
Abstract
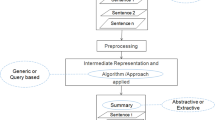
This paper focuses on continuous news documents and presents a method for extractive multi-document summarization. Our hypothesis about salient, key sentences in news documents is that they include words related to the target event and topic of a document. Here, an event and a topic are the same as Topic Detection and Tracking (TDT) project: an event is something that occurs at a specific place and time along with all necessary preconditions and unavoidable consequences, and a topic is defined to be “a seminal event or activity along with all directly related events and activities.” The difficulty for finding topics is that they have various word distributions. In addition to the TF-IDF term weighting method to extract event words, we identified topics by using two models, i.e., Moving Average Convergence Divergence (MACD) for words with high frequencies, and Latent Dirichlet Allocation (LDA) for low frequency words. The method was tested on two datasets, NTCIR-3 Japanese news documents and DUC data, and the results showed the effectiveness of the method.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Allan, J., Carbonell, J., Doddington, G., Yamron, J., Yang, Y.: Topic detection and tracking pilot study final report. In: Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop (1998)
Allan, J.: Topic Detection and Tracking. Kluwer Academic Publishers, USA (2003)
Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent Dirichlet allocation. J. Mach. Learn. Res. 3, 993–1022 (2003)
Carbonell, J., Goldstein, J.: The use of MMR, diversity-based reranking for reordering documents and producing summaries. In: Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 335–336 (1998)
Celikylmaz, A., Hakkani-Tur, D.: A hybird hierarchical model for multi-document summarization. In: Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pp. 815–824 (2010)
Celikylmaz, A., Hakkani-Tur, D.: Discovery of topically coherent sentences for extractive summarization. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pp. 491–499 (2011)
Conroy, J.M., Schlesinger, J.D., O’Leary, D.P.: Topic-focused multi-document summarization using an approximate oracle score. In: Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, pp. 152–159 (2006)
Erkan, G., Radev, D.: LexPageRank: prestige in multi-document text summarization. In: Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, pp. 365–371 (2004)
Folino, G., Pizzuti, C., Spezzano, G.: An adaptive distributed ensemble approach to mine concept-drifting data streams. In: Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence, pp. 183–188 (2007)
Harabagiu, S., Hickl, A., Lacatusu, F.: Satisfying information needs with multi-document summaries. Inf. Process. Manag. 43(6), 1619–1642 (2007)
Hatzivassiloglou, V., Klavans, J.L., Holcombe, M.L., Barzilay, R., Kan, M.-Y., McKeown, K.R.: Simfinder: a flexible clustering tool for summarization. In: Proceedings of the 2nd Meeting of the North American Chapter of the Association for Computational Linguistics Workshop on Text Summarization, pp. 41–49 (2001)
He, D., Parker, D.S.: Topic dynamics: an alternative model of bursts in streams of topics. In: Proceedings of the SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 443–452 (2010)
Kleinberg, J.M.: Bursty and hierarchical structure in streams. In: Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 91–101 (2002)
Lazarescu, M.M., Venkatesh, S., Bui, H.H.: Using multiple windows to track concept drift. Intell. Data Anal. 8(1), 29–59 (2004)
Li, W., McCallum, A.: Pachinko allocation: dag-structure mixture model of topic correlations. In: Proceedings of the 23rd International Conference on Machine Learning, pp. 577–584 (2006)
Lin, C.-Y., Hovy, E.H.: From single to multi-document summarization: a prototype system and its evaluation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 457–464 (2002)
Marcu, D., Echihabi, A.: An unsupervised approach to recognizing discourse relations. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 368–375 (2002)
Mihalcea, R., Tarau, P.: Language independent extractive summarization. In: Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics, pp. 49–52 (2005)
Mimno, D., Li, W., McCallum, A.: Mixtures of hierarchical topics with pachinko allocation. In: Proceedings of the 24th International Conference on Machine Learning, pp. 633–640 (2007)
Murphy, J.: Technical Analysis of the Financial Markets. Prentice Hall, Upper Saddle River (1999)
Klinkenberg, R., Joachims, T.: Detecting concept drift with support vector machines. In: Proceedings of the 17th International Conference on Machine Learning, pp. 487–494 (2000)
Page, L., Brin, S., Motwani, R., Winograd, T.: The Pagerank Citation Ranking: Bringing Order to the Web. Technical report, Stanford Digital Libraries (1998)
Ramage, D., Hall, D., Nallapati, R., Manning, C.D.: Labeled LDA: a supervised topic model for credit attribution in multi-labeled corpora. In: Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, pp. 248–256 (2009)
Schmid, H.: Improvements in part-of-speech tagging with an application to German. In: Proceedings of the European Chapter of the Association for Computational Linguistics SIGDAT Workshop, pp. 47–50 (1995)
Toutanoval, K., Brockett, C., Gammon, M., Jagarlamudi, J., Suzuki, H., Vanderwende, L.: The phthy summarization system: Microsoft research at DUC. In: Proceedings of Document Understanding Conference (2007)
Yan, X., Guo, J., Lan, Y., Cheng, X.: A biterm topic model for short texts. In: Proceedings of the 22nd International Conference on World Wide Web, pp. 1445–1456 (2013)
Wan, X., Yang, J.: Multi-document summarization using cluster-based link analysis. In: Proceedings of the SIGIR Conference on Research and Development in Information Retrieval, pp. 299–306 (2008)
Wang, C., Blei, D., Heckerman, D.: Continuous time dynamic topic models. In: Proceedings of the 24th Conference on Uncertainty in Artificial Intelligence, pp. 579–586 (2008)
Zhu, Y., Shasha, D.: Efficient elastic burst detection in data streams. In: Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 336–345 (2003)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Fukumoto, F., Suzuki, Y., Takasu, A., Matsuyoshi, S. (2016). Identification of Event and Topic for Multi-document Summarization. In: Vetulani, Z., Uszkoreit, H., Kubis, M. (eds) Human Language Technology. Challenges for Computer Science and Linguistics. LTC 2013. Lecture Notes in Computer Science(), vol 9561. Springer, Cham. https://doi.org/10.1007/978-3-319-43808-5_23
Download citation
DOI: https://doi.org/10.1007/978-3-319-43808-5_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-43807-8
Online ISBN: 978-3-319-43808-5
eBook Packages: Computer ScienceComputer Science (R0)