
Abstract
Urban data management is already an essential element of modern cities. The authorities can build on the variety of automatically generated information and develop intelligent services that improve citizens daily life, save environmental resources or aid in coping with emergencies. From a data mining perspective, urban data introduce a lot of challenges. Data volume, velocity and veracity are some obvious obstacles. However, there are even more issues of equal importance like data quality, resilience, privacy and security. In this paper we describe the development of a set of techniques and frameworks that aim at effective and efficient urban data management in real settings. To do this, we collaborated with the city of Dublin and worked on real problems and data. Our solutions were integrated in a system that was evaluated and is currently utilized by the city.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Technological advancement led to the generation of massive amounts of data originating from a variety of urban sources. Smart cities equipped with the appropriate infrastructure are producing many gigabytes of information on a daily basis and data sources range from static to dynamic sensors. Examples include GPS trajectory traces, aggregated logs of mobile phone activity as well as user generated content from social media. Such data variety offers the potential for novel applications that support decision making in multiple situations.
Interestingly enough, the nature of smart city data brings a lot of challenges to data mining researchers and practitioners. Data volume and velocity impose great challenges in performing any type of analysis in real time. On top of that, data veracity hinders many sophisticated learning algorithms. Data quality issues demand extra attention in the case of smart cities and the challenges extend even further to resilience issues, data privacy and security. More specifically, tools established in smart cities need to address the following challenges:
-
(i)
Identify events in real-time: Exploring and detecting events of interest from complex and voluminous urban data streams is extremely challenging [41]. Urban sensors are transmitting ambiguous and contradictory information. In such occasions exploiting the wisdom of the crowd through crowdsourcing is necessary. Furthermore the incoming stream may be massive requiring efficient online solutions. For example, in Twitter, thousands of tweets per second need to be processed in order to identify a few that are relevant to the task.
-
(ii)
Handle varying loads: In the city setting, data loads deviate significantly over time. During rush hours many vehicles send out position information, while during the night the load is significantly lower. Twitter follows similar ‘normality’ patterns and significant events are correlated with large number of tweets.
-
(iii)
Noisy data and erroneous measurements: Very often sensors report faulty measurements due to miss-calibration or hardware problems. For example we observed that bus data from Dublin had many inaccuracies: buses reported erroneous locations, extreme vehicle speed, irrationally high delays, and more. All these issues hamper data exploration and analysis. Moreover, Twitter due to informal and short text hinders language processing algorithms.

DCC’s traffic control center, INSIGHT system shown at middle top screen.
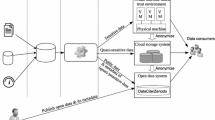
In this work we discuss the above challenges inherent in urban data. We then describe the provided solutions in the context of the city of Dublin, where we have collaborated on real problems and data. The application we targeted is the intelligent urban data management for event detection and emergency response. Dublin City Council operates a Traffic Management Center analyzing information from multiple sources like buses moving around the city or measurements of traffic flow in junctions. However, their work-flow is hindered by the data volume and the raw data that it are difficult to interpret.
We provide with a number of novel modules specifically designed to detect multiple types of incidents. These components use state of the art event detection techniques and are built with the focus on scalability and efficiency. They are generic and can be utilized in multiple settings analyzing in real-time GPS trajectories, data coming from sensors installed in junctions, or social media textual information. Specifically, we present:
-
(a)
a dynamically scalable pipeline for streaming data (Sect. 3.1),
-
(b)
an adaptive monitoring framework for social media such as twitter, which optimises recall of traffic related information (Sect. 3.2),
-
(c)
an efficient crowdsourcing system for collecting urban data and for minimizing uncertainty (Sect. 3.3).
Through multiple feedback loops of the development process, expert knowledge was integrated in order to improve functionality, tuning appropriately the parameters. We report on the integration of the above techniques into a system that addresses information comprehensibility and it is useful for the end user. The components were evaluated within the work flow of Dublin City’s Traffic Management team where the system INSIGHT [18] is established (see Fig. 1).
2 Related Work
The first architectures and technological innovations on the area of smart cities were built in the early 90s. Early framework examples include the AOL cities, a virtual simulation environment, and the first digital cities Kyoto and Amsterdam [33]. Years later many projects that aim at urban data analysis and solutions were developed by utilizing distributed sensors. The Ubiquitous Sensor Network proposed in [16] is an architecture where decentralized and geographically diverse sensors across the city are aggregated in a central database (IoT). Similarly the SOFIA architecture [13] was built with the purpose of an ecosystem of heterogeneous sensors, devices and appliances.
Nowadays, many cities use real-time analysis mechanisms to measure city functionality. IBM in partnership with the government of Brazil built a system for the city of Rio De Janeiro that aggregates multiple streams and combines them in a control center where algorithms analyze the data in real time, describe the state of the city and inform operators about disastrous events such as floods. The authors in [3] suggest a similar real-time architecture for managing city-wide critical equipment detecting faults. For example a fault could be an electricity distribution failure. According to [39] urban management can be also used for a greener environment. Their proposed system aims to ensure that the environmental policies, set up by the city, are satisfied (e.g. levels of \(CO_2\)). The system is used in many cities including Barcelona and Edinburgh.
In recent years many algorithms have been proposed that aim to analyze and extract information from urban data. The authors in [29] proposed an algorithm that detects anomalous traffic behaviour analyzing GPS data from taxis in Beijing. A traffic event detection approach using k-means algorithm was presented in [26]. The authors in [9] used time varying scalar functions in order to detect events from urban data. The detection of users’ transportation mode, using their GPS trajectories along with information regarding the road network was presented in [34]. In [22] the authors describe a holistic technique that uses a hierarchical Markov model with multiple abstraction levels is able to infer the user’s destination or their mode of transportation. [27] discovers traffic congestion on the road network examining co-occurring congestion locations.
Distributed systems have been widely used for traffic monitoring in smart cities environments [4, 19]. In [4], the authors exploit IBM-Streams, [17] a scalable stream processing platform, to perform traffic monitoring in the city of Stockholm. Their system is able to continuously derive current traffic statistics from vehicle reports and also can provide useful information such shortest-time routes from real-time and estimated traffic conditions. While in [19] the authors combine Apache’s Hadoop [1] and Apache’s Spark [2] to detect traffic congestion in the Greater Toronto Area. Due to the varying volume of data that needs to be processed in such traffic monitoring applications (e.g. during peak hours more input data will be received), it is common practice to exploit elasticity techniques [15, 25], for automatically adjusting the amount of processing nodes used for the data processing.
Crowdsourcing in smart cities is the process of soliciting contributions from citizens that actively participate by contributing real-time information from their mobile devices about city events. Crowdsourcing has been widely used recently both from applications driven by city authorities, such as the JRA Find and Fix app [14] where users report road defects for the Johannesburg’s road network and from applications driven from organizations such as in Waze, [36] where users are asked to report traffic events from their current location. Crowdsourcing in smart cities introduces a number of challenges like unpredictable user response delays [5], human characteristics that are difficult to be estimated such as reliability [7], expertise [24] and availability [30], as well as dealing with privacy issues [6].
3 Methods and Techniques
To meet the requirements of Smart Cities applications we aid users to identify events in (near) real-time or flag emergencies and anomaly events so that authorities can quickly allocate assets to address these problems. For example, in a real setting we may have data coming from different streaming sources including static or mobile sensors, social media, citizen reports, etc. Each of these sources requires a comprehensive set of techniques to analyze them. We identify generic problems that come up in these settings. In this section we describe how each problem is addressed in a real context in the city of Dublin. The streams that are used are presented in Table 1.
3.1 Flexible and Dynamic Pipeline for Complex Event Processing
One challenge was to process and analyze massive data streams and detect events in near-real time, using scalable techniques. To deal with the above issue we used a data pipeline that consists of distributed stream and batch processing components. This pipeline is able to perform Complex Event Processing (CEP) in the streaming data. Finally we instantiated the pipeline using the Dublin data.
3.1.1 Distributed Stream and Batch Processing Pipeline
In order to identify complex events in a scalable way, we adapted the architecture that is illustrated in Fig. 2 and presented in [41]. This module, exploits the Lambda architecture [20] combining a well-known stream processing framework, Apache Storm, with a highly expressive CEP system, Esper [12]. Our approach is modular as different stream processing frameworks could be used instead of Storm, for example Spark [38]. We decided to use Apache Storm as it supports very low per tuple latency by processing each tuple separately and not in the form of mini-batches as Spark [38]. This feature is extremely useful in our case as we want to identify events as soon as possible. Initially Storm preprocesses the raw incoming tuples and extracts meaningful information. Then the tuples are forwarded to multiple concurrently running Esper engines. Each engine runs at different cluster nodes to exploit the cluster’s parallelism. These engines are responsible to invoke several rules on the incoming data and trigger events when they are satisfied. Additionally a batch processing framework is used, Apache’s Hadoop, to compute several statistics regarding the rules. These map-reduce jobs run periodically and their output is used in order to update the rules’ thresholds or models.

Distributed complex event processing [41]

Predict future input rate and tuples’ latency [37]
We selected to enable the dynamic adjustment of the number of running Esper engines (elasticity) to exploit fully the parallelism offered by Storm during peak hours and avoid wasting resources when the input load is reduced. To achieve this we used the technique presented in [37], where the expected input load for the upcoming time windows is estimated using Gaussian Processes (Fig. 3) and exploit it to automatically adjust the number of CEP engines in order to avoid information loss and without over-utilizing the system’s resources. In Fig. 4, we illustrate the benefits of the Elastic CEP approach, compared to another commonly applied technique (QT-Algorithm [25]) which models the problem using queueing theory and assumes that the input rate follows Poisson distribution. The experiments run in our local 8-VMs cluster. As you can see in Fig. 4 our proposed technique, Elastic CEP, is able to minimize a cost function that considers both the information loss and the amount of resources (i.e. engines) that we bind. Finally, the scalability of our approach is presented in Fig. 5, where the amount of tuples that failed to be processed within a specified time window is illustrated over time. Our approach is able to process a similar number of data as the static configuration, that uses the maximum number of resources (8 machines). Our approach varies the number of engines used over time, selecting the following sequence of concurrently running engines [1, 3, 7, 4, 5, 6, 7] and outperforms the performance of the comparing technique that misses a much larger number of tuples.
3.1.2 Instantiation of the Pipeline Using the Dublin Data
The previously described pipeline has been applied to the processing of bus and SCATS data streams. The elastic and scalable features of our approach fit appropriately to the DCC data streams due to their periodicity (e.g. more buses operate during the peak hours of the day and much less during the night hours). Using the pipeline to the real data had two main problems that we needed to overcome in order to identify meaningful events. The main issues were: (1) the noisy measurements for both bus and SCATS sensors that need specialized solutions and (2) the end user requirements that needed to be discussed with DCC traffic operators in order to set up the CEP rules appropriately.

Comparison of the cost overtime using different elasticity techniques [37]

Comparison of the missed tuples overtime for the different techniques [37]
-
(1)
Noisy measurements: The first problem that we had to deal with was to clean the data and extract meaningful information from them. In our initial analysis we identified that the reported raw data were noisy. More specifically, in some occasions buses reported as closest bus stop a stop that was many miles away from the actual closest bus stop. Also, some buses due to faulty sensors reported that they were stopped at a particular bus stop while they were actually moving. We clean the data solving the issues described above using the list of bus stops for each route, checking the spatial distance between the bus and the stops of the route. Also for the moving buses we set the at stop field to be False. In order to extract information from the raw data we calculated the time needed for a bus to go from one bus stop to the next. Finally, we calculated the approximate speed of each bus, using its previously reported coordinates. For the SCATS Data we identified that several sensors were faulty reporting extreme or unreasonably high measurements. To solve the above issue we used the technique presented in [40] that checks using a multivariate ARIMA model, whether the sensor’s reports deviate significantly and unexpectedly from the measurements reported by neighbouring sensors.
-
(2)
End user requirements: After discussing the problem with DCC traffic operators we set up several rules that when they are triggered a potential traffic anomaly may occur in the city. The rules that we used for the Bus Data are described bellow:
-
Report a traffic anomaly when the time needed to travel from one stop to the next exceeds the expected time by some orders of magnitude.
-
Report a noisy sensor when the bus moves while it is at stop.
-
Report a noisy sensor when the bus seems to move with extreme speed.
The rules that we used for the SCATS Data are simple, but as described later in Sect. 4 are able to identify accurately traffic congestion. More specifically, we defined the following rules:
-
Raise a traffic alarm when the moving average of the streaming values of the degree of saturation exceeds a predefined threshold.
-
Report a faulty sensor if one is identified to variate significantly from its neighbors.
3.2 Building a Pipeline for Twitter Monitoring
Twitter was successfully used to detect meaningful events exploiting users as human sensors. Examples include the detection of earthquakes [31], floods [32], or even crimes [21]. We build a monitoring pipeline that utilizes Twitter to detect events of interest.

The Twitter analysis component architecture.
Usually when researchers perform topic-specific event detection on Twitter stream they query tweets containing particular keywords, generated by a specific user or located at a particular area, respecting at the same time the Twitter API constraints [35]. A great challenge that arises is how to use the Twitter’s query filters efficiently in order to acquire more topic related tweets. Thus, we develop a Twitter Fetcher that is responsible to gather tweets relevant to a given topic by tracking a dynamic set of keywords, users and locations and then forward them to the pipeline. The set of keywords and users is dynamically updated aiming to maximize the topic coverage. Another challenge is the fact that many messages do not contain location information. That said, a Geotagger able to assign exact GPS coordinates exploiting a tweet’s text is the next pipeline component. Following the approach described in [8] and using the OpenStreetMap API [28] and Lucene, [23] the Geotagger assigns GPS coordinates according to road and POI references in tweets. The resulting set of geotagged tweets should be filtered and only the relevant tweets should be kept. In order to accomplish that a Text Classifier is used as the last unit of our pipeline. We used SVM to classify the incoming tweets, using as features the tweet’s TF-IDF weighted vector, and the existence or absence of roads or POIs references. We tuned the classifier using an annotated dataset and under 10-fold cross validation we achieved an F-Measure of \(88.3\,\%\), a Precision of \(93\,\%\) and a Recall of \(84.2\,\%\). The output of this pipeline is stored to a MongoDB instance for further usage and post-processing (Fig. 6).
The above framework is modular enough to be applied in any city given that citizens are active Twitter users. It was instantiated for the Dublin city. The Twitter Fetcher was set to return a Twitter stream from the Dublin city relevant to the topics of traffic and flood. The Geotagger was loaded with information about the Dublin road network from Open Street Maps. Finally, the Text Classifier was able to identify Traffic and Flood related messages. The training of the classifier was done using traffic and flood tweets originating from Dublin services such as ‘AARoadwatch’ and ‘Livedrive’.
Dublin citizens proved to be very active Twitter users reporting on daily basis many events observed in the city. This fact was reflected in the evaluation where the Twitter monitoring pipeline was found very useful. A useful suggestion by the traffic operators during the feedback loops was to use a set of blacklisted words in order to avoid receiving tweets from towns nearby Dublin. Some example tweets detected from the Twitter monitoring pipeline are presented in Table 2.
3.3 Crowdsourcing Component
Crowdsourcing is a key part of our system as it allows us to extract information from the ubiquitous citizens, complementing the information extracted from the rest of the sensors and solving disagreements. Our experience from employing crowdsourcing in Smart City environments has shown that there are several challenges that need to be addressed to use crowdsourcing effectively: (i) users have different characteristics when processing crowdsourcing tasks in terms of response delays, user reliability and biases in their responses, (ii) user privacy is an important aspect that needs to be considered so that users will not be averted to send feedback, and (iii) scalability issues need to be taken into account when deploying crowdsourcing in such large scale environments. Our implementation addresses these challenges as explained in the remainder of the section.
3.3.1 How Crowdsourcing Is Invoked
The crowdsourcing is invoked whenever the different modules report contradictory types of anomalies. In order to identify such disagreements we developed an engine responsible to identify joint spatiotemporal anomalies. This component combines information from different components by grouping close (in space and time) reported anomalies together. When there is a disagreement in the type of anomalies reported from different modules, and hence uncertainty, it issues a query to the Crowdsourcing component to obtain direct information about this anomaly. It receives anomalies that contain the spatial area, where an event occurred, the timestamp of the event and the type of the event. In addition, in order to identify events it uses a R-tree and a queue data structure to store both the received anomalies and the candidate events.
The R-Tree data structure is used in order to efficiently detect spatial intersections. If a spatial intersection between two reported anomalies is found an event candidate is created and stored to the R-Tree. If a new anomaly intersects with an existing event candidate, the latter is updated. The event candidate affected area is set to the spatial intersection with the new anomaly. An event candidate may update to an event when a set of empirical rules is satisfied. For example, if multiple sensors (e.g. Twitter and SCATS) contribute to an event candidate then this candidate will evolve to an event.
In order to have guarantees that memory and time requirements will not grow unbounded over time the received anomalies and the candidate events are stored in a FIFO queue. These data are removed from both the queue and the R-Tree when they temporally differ from the latest data received more than a time threshold. The dataflow of the described engine is depicted on Fig. 7.

The data structures used by the crowdsoucing invoker engine

Task assignment in crowdsourcing
3.3.2 Making Crowdsourcing Efficient in a City-Wide Environment
Our crowdsourcing component comprises two main entities: (i) The Crowdsourcing server, that is responsible to act as a middleware between the streaming spatiotemporal event identification engine and the human users, by extracting information from the citizens and propagating this information to the event identification engine, and (ii) The CrowdAlert app, that was implemented aiming to allow users interact with our system and provide real-time information and observe ongoing events.
The Crowdsourcing server exploits the Misco framework [10], which is based on the MapReduce paradigm and tailored for mobile devices (Fig. 10) to assign crowdsourcing tasks to the citizens dynamically and aggregate the extracted information in a scalable manner. Assigning task to the human crowd is performed using techniques developed from our group [5, 7] that consider the individual characteristics of the users. We have investigated the benefit of using different task assignment approaches by presenting the amount of tasks that have been accomplished correctly and within a predefined time interval, as shown in Fig. 8. Our approaches REACT [5], that considers the real-time constraints of the individual users, and CRITICAl [7], that considers both reliability and real-time constraints for groups of users, improve significantly the number of tasks processed successfully compared to traditional approaches that assign tasks randomly. Moreover CRITICAl performs better than REACT although there is a trade-off with the execution time needed to execute the algorithm, since REACT is faster. Hence, we use different task assignment strategies depending on the requirements (e.g., critical tasks require fast responses even if the responses are unreliable). After we retrieve responses, we try to eliminate user bias to further improve the accuracy of our results. Finally, we note, that, the Crowdsourcing server is also responsible to receive user reports regarding ongoing events and propagate them to the spatiotemporal event identification engine as well as to inform the citizens for traffic and unusual events in their area.

CrowdAlert App
The CrowdAlert app allows both citizens and DCC operators to observe the ongoing events, identified from the system, in real-time, as shown in Fig. 9a and to provide valuable feedback. Thus, the users can participate at the central part of CrowdAlert which is to report events that take place near their location, including Accidents, Hazards, Constructions, etc., as shown in Fig. 9b. Additionally the users can also classify the traffic events that appear on the map to provide more accurate information regarding the events. All these reports are forwarded to the spatiotemporal event identification engine through the Crowdsourcing server to be processed along with data arriving from different components. We also note that the users of the CrowdAlert app report periodically their approximate location. Such information is used by the system to be able to ask user feedback dynamically when the users are near an ongoing event. An example of such a query is shown in Fig. 9c where the users need to respond in the question: “Can you observe an incident/traffic in the reported location?”. The approximate location is provided by the Android API that exploits the cell network and WiFi. We chose to use the approximate location instead of the accurate GPS location for energy efficiency and privacy reasons. In addition, we integrated our privacy preserving approach [6] to prevent privacy exposure of the user mobility when participating in CrowdAlert. Finally, the users can tune the CrowdAlert settings (Fig. 9d), such as the amount of Crowdsourcing tasks that they wish to receive per day, or the maximum distance from their current location for which they wish to answer to tasks.
4 User Evaluation and Lessons Learned
The Dublin City Council personnel evaluated our system in terms of effectiveness and usability. The evaluation of the previously described techniques was performed in the context of INSIGHT system presented in Fig. 10 and was performed using the INSIGHT Web Interface that allows the quick visualization and exploration of the real-time analysis output, as shown in Fig. 11. This interface offers a layered visualization of the identified events in order to help the operator to filter out the unnecessary information.

Overview of system’s layers: (i) the first layer receives the streaming data (ii) the second layer preprocess the raw data and detects anomalies, using scalable techniques (iii) the third layer groups the anomalies to identify events of interest or to send tasks to crowdsourcing users to resolve uncertainty

(a) The Web interface with different icons representing the locations of buses, locations with congestion and events from Twitter. The user can select which icons to display using the layers menu. (b) Details about a detected event.
4.1 Evaluation Protocol
Relevant DCC personnel were invited to participate in the evaluation of the system. Using the Traffic Management Centre (TMC) and the adjoining Local Incident Room as a central hub allowed staff to evaluate the system all together, seeking clarification by asking questions and attending to concerns that may have arisen.
The evaluation was operated in two hour time windows and in two different days. The time windows were: (a) Day 1; 08.00–10.00, 16.00–18.00 and (b) Day2; 09.00–11.00, 15.00–17.00. These are typically periods of high volume of traffic in Dublin. In those time windows people involved in the evaluation were invited to utilize the system and complete a number of tasks. In each time window, participants were organized in groups based on their role in the department and completed only a part of the evaluation. For example people from the Traffic Management Centre Team worked on congestion related events. Participants from the Bus Priority Team evaluated the events identified from the Bus analysis component and Live-Bus layer of the system while the radio station team monitored social media. The following personnel were invited to participate in the evaluation of the system in the TMC: Traffic Management Personnel (12 people), LiveDrive Radio Station (5 people), Traffic ITS Officers (10 people). The personell confirmed or rejected the reported events based on manual CCTV cameras investigation. The cameras are able to capture a large portion of the city.
4.2 Results
The evaluation team compiled an overall report for the whole system and more detailed reports for each component itself.
Bus Analysis Component. The bus priority team mentioned that the Bus anomaly detection mechanism proved useful in giving users information related to bus congestion events. They state that it proved more difficult to confirm these events using CCTV as by the time they tried to confirm the congestion event, the time may have lapsed in some cases, so verifying these anomalies was more difficult that the other events. They noted that the information given with each bus event was very useful in trying to isolate the location of the event. In particular they liked the ‘view the bus stops’ link, as this allows the user to know the direction of the bus and the current and next stop due.
SCATS Analysis Component. The SCATS anomaly detection proved very useful in allowing users to detect singular anomalies related to a junction. The anomaly detection triggers alerts about lanes with high degree of saturation, something that would not be possible using the existing SCATS system. Being able to use the map along with SCATS and CCTV proved useful to diagnose and confirm anomalies.
Twitter Analysis Component. According to the Livedrive radio station [11] team, Twitter event detection has been an excellent feature to the INSIGHT system. One issue they mentioned was the fact that tweets that refer to nearby regions of Dublin were mistakenly geolocated at Dublin. They suggested that with some additional negative keyword lists, such as counties outside of the Greater Dublin Area (e.g. Cork, Limerick, Galway), the location relevancy of the alerts will be more accurate. However, part of the issue is the fact that nearby countries share road names with Dublin confusing the system’s geotagger.
The DCC team examined independently a complete list of Tweets that the Twitter analysis component identified as event tweets (Traffic related or Flood related) during the two day evaluation period. According to their manual annotation they found that:
-
179 Tweets identified as Relevant from the system
-
91 % (163 tweets) were confirmed as true positives
-
63 % (113 tweets) were confirmed as true positives in the city of Dublin. The rest relevant tweets were from nearby towns mistakenly identified at Dublin.
Crowdalert. The users found the crowdsourcing application very easy to use. According to them, the buttons make it very easy to report an event and view it immediately on the map display. With relation to users replying to alerts, it was felt that more clarity was needed over exact location of events or more clarity on the questions being asked of users. Due to the way the INSIGHT system is designed, it aggregates several events in adjacent geographic locations to issue crowdsourcing tasks and as a result CrowdAlert receives the approximate location of the area where the events take place rather than their exact location.
4.3 Lessons Learned
Component specific lessons learned could be summarized in the following points:
-
(i)
The scalable and elastic framework enhanced with CEP engines helped to easily create or update the event detection rules. Finding the appropriate parameters for these rules is not an easy process, however, if the right rules are available, the processing can be simple and efficient.
-
(ii)
Social media such as Twitter provide a valuable source of real time information about incidents in a city.
-
(iii)
During the development of CrowdAlert we interacted with alpha and beta testers from DCC to improve it. Our conclusion is that such applications should provide a simple and easy to use interface, so that the user can interact immediately (e.g., Yes/No answers), rather than providing too many options to the users. That way we modified the app so that the citizens will be willing to provide feedback and use the app.
5 Conclusions
In this work we describe three techniques able to cope with the challenges that arise in urban data analysis: the dynamic nature, the requirement for handling complex high velocity data streams, and information uncertainty. The proposed solutions address these challenges providing accurate, scalable real-time event detection. User oriented evaluation provided with evidence not only of the efficiency of the provided tools but also of their usability and positive impact in the user’s work-flow.
References
Apache-Hadoop: http://hadoop.apache.org
Apache-Spark: https://spark.apache.org
Attwood, A., Merabti, M., Fergus, P., Abuelmaatti, O.: Sccir: smart cities critical infrastructure response framework. In: Developments in E-systems Engineering (DeSE) 2011, pp. 460–464. IEEE (2011)
Biem, A., Bouillet, E., Feng, H., Ranganathan, A., Riabov, A., Verscheure, O., Koutsopoulos, H., Moran, C.: Ibm infosphere streams for scalable, real-time, intelligent transportation services. In: Proceedings of the 2010 ACM SIGMOD International Conference on Management of data, pp. 1093–1104. ACM (2010)
Boutsis, I., Kalogeraki, V.: Crowdsourcing under real-time constraints. In: IPDPS, Boston, MA, pp. 753–764, May 2013
Boutsis, I., Kalogeraki, V.: Privacy preservation for paricipatory sensing data. In: PerCom, San Diego, CA, USA, March 2013
Boutsis, I., Kalogeraki, V.: On task assignment for real-time reliable crowdsourcing. In: ICDCS, Madrid, Spain, pp. 1–10, June 2014
Daly, E.M., Lecue, F., Bicer, V.: Westland row why so slow? fusing social media and linked data sources for understanding real-time traffic conditions. In: ACM IUI (2013)
Doraiswamy, H., Ferreira, N., Damoulas, T., Freire, J., Silva, C.T.: Using topological analysis to support event-guided exploration in urban data. IEEE Trans. Vis. Comput. Graph. 20(12), 2634–2643 (2014)
Dou, A.J., Kalogeraki, V., Gunopulos, D., Mielikainen, T., Tuulos, V.: Scheduling for real-time mobile mapreduce systems. In: DEBS (2011)
DublinCity-FM: http://www.dublincityfm.ie/live-drive
Esper-Tech: http://www.espertech.com
Filipponi, L., Vitaletti, A., Landi, G., Memeo, V., Laura, G., Pucci, P.: Smart city: an event driven architecture for monitoring public spaces with heterogeneous sensors. In: 2010 Fourth International Conference on Sensor Technologies and Applications (SENSORCOMM), pp. 281–286. IEEE (2010)
Find&Fix-App: http://www.jra.org.za/index.php/find-and-fix-mobile-app
Gedik, B., Schneider, S., Hirzel, M., Wu, K.L.: Elastic scaling for data stream processing. IEEE Trans. Parallel Distrib. Syst. 25(6), 1447–1463 (2014)
Hernández-Muñoz, J.M., Vercher, J.B., Muñoz, L., Galache, J.A., Presser, M., Hernández Gómez, L.A., Pettersson, J.: Smart cities at the forefront of the future internet. In: Domingue, J., Galis, A., Gavras, A., Zahariadis, T., Lambert, D., Cleary, F., Daras, P., Krco, S., Müller, H., Li, M.-S., Schaffers, H., Lotz, V., Alvarez, F., Stiller, B., Karnouskos, S., Avessta, S., Nilsson, M. (eds.) FIA 2011. LNCS, vol. 6656, pp. 447–462. Springer, Heidelberg (2011). doi:10.1007/978-3-642-20898-0_32
IBM-Streams: www-03.ibm.com/software/products/en/ibm-streams
INSIGHT-Project: http://insight-ict.eu/
Khazaei, H., Zareian, S., Veleda, R., Litoiu, M.: Sipresk: a big data analytic platform for smart transportation. In: EAI International Conference on Big Data and Analytics for Smart Cities (2015)
Lambda-Architecture: http://lambda-architecture.net/
Li, R., Lei, K.H., Khadiwala, R., Chang, K.C.C.: Tedas: a twitter-based event detection and analysis system. In: 2012 IEEE 28th International Conference on Data Engineering (ICDE), pp. 1273–1276. IEEE (2012)
Liao, L., Patterson, D.J., Fox, D., Kautz, H.: Learning and inferring transportation routines. Artif. Intell. 171(5), 311–331 (2007)
Lucene: http://lucene.apache.org/
Ma, F., Li, Y., Li, Q., Qiu, M., Gao, J., Zhi, S., Su, L., Zhao, B., Ji, H., Han, J.: Faitcrowd: fine grained truth discovery for crowdsourced data aggregation. In: KDD, Sydney, Australia, pp. 745–754, August 2015
Mayer, R., Koldehofe, B., Rothermel, K.: Meeting predictable buffer limits in the parallel execution of event processing operators. In: Big Data, pp. 402–411 (2014)
Münz, G., Li, S., Carle, G.: Traffic anomaly detection using k-means clustering. In: GI/ITG Workshop MMBnet (2007)
Nguyen, H., Liu, W., Chen, F.: Discovering congestion propagation patterns in spatio-temporal traffic data
OpenStreetMap: https://www.openstreetmap.org
Pang, L.X., Chawla, S., Liu, W., Zheng, Y.: On detection of emerging anomalous traffic patterns using gps data. Data Knowl. Eng. 87, 357–373 (2013)
Roy, S.B., Lykourentzou, I., Thirumuruganathan, S., Amer-Yahia, S., Das, G.: Task assignment optimization in knowledge-intensive crowdsourcing. VLDB J. 24, 467–491 (2015)
Sakaki, T., Okazaki, M., Matsuo, Y.: Earthquake shakes twitter users: real-time event detection by social sensors. In: Proceedings of the 19th International Conference on World Wide Web, pp. 851–860. ACM (2010)
Saravanou, A., Valkanas, G., Gunopulos, D., Andrienko, G.: Twitter floods when it rains: a case study of the uk floods in early 2014. In: Proceedings of the 24th International Conference on World Wide Web Companion, pp. 1233–1238. International World Wide Web Conferences Steering Committee (2015)
da Silva, W.M., Alvaro, A., Tomas, G.H., Afonso, R.A., Dias, K.L., Garcia, V.C.: Smart cities software architectures: a survey. In: Proceedings of the 28th Annual ACM Symposium on Applied Computing, pp. 1722–1727. ACM (2013)
Stenneth, L., Wolfson, O., Yu, P.S., Xu, B.: Transportation mode detection using mobile phones and gis information. In: Proceedings of the 19th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, pp. 54–63. ACM (2011)
Twitter-API: https://dev.twitter.com/rest/public/rate-limiting
Waze: https://www.waze.com/
Zacheilas, N., Kalogeraki, V., Zygouras, N., Panagiotou, N., Gunopulos, D.: Elastic complex event processing exploiting prediction. In: Big Data, Santa Clara, CA, USA. IEEE, October 2015
Zaharia, M., Das, T., Li, H., Hunter, T., Shenker, S., Stoica, I.: Discretized streams: fault-tolerant streaming computation at scale. In: Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, pp. 423–438. ACM (2013)
Zygiaris, S.: Smart city reference model: assisting planners to conceptualize the building of smart city innovation ecosystems. J. Knowl. Econ. 4(2), 217–231 (2013)
Zygouras, N., Panagiotou, N., Zacheilas, N., Boutsis, I., Kalogeraki, V., Katakis, I., Gunopulos, D.: Towards detection of faulty traffic sensors in real-time. In: MUD2, pp. 53–62 (2015)
Zygouras, N., Zacheilas, N., Kalogeraki, V., Kinane, D., Gunopulos, D.: Insights on a scalable and dynamic traffic management system. In: EDBT, Brussels, Belgium, pp. 653–664, March 2015
Acknowledgments
This research has been financed by the European Union through the FP7 ERC IDEAS 308019 NGHCS project, the Horizon2020 688380 VaVeL project and a Yahoo Faculty award.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing AG
About this paper
Cite this paper
Panagiotou, N. et al. (2016). Intelligent Urban Data Monitoring for Smart Cities. In: Berendt, B., et al. Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2016. Lecture Notes in Computer Science(), vol 9853. Springer, Cham. https://doi.org/10.1007/978-3-319-46131-1_23
Download citation
DOI: https://doi.org/10.1007/978-3-319-46131-1_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-46130-4
Online ISBN: 978-3-319-46131-1
eBook Packages: Computer ScienceComputer Science (R0)