast between image blobs and the edges of the original image computed using the Canny detector. In order to speed up the process, a global contrast measure is used instead of a local one. It allows to work with the nodes of the current working level, increasing the computational speed. This contrast measure is complemented with internal regions properties and with attributes of the boundary shared by both regions. The distance between two nodes \(\mathbf {y}_i \in N_l\) and \(\mathbf {y}_j \in N_l\), \(\varphi ^{\alpha }(\mathbf {y}_i,\mathbf {y}_j)\), is defined as
where \(d(\mathbf {y}_i,\mathbf {y}_j)\) is the gray-level distance between \(\mathbf {y}_i\) and \(\mathbf {y}_j\). \(b_{\mathbf {y}_i}\) is the perimeter of \(\mathbf {y}_i\), \(b_{\mathbf {y}_i \mathbf {y}_j}\) is the number of pixels in the common boundary between \(\mathbf {y}_i\) and \(\mathbf {y}_j\) and \(c_{\mathbf {y}_i \mathbf {y}_j}\) is the set of pixels in the common boundary which corresponds to pixels of the edge detected by the Canny detector. \(\alpha \) and \(\beta \) are two constant values used to control the influence of the Canny edges in the grouping process. They should be manually tuned depending on the application and environment.
The Decimation Process. The decimation algorithm runs two consecutive steps to obtain the set of nodes \(N_{l+1}\) from \(N_l\). The first step generates the set of regular nodes of \(G_{l+1}\) from the regular nodes at \(G_{l}\) and the second one determines the set of irregular nodes at level l+1. This second process employs a union-find process which is simultaneously conducted over the set of regular and irregular nodes of \(G_{l}\) which do not present a parent in the upper level \(l+1\). The decimation process consists of the following steps:
-
1.
Regular decimation process. The \(h_{\mathbf {x}}\) value of a regular node \(\mathbf {x}\) at level l+1 is set to 1 if the four regular nodes immediately underneath \(\{\mathbf {y}_i\}\) are similar and their \(h_{\{\mathbf {y}_i\}}\) values are equal to 1. That is, \(h_{\mathbf {x}}\) is set to 1 if
$$\begin{aligned} \{\bigcap _{\forall \mathbf {y}_j,\mathbf {y}_k \in \{\mathbf {y}_i\}} g(\mathbf {v}_{{\mathbf {y}}_j},\mathbf {v}_{{\mathbf {y}}_k}) \} \cap \{\bigcap _{\mathbf {y}_j \in \{\mathbf {y}_i\}}h_{\mathbf {y}_j} \} \end{aligned}$$(3)Besides, at this step, inter-level arcs among regular nodes at levels l and l+1 are established. If \(\mathbf {x}\) is an homogeneous regular node at level l+1 (\(h_{\mathbf {x}}\)==1), then the set of four nodes immediately underneath \(\{\mathbf {y_i}\}\) are linked to \(\mathbf {x}\).
-
2.
Irregular decimation process. Each irregular or regular node \(\mathbf {x} \in N_l\) without parent at level l+1 chooses the closest neighbor \(\mathbf {y}\) according to the \(\mathbf {v}_{\mathbf {x}}\) value. Besides, this node \(\mathbf {y}\) must be similar to \(\mathbf {x}\). That is, the node \(\mathbf {y}\) must satisfy
$$\begin{aligned} \{||\mathbf {v}_{\mathbf {x}}-\mathbf {v}_{\mathbf {y}}||=\min (||\mathbf {v}_{\mathbf {x}}-\mathbf {v}_{\mathbf {z}}||: \mathbf {z} \in \xi _{\mathbf {x}} ) \} \cap \{ g(\mathbf {v}_{\mathbf {x}},\mathbf {v}_{\mathbf {y}})\} \end{aligned}$$(4)If this condition is not satisfy by any node, then a new node \(\mathbf {x}'\) is generated at level l+1. This node will be the parent node of \(\mathbf {x}\). Besides, it will constitute a root node and the set of nodes linked to it at base level will be an homogeneous set of pixels according to the defined criteria. On the other hand, if \(\mathbf {y}\) exists and it has a parent \(\mathbf {z}\) at level l+1, then \(\mathbf {x}\) is also linked to \(\mathbf {z}\). If \(\mathbf {y}\) exists but it does not have a parent at level l+1, a new irregular node \(\mathbf {z}'\) is generated at level l+1. In this case, the nodes \(\mathbf {x}\) and \(\mathbf {y}\) are linked to \(\mathbf {z}'\). This process is sequentially performed and, when it finishes, each node of \(G_l\) is linked to its parent node in \(G_{l+1}\). That is, a partition of \(N_l\) is defined. It must be noted that this process constitutes an implementation of the union-find strategy [7].
-
3.
Definition of intra-level arcs. The set of edges \(E_{l+1}\) is obtained by defining the neighborhood relationships between the nodes \(N_{l+1}\). Two nodes at level l+1 are neighbors if their reduction windows, i.e. the sets of nodes linked to them at level l, are connected at level l.
2.2 Texture Classification
Texture Descriptors. The Local Binary Pattern (LBP) descriptor, originally proposed in [8] is a computational very simple algorithm which main advantage is its robustness against illumination variations. The original LBP operator forms labels for the image pixels by thresholding the \(3\times 3\) neighborhood of each pixel with the center value and considering the result as a binary number. This binary number is set to 1 if the neighbor is greater or equal than the central pixel and it is set to 0 in other case. The histogram of these \(2^8 = 256\) different labels can then be used as a texture descriptor (Fig. 2). This descriptor was extended (ELBP) in [9] to use circular neighborhoods of different radius.

Schematic description of the LBP approach
A formal description of the ELBP operator is shown in the following equation:
where \((x_c, y_c)\) is the central pixel with an intensity value of \(g_c\), \(g_p\) is the intensity of the neighbor pixel, P is the number of pixels, R the used radius and s(x) is a function with the form:
When a radius different of one is used, the neighbors are located in a circle with the center in the studied pixel. If a point of the circle does not correspond to an image pixel, it is interpolated.
In order to include local contrast information into the LBP descriptor and make it rotation invariant, Guo et al. [6] present the Local Binary Pattern Variance descriptor (LBPV).
In this work, we have used the ELBP and the LBPV descriptors to characterize all nodes of the highest level of the hierarchy, \(\mathbf {x} \in N_{l_h}\). The irregular shape is not a problem as the descriptor is locally computed for each pixel. Furthermore, contrary to what is done in other works, we divide up the receptive field of \(\mathbf {x}\) into a grid of m regions. In each of these regions the descriptor is computed, having one histogram per region. These m histograms are concatenated, obtaining the final feature vector associated to the node. Both descriptors are evaluated at Sect. 3.
Classification. Once the texture of the nodes \(\mathbf {x} \in N_{l_h}\) has been captured, the final step of the approach aims to categorize these nodes into a set of classes. To perform this step, the Support Vector Machine (SVM) classifier has been selected. Given a set of patterns where each pattern belongs to one of two possible classes, the goal of the SVM is to provide a model for classifying any new pattern. Basically, this model defines a separating hyperplane in the space of the patterns that maximizes the margin between the two classes. Training a SVM consists of finding the optimal hyperplane, that is, the one with the maximum distance from the nearest training patterns, called support vectors. However, it is not always possible to find a perfect separation. Otherwise the result of the model cannot be generalized for other incoming data. This problem is known as overfitting. In order to deal with it, the SVM uses an internal parameter, C, which controls the compensation between training errors and the rigid margins.
Whereas the easiest way to make the separation between classes is using a straight line, a plane or a n-dimensional hyperplane, it often happens that the sets to discriminate are not linearly separable in that space. To solve this issue, one solution is to map the original space into a higher-dimensional space, and to look for this hyperplane within this new space. This mapping is typically performed using a kernel function k(x, y). Thus, the SVM classifier has the following form:
being \(K(x,x_i)\) the kernel function.
In the proposed work, two different kernel functions have been used: the polynomial and the Gaussian radial basis function.
3 Experimental Results
This section includes the verification of the texture description and classification stages and the validation of the whole system. For the first issue we have used a publicly available database of aerial images: the Banja Luka databaseFootnote 1. The whole system has been tested using a collection of images from our specific area of interest, located at Carenero, Miranda state (Venezuela). These images were taken at 1936 and 1992. This will allow to analyze the anthropic impact produced in this area.
Banja Luka Database. The Banja Luka database contains 606 images of 128\(\times \)128 pixels, which were manually classified into 6 classes: houses, cemetery, industry, field, river and trees. The distribution of images in these categories is highly uneven [3]. Figure 3 shows several images from the database. Panchromatic versions of these images were used for testing. Table 1 shows the performance (mean classification accuracy and standard deviation) provided by different approaches. In these experiments, half of the images were used for training and the other half for testing. All approaches use SVM with radial basis function kernel. Gabor descriptors were computed at 8 scales and 8 orientations for all images, providing 128-dimensional vectors. Gabor (full) employs a Gabor descriptor composed by the means and standard deviations of all filter responses, while Gabor (mean) implies to use a descriptor obtained using only mean values. The Gist descriptor [4] was computed by first filtering the image by a filter bank of Gabor filters, and then averaging the responses of filters in each block on a 4 \(\times \) 4 non-overlapping grid. The approach proposed by Lingua et al. [5] is used to provide the MSIFT results. The BoW descriptor [10] is obtained by computing SIFT descriptors on a regular grid and vector quantizing them using a codebook with 1000 codewords. Histogram of codeword occurrences is a 1000-dimensional BoW image descriptor. It can be noted that the proposed framework provides better results than these approaches.

Examples of classes in the Banja Luka database
Carenero Database. This database is formed by panchromatic aerial images captured in the Carenero zone by the Geographical Institute of Venezuela (Simón Bolívar) in the years 1936 and 1992. Their scale is 1:25.000 and they have been geocited with dimensions of 675x471 pixels. The goal of this experiment is to locate in these images the following zones: vegetation/mangrove, degradation/desertification, interface water-sediment and plain. For each class, 85 images of 40x40 pixels was manually obtained for training. Figure 4 shows one example of each category.

Categories of texture samples in the Carenero database

(a) Original image from Carenero 1936, (b) image decomposition provided by the BIP approach, and (c) blobs associated to interface water-sediment (blue regions), plain (green regions), desertification (red regions) and the mangrove (yellow regions) (see text) (Color figure online).
The pre-segmentation using the BIP algorithm depends on two threshold values: \(\sigma _{color}\) and \(\sigma _{percep}\). The best results on the Caranero 1936 dataset were obtained using as threshold values \(\sigma _{color}\)=80 and \(\sigma _{percep}\)=90. But for Caranero 1992, the best values were \(\sigma _{color}\)=30 and \(\sigma _{percep}\)=50. There are a significant difference on their values, but it must be noted that these images were captured using two different sensors. Similar comments could be given respect to the parameters \(\alpha \) and \(\beta \) used for weighting the impact between color contrast and edge information (typical values give more weight to color contrast).
Figure 5 shows the regions obtained by pre-segmenting one of the original images from Carenero 1936. The size of some of them are large and can be characterized by the ELBP-LBPV method. Other ones have got a small size and cannot be correctly characterized. They will remain as unclassified. Figure 5(c) shows the blobs that have been labeled by the approach as interface water-sediment (blue regions), plain (green regions), desertification (red regions) and the mangrove (yellow regions). The classifier uses the SVM model with a RBF kernel.
The global thematic accuracy, measured as a classification percentage, reached a value of 92,50 %. Besides, it was counted on the cross validation to identify the tuning parameters, for the radial gamma kernel (\(\gamma \)), in the linear kernel degree and C. Table 2 shows the performance (mean classification accuracy and standard deviation) for classes on Carenero 1936 and Carenero 1992 databases. Figure 6 shows the average accuracy for all texture classes on the Carenero 1992 dataset. It should be noted that the results are really good for several combinations of parameters. There are however problems for classifying the desertification areas. It can be also noted that there does not exist a pair of parameters that can provide the best results for all classes.
The method is however considering that boundaries of the zones are abrupt, i.e. that there do not exist gradual transitions between zones. This problem is present on the images and we will need to work on how to deal with. Other approaches [13] use the (multiple) indicator kriging for take these gradual transitions into account. In our case, it will be necessary to include the uncertainty information within the categorization stage, providing for each region not only the category but also the probability associated to this process.

Accuracy values for different geoenvironmental zones (Carenero 1992): vegetation/mangrove (V/M), degradation/desertification (D), interface water-sediment (I/W-S) and plain (P)
4 Conclusion
The main contribution of this paper is the evaluation of a whole framework for segmentation and classification of the regions composing an aerial image. The BIP approach is used for pre-segmenting the input image, providing a decomposition of the scene within uniform blobs. These blobs are arranged as a single graph, where simple adjacency relationships are encoded on the arcs of the graph. Then, these blobs are successfully categorized using texture. Regarding to this last stage, the proposed system is able to obtain better results than other popular approaches on the large Banja Luka dataset. Furthermore, the whole framework is able to deal with the automatic decomposition and labeling of complex, real images. Future work will focus on integrating within the framework the tools that can allow the user to easily redraw the segmentation and/or classification results (e.g. changing a provided label or choosing a lower level of decomposition for a specific region). We have also experience on introducing topological information within the hierarchical segmentation of natural images, changing the single graph by a combinatorial map [12]. This topological information will allow to consider inclusion and complex adjacency relationships, which could be useful to describe the geological evolution of the analyzed geoenvironmental area.
Notes
References
Sulong, I., Mohd-Lokman, H., Mohd-Tarmizi, K., Ismail, A.: Mangrove mapping using landsat imagery and aerial photographs: Kemaman district, Terengganu, Malaysia. Environ. Dev. Sustain. 4(2), 135–152 (2002)
Hirche, A., Salamani, M., Abdellaoui, A., Benhouhou, S., Valderrama, J.M.: Landscape changes of desertification in arid areas: the case of south-west Algeria. Environ. Monit. Assess. 179(1–4), 403–420 (2011)
Risojevic, V., Momic, S., Babic, Z.: Gabor descriptors for aerial image classification. In: Adaptive and Natural Computing Algorithms, pp. 51–60 (2011)
Oliva, A., Torralba, A.: Modeling the shape of the scene: a holistic representation of the spatial envelope. Int. J. Comput. Vis. 42(3), 145–175 (2001)
Lingua, A., Marenchino, D., Nex, F.: Performance analysis of the SIFT operator for automatic feature extraction and matching in photogrammetric applications. Sensors 9(5), 3745–3766 (2009)
Guo, Z., Zhang, L., Zhang, D.: Rotation invariant texture classification using LBP Variance (LBPV) with global matching. Pattern Recogn. 43, 706–719 (2010)
Marfil, R., Bandera, A.: Comparison of perceptual grouping Criteria within an integrated hierarchical framework. In: Torsello, A., Escolano, F., Brun, L. (eds.) GbRPR 2009. LNCS, vol. 5534, pp. 366–375. Springer, Heidelberg (2009)
Ojala, T., Pietikäinen, M., Harwood, D.: A comparative study of texture measures with classification based on feature distributions. Pattern Recogn. 19(3), 51–59 (1996)
Ojala, T., Pietikäinen, M.: Multirresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 24(7), 971–987 (2002)
Yang, Y., Newsam, S.: Bag-of-visual-words and spatial extensions for land-use classification. In: Proceedings of the ACM SIGSPATIAL GIS, pp. 270–279 (2010)
Levinshtein, A., Stere, A., Kutulakos, K., Fleet, D., Dickinson, S., Siddiqi, K.: Turbopixels: fast superpixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 31(12), 2290–2297 (2009)
Antnez, E., Marfil, R., Bandera, J.P., Bandera, A.: Part-based object detection into a hierarchy of image segmentations combining color and topology. Pattern Recogn. Lett. 34(7), 744–753 (2013)
Hengl, T., Toomanian, N., Reuter, H., Malakouti, M.: Methods to interpolate soil categorical variables from profile observations: Lessons from Iran. Geoderma 140, 417–427 (2007)
Acknowledgments
This paper has been partially supported by the Spanish Ministerio de Economía y Competitividad TIN2015-65686-C5 and FEDER funds.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Calderón, M., Marfil, R., Bandera, A. (2016). Segmentation and Classification of Geoenvironmental Zones of Interest in Aerial Images Using the Bounded Irregular Pyramid. In: Bac, A., Mari, JL. (eds) Computational Topology in Image Context. CTIC 2016. Lecture Notes in Computer Science(), vol 9667. Springer, Cham. https://doi.org/10.1007/978-3-319-39441-1_26
Download citation
DOI: https://doi.org/10.1007/978-3-319-39441-1_26
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-39440-4
Online ISBN: 978-3-319-39441-1
eBook Packages: Computer ScienceComputer Science (R0)
