
Abstract
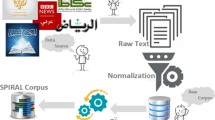
This paper presents a new correction model for Arabic OCR errors. The proposed model is mainly based on the character segmentation and the character alignment on a single character or multi-characters. Results show that the multi-character model is better than the single character model in that it is trained on 502,167 words and can find the correct word within the top 10 proposed corrections for 94 % of the words. This model considers the effect of increasing the size of training set that perfectly leads to better results; the correction rate will approach 53 % upon using 6000 words, 80 % upon using 64,225 words, and 94 % upon using 502,167 words.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
Available at: https://sourceforge.net/projects/arabic-wordlist/.
References
Nazif, A.: A System for the Recognition of the Printed Arabic Characters. M.Sc. Thesis. Cairo University, Faculty of Engineering, Egypt (1975)
Habash, N., Roth, R.M.: Using deep morphology to improve automatic error detection in arabic handwriting recognition. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Human Language Technologies, vol. 1, pp. 875–884 (2011)
Mahdi, A.: Spell Checking and Correction for Arabic Text Recognition. M.Sc. Thesis. King Fahd University of Petroleum And Minerals, Saudi Arabia (2012)
Kukich, K.: Techniques for automatically correcting words in text. ACM Comput. Surv. 24, 377–439 (1992)
Muhammad, M., ElGhazaly, T.: Handling OCR-degraded arabic text: a comprehensive survey. In: Proceedings of the 48th annual ISSR conference, Institute of Statistical Studies and Research, Cairo University, Egypt (2013)
Magdy, W., Darwish, K.: Omni font OCR error correction with effect on retrieval. In: Intelligent Systems Design and Applications (ISDA), pp. 415–420 (2010)
Magdy, W., Darwish, K.: Arabic OCR error correction using character segment correction, language modeling, and shallow morphology. In: Proceedings of 2006 Conference on Empirical Methods in Natural Language Processing (EMNLP 2006), Sydney, Australia, pp. 408–414 (2006)
Kanungo, T., Marton, G.A., Bulbul, O.: OmniPage vs. Sakhr: paired model evaluation of two arabic OCR products. In: Proceedings of SPIE Conference on Document Recognition and Retrieval (1999)
Ezzat, M., ElGhazaly, T., Gheith, M.: An enhanced arabic OCR degraded text retrieval model. In: Castro, F., Gelbukh, A., González, M. (eds.) MICAI 2013. LNCS (LNAI), vol. 8265, pp. 380–393. Springer, Heidelberg (2013). doi:10.1007/978-3-642-45114-0_31
Church, K., Gale, W.: Probability scoring for spelling correction. Stat. Comput. 1, 93–103 (1991)
Brill, E., Moore, R.: An improved error model for noisy channel spelling correction. In: Proceedings of the 38th Annual Meeting of Association for Computational Linguistics, pp. 286–293 (2000)
Attia, M., Pavel, P., Younes, S., Shaalan, K., Josef, v., G.: Improved spelling error detection and correction for arabic. In: COLING 2012, Mumbai, India (2012)
Olshausen, B.A.: Bayesian Probability Theory. The Redwood Center for Theoretical Neuroscience, Helen Wills Neuroscience Institute at the University of California at Berkeley, Berkeley, CA (2004)
Elghazaly, T.: Improving OCR-degraded arabic text retrieval through an enhanced orthographic query expansion model. In: Tan, Y., Shi, Y., Buarque, F., Gelbukh, A., Das, S., Engelbrecht, A. (eds.) ICSI 2015. LNCS, vol. 9141, pp. 117–124. Springer, Heidelberg (2015). doi:10.1007/978-3-319-20472-7_13
Levenshtein, V.: Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 10, 707 (1966)
Mohit, B., Rozovskaya, A., Habash, N., Zaghouani, W., Obeid, O.: The first QALB shared task on automatic text correction for arabic. In: Proceedings of EMNLP 2014 Workshop on Arabic Natural Language (2014)
Muaidi, H., Al-Tarawneh, R.: Towards arabic spell-checker based on N-grams scores. Int. J. Comput. Appl. 53(3), 12–16 (2012)
Ng, H.T., Wu, S.M., Wu, Y.,: Hadiwinoto, C., Tetreault, J.: The CoNLL-2013 shared task on grammatical error correction. In: Proceedings of CoNLL-2013 Shared Task (2013)
Rozovskaya, A., Habash, N., Eskander, R., Farra, N., Salloum, W.: The columbia system in the QALB-2014 shared task on arabic error correction. In: Proceedings of EMNLP 2014 Workshop on Arabic Natural Language (2014)
Zobel, J., Box, G., Dart, P.: Phonetic string matching: lessons from information retrieval. In: Proceedings of SIGIR-96, the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (1996)
Riseman, E., Hanson, A.: A contextual post processing system for error correction using binary n-grams. IEEE Trans. Comput. 23(5), 480–493 (1974)
Islam, A., Inkpen, D.: Real-word spelling correction using google web IT 3-grams. In: Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, 3(August), pp. 1241–1249 (2009)
Kemighan, M., Church, K., Gale, W.: A spelling correction program based on a noisy channel model. In: Proceedings of the 13th conference on Computational linguistics, vol. 2, pp. 205–210 (1990)
Yannakoudakis, E., Fawthro, D.: The rules of spelling errors. Inf. Process. Manage. 19(2), 87–99 (1983)
Shaalan, K., Allam, A., Gohah, A.: Towards automatic spell checking for arabic. In: Proceedings of the Conference on Language Engineering (ELSE), pp. 240–247 (2003)
Alkanhal, M.I., Al-Badrashiny, M.A., Alghamdi, M.M., Al-Qabbany, A.O.: Automatic stochastic arabic spelling correction with emphasis on space insertions and deletions. In: Proceeding of IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 7 (2012)
Haddad, B., Mustafa, Y.: Detection and correction of non-words in arabic: a hybrid approach. Int. J. Comput. Process. Orient. Lang. 20(4), 237–257 (2007)
Hassan, Y., Aly, M., Atiya, A.: Arabic spelling correction using supervised learning. In: Proceedings of EMNLP 2014 Workshop on Arabic Natural Language (2014)
Kanungo, T., Marton, G.A., Bulbul, O.: OmniPage vs. Sakhr: paired model evaluation of two arabic OCR products. In: International Society for Optics and Photonics, pp. 109–120 (1999)
Acknowledgements
The authors are grateful to the referees for their careful reading, insightful comments and helpful suggestions which have led to improvement in the paper.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Muhammad, M., ELGhazaly, T., Ezzat, M., Gheith, M. (2017). A Spell Correction Model for OCR Errors for Arabic Text. In: Hassanien, A., Shaalan, K., Gaber, T., Azar, A., Tolba, M. (eds) Proceedings of the International Conference on Advanced Intelligent Systems and Informatics 2016. AISI 2016. Advances in Intelligent Systems and Computing, vol 533. Springer, Cham. https://doi.org/10.1007/978-3-319-48308-5_13
Download citation
DOI: https://doi.org/10.1007/978-3-319-48308-5_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-48307-8
Online ISBN: 978-3-319-48308-5
eBook Packages: EngineeringEngineering (R0)