
Abstract
With the popularity of the Internet and crowdsourcing, it becomes easier to obtain labeled data for specific problems. Therefore, learning from data labeled by multiple annotators has become a common scenario these days. Since annotators have different expertise, labels acquired from them might not be perfectly accurate. This paper derives an optimization framework to solve this task through estimating the expertise of each annotator and the labeling difficulty for each instance. In addition, we introduce similarity metric to enable the propagation of annotations between instances.
H.-E. Sung and C.-K. Chen—denotes equal contribution.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

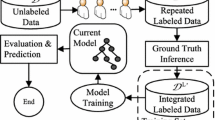
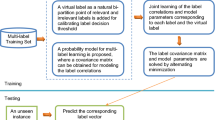
Notes
References
Yan, Y., Rosales, R., Fung, G., Schmidt, M.W., Valadez, G.H., Bogoni, L., Moy, L., Dy, J.G.: Modeling annotator expertise: learning when everybody knows a bit of something. In: AISTATS, pp. 932–939 (2010)
Raykar, V.C., Yu, S., Zhao, L.H., Jerebko, A., Florin, C., Valadez, G.H., Bogoni, L., Moy, L.: Supervised learning from multiple experts: whom to trust when everyone lies a bit. In: Proceedings of the 26th Annual International Conference on Machine Learning, pp. 889–896. ACM (2009)
Zhang, P., Obradovic, Z.: Learning from inconsistent and unreliable annotators by a Gaussian mixture model and Bayesian information criterion. In: Gunopulos, D., Hofmann, T., Malerba, D., Vazirgiannis, M. (eds.) ECML PKDD 2011. LNCS (LNAI), vol. 6913, pp. 553–568. Springer, Heidelberg (2011). doi:10.1007/978-3-642-23808-6_36
Raykar, V.C., Yu, S., Zhao, L.H., Valadez, G.H., Florin, C., Bogoni, L., Moy, L.: Learning from crowds. J. Mach. Learn. Res. 11(Apr), 1297–1322 (2010)
Raykar, V.C., Yu, S.: Eliminating spammers and ranking annotators for crowdsourced labeling tasks. J. Mach. Learn. Res. 13(Feb), 491–518 (2012)
Zhang, P., Obradovic, Z.: Integration of multiple annotators by aggregating experts and filtering novices. In: 2012 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pp. 1–6. IEEE (2012)
Zhang, P., Cao, W., Obradovic, Z.: Learning by aggregating experts and filtering novices: a solution to crowdsourcing problems in bioinformatics. BMC Bioinform. 14(Suppl 12), S5 (2013)
Yan, Y., Fung, G.M., Rosales, R., Dy, J.G.: Active learning from crowds. In: Proceedings of the 28th International Conference on Machine Learning (ICML 2011), pp. 1161–1168 (2011)
Yan, Y., Rosales, R., Fung, G., Dy, J.: Modeling multiple annotator expertise in the semi-supervised learning scenario. arXiv preprint arXiv:1203.3529 (2012)
Yan, Y., Rosales, R., Fung, G., Farooq, F., Rao, B., Dy, J.G., Malvern, P.: Active learning from multiple knowledge sources. In: AISTATS, vol. 2, p. 6 (2012)
Yan, Y., Rosales, R., Fung, G., Dy, J.: Active learning from uncertain crowd annotations. In: 2014 52nd Annual Allerton Conference on Communication, Control, and Computing (Allerton), pp. 385–392. IEEE (2014)
Yan, Y., Rosales, R., Fung, G., Subramanian, R., Dy, J.: Learning from multiple annotators with varying expertise. Mach. Learn. 95(3), 291–327 (2014)
Long, C., Hua, G.: Multi-class multi-annotator active learning with robust gaussian process for visual recognition. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2839–2847 (2015)
Rodrigues, F., Pereira, F., Ribeiro, B.: Learning from multiple annotators: distinguishing good from random labelers. Pattern Recogn. Lett. 34(12), 1428–1436 (2013)
Lichman, M.: UCI machine learning repository (2013)
Rzhetsky, A., Shatkay, H., Wilbur, W.J.: How to get the most out of your curation effort. PLoS Comput. Biol. 5(5), e1000391 (2009)
Acknowledgement
This material is based upon work supported by the Air Force Office of Scientific Research, Asian Office of Aerospace Research and Development (AOARD) under award number FA2386-15-1-4013, and Taiwan Ministry of Science and Technology (MOST) under grant number 105-2221-E-002-064-MY3.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Sung, HE., Chen, CK., Xiao, H., Lin, SD. (2017). A Classification Model for Diverse and Noisy Labelers. In: Kim, J., Shim, K., Cao, L., Lee, JG., Lin, X., Moon, YS. (eds) Advances in Knowledge Discovery and Data Mining. PAKDD 2017. Lecture Notes in Computer Science(), vol 10234. Springer, Cham. https://doi.org/10.1007/978-3-319-57454-7_5
Download citation
DOI: https://doi.org/10.1007/978-3-319-57454-7_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-57453-0
Online ISBN: 978-3-319-57454-7
eBook Packages: Computer ScienceComputer Science (R0)