
Abstract
Non-reference image quality measures are used to distinguish real biometric data from data as used in presentation/sensor spoofing attacks. An experimental study shows that based on a set of 6 such measures, classification of real vs. fake fingervein data is feasible with an accuracy of 99% on one of our datasets. However, we have found that the best quality measure (combination) and classification setting highly depends on the target dataset. Thus, we are unable to provide any other recommendation than to optimise the choice of quality measure and classification setting for each specific application setting. Results also imply, that generalisation to unseen attack types might be difficult due to dataset dependence of the results.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Discrete Cosine Transform
- Local Binary Pattern
- Discrete Cosine Transform Coefficient
- Image Quality Assessment
- Generalise Gaussian Distribution
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Biometric authentication techniques have emerged to replace or at least complement the traditional authentication methods (e.g. passwords). Consequently, various attacks have been increasingly observed threatening the reliability of this authentication approach. In particular, artifacts mimicking real biometrics traits or captured and displayed image or video footage of real biometric traits have been used to deceive biometric sensors and systems in so-called “presentation”- or “sensor-spoofing”- attacks. In general, counter-measures to such presentation attacks (or anti-spoofing [1]) in biometrics can be categorised into (1) liveness-based, (2) motion-based, and (3) texture-based methods. Liveness-based methods use signs of vitality to ensure that the image is captured from a living human being. In contrast, motion-based methods utilise unnatural movements on scenes as indication of spoofing, e.g. caused by hand motion when presenting a photo or a display to the sensor. Texture-based methods aim to explore textural artifacts in the images captured by the sensor (e.g. caused by recapturing artifacts). While liveness-based techniques are of course specific for the modality under investigation, texture-based methods often employ general purpose texture descriptors in a machine learning setting to discriminate real biometric data from spoofed variants. For example, [2] compares the attack detection performance of certain local descriptors on collections of spoofed iris, fingerprint, and face data. In order to circumvent the question which texture descriptors to choose, also generative deep learning techniques employing convolutional neural networks have been successfully used to identify spoofed data [3].
An entirely different approach is to consider the quality of the imagery in biometric anti-spoofing which can be interpreted as a specific form of texture-based technique. While this can be done in an approach entirely agnostic of the underlying modality by employing general purpose image quality measures (IQM) [4], a possible alternative is to consider specific properties of the target modality in the quality considerations (see e.g. [5] for quality assessment for face recognition spoofing detection). In this paper we revisit general purpose non-reference IQM (also termed “blind”) for their suited-ness in presentation attack detection. In particular, while applying a similar methodology as in [4], we (i) apply non-reference IQM for the first time in biometric fingervein spoofing detection, (ii) aim at a different and larger set of non-reference IQM (6 instead of 2) compared to [4], and (iii) do not fuse the results with full-reference IQM but focus on blind IQM as a stand-alone technique (eventually also employing a single metric contrasting to [4] where most results given correspond to fusing a considerable amount of IQM also resulting in significant computational effort).
Section 2 reviews the state-of-the-art in fingervein (FV) spoofing detection while the blind IQM as used in this paper are explained in Sect. 3. Experimental results, including a description of the dataset used in this study, are presented in Sect. 4. Section 5 provides the conclusions of this paper.
2 Fingervein Spoofing Detection
One biometric trait enjoying more and more popularity are veins. One advantage of veins over other biometric traits is the fact that they are embedded inside the human body, as opposed to traits like fingerprints or faces. Moreover, vein images can be acquired in an unintrusive manner which is not the case for other biometric traits, such as fingerprint acquisition. However, despite being resistant to tampering, vein-based authentication is vulnerable to presentation attacks [6].
Contrasting to all subsequent techniques (which are texture-based), a first FV presentation attack detection technique based on liveness detection has been proposed [7], requiring FV video data to apply motion magnification techniques to classify into real and fake data.
In 2015, the first competition on counter-measures to fingervein spoofing attacks took place [8] (providing a dataset of real and fake FV images). The competition baseline algorithm looks at the frequency domain of FV images, exploiting the bandwidth of vertical energy signal on real fingervein images, which is different for fakes ones. Three teams participated in this competition. The first team (GUC) uses binarised statistical images features (BSIF). They represent each pixel as a binary code. This code is obtained by computing the pixel’s response to a filter that are learnt using statistical properties of natural images [8]. The second team (B-Lab) uses monogenic scale space based global descriptors employing the Riesz transform. This is motivated by the fact that local object appearance & shape within an image can be represented as a distribution of local energy and local orientation information. The best approach (team GRIP-PRIAMUS) utilises local descriptors, i.e., local binary patterns (LBP), and local phase quantisation (LPQ) and Weber local descriptors (WLD). They distinguish between full and cropped images. LBPs and LPQ/WLD are used to classify full and cropped images, respectively.
However, counter-measures to finger vein spoofing attacks were/are already developed prior or independent to this competition. In 2013, the authors of [9] introduced a fake finger vein image detection based upon Fourier, and Haar and Daubechies wavelet transforms. For each of these features, the score of spoofing detection was computed. To decide whether a given finger vein image is fake or real, an SVM was used to combine the three features.
The authors of [10] propose windowed dynamic mode decomposition (W-DMD) to be used to identify spoofed finger vein images. DMD is a mathematical method to extract the relevant modes from empirical data generated by non-linear complex fluid flows. While DMD is classically used to analyse a set of image sequences, the W-DMD method extracts local variations as low rank representation inside a single still image. It is able to identify spoofed images by capturing light reflections, illuminations and planar effects.
Texture-based presentation attack detection techniques have been proven to be applicable to the imagery in the FV-Spoofing-Attack database [8] independent of the above-referenced competition, in particular baseline LBP [11]. In a recent paper [12], inspired by the success of basic LBP techniques [8, 13] in finger vein spoofing detection and the availability of a wide variety of LBP extensions and generalisations in literature, we have empirically evaluated different features obtained by using these more recent LBP-related feature extraction techniques for finger vein spoofing detection. Also the steerable pyramid is used to extract features subsequently used for FV spoofing detection [11]. Steerable pyramids are a set of filters in which a filter of arbitrary orientation is synthesised as a linear combination of a set of basis functions. This enables the steerable pyramids scheme to compute the filter response at different orientations. This scheme shows consistent high performance for the finger vein spoofing detection problem and outperforms many other texture-classification-based techniques. It is compared to techniques from [8], including two LBP variants, and to quality-based approaches computing block-wise entropy, sharpness, and standard deviation.
Finally, a detection framework based on singular value decomposition (SVD) is proposed in a rather confused paper [13]. The authors utilise the fact that one is able to extract geometrical finger edge information from infrared finger images. Fingevein images are classified based on image quality assessment (IQA) without giving any clear indication about the actual IQA used and any experimental results.
3 Non-reference Image Quality Metrics
Current state-of-the-art non-reference Image Quality Assessment (NR IQM) algorithms are based on models that can learn to predict human judgments from databases of human-rated distorted images. These kinds of IQM models are necessarily limited, since they can only assess quality degradations arising from the distortion types that they have been trained on. However, it is also possible to contemplate sub-categories of general-purpose NR IQM models having tighter conditions. A model is said to be opinion-aware (OA) if it has been trained on a database(s) of human rated distorted images and associated subjective opinion scores.
Algorithms like DIIVINE, BIQI, BLIINDS-2 and BRISQUE are OA IQM measures. However, IQM like NIQE, and BIQAA are opinion-unaware (OU) and they make only use of measurable deviations from statistical regularities observed in natural images without being trained on human-rated distorted images and indeed without any exposure to distorted images.
Systematic comparisons of the NR IQM as used in this paper have been published [14, 15]. Both, in non-trained [14] as well as in specifically trained manner [15] the correspondence to human vision turns out to be highly dependent on the dataset considered and the type of distortion present in the data. Thus, there has been no “winner” identified among the techniques considered with respect to correspondence to subjective human judgement and objective distortion strength.
3.1 NIQE - Natural Image Quality Evaluator
A NR OU-DU IQM (no reference, opinion unaware & distortion unaware) is based on constructing a collection of quality aware features and fitting them to a multivariate Gaussian (MVG) model. The quality aware features are derived from a simple, but highly regular natural scene statistic (NSS) model. NIQE [16] only uses the NSS features from a corpus of natural images while BRISQUE (see below) is trained on features obtained from both natural and distorted images and also on human judgments of the quality of these images.
The classical spatial NSS model begins with preprocessing: local mean removal and divisive normalisation. Once the new image pixels calculated by the preprocessing have been computed, the image is partitioned into P\(\times \)P image patches. Specific NSS features are then computed from the coefficients of each patch. Then the sharpness of each patch is determined and only patches with higher sharpness are selected. A simple model of the NSS features computed from natural image patches can be obtained by fitting them with an MVG density.
NIQE is applied by computing the 36 identical NSS features from patches of the size P\(\times \)P from the image to be quality analysed, fitting them with the MVG model, then comparing its MVG fit to the natural MVG model. The NIQE Index delivers performance comparable to top performing NR IQA models that require training on large databases of human opinions of distorted images.
3.2 BLIINDS-2 - Blind Image Integrity Notator
BLIINDS-2 [17] uses natural scene statistics models of discrete cosine transform (DCT) coefficients. The algorithm can be divided into four stages. At the first stage the image is subjected to local 2-D DCT coefficient computation. At this point the image is partitioned into equally sized n\(\times \)n blocks, then computing a local 2-D DCT on each of the blocks. The DCT coefficient extraction is performed locally in accordance with the HVS (Human Visual System) property of local spatial visual processing (i.e., in accordance with the fact that the HVS processes the visual space locally), thus, this DCT decomposition is accomplished across several spatial scales.
The second stage applies a generalised Gaussian density model to each block of DCT coefficients, as well as for specific partitions within each DCT block. In order to capture directional information from the local image patches, the DCT block is partitioned directionally into three oriented subregions. A generalised Gaussian fit is obtained for each of the oriented DCT coefficient subregions. Another configuration for the DCT block partition reflects three radial frequency subbands in the DCT block. The upper, middle and lower partitions correspond to the low-frequency, mid-frequency, and high-frequency DCT subbands, respectively. A generalised Gaussian fit is obtained for each of the radial DCT coefficient subregions as well.
The third step computes functions of the derived generalised Gaussian model parameters. These are the features used to predict image quality scores. The fourth and final stage is a simple Bayesian model that predicts a quality score for the image. Here the training is required. The prediction model is the only element of BLIINDS-2 that carries over from BLIINDS-1. The Bayesian approach maximises the probability that the image has a certain quality score given the model-based features extracted from the image. The posterior probability that the image has a certain quality score from the extracted features is modelled as a multidimensional generalised Gaussian density.
3.3 BIQAA - Blind Image Quality Assessment Through Anisotropy
BIQAA [18] is based on measuring the variance of the expected entropy of a given image upon a set of predefined directions. Entropy can be calculated on a local basis by using a spatial/spatial-frequency distribution as an approximation for a probability density function. The generalised Renyi entropy and the normalised pseudo-Wigner distribution (PWD) have been selected for this purpose. As a consequence, a pixel-by-pixel entropy value can be calculated, and therefore entropy histograms can be generated as well. The variance of the expected entropy is measured as a function of the directionality, and it has been taken as an anisotropy indicator. For this purpose, directional selectivity can be attained by using an oriented 1-D PWD implementation. So, the method is based on measuring the averaged anisotropy of the image by means of a pixel-wise directional entropy. BIQAA aims to show that an anisotropy measure can be used to assess both, the fidelity and quality of images.
3.4 BRISQUE
BRISQUE [19] does not require any transformation to another coordinate frame like DCT used by BLIINDS-2. BRISQUE has very low computational complexity, making it well suited for real time applications. The two main stages of BRISQUE are natural scene statistics in the spatial domain and quality evaluation. At the first stage an image is locally normalised (via local mean subtraction and divisive normalisation). Subsequently, 2 parameters are estimated (\(\alpha , \sigma 2\)) from a GGD fit of the normalised pixel data. These form the first set of features that will be used to capture image distortion. To show that pristine and distorted images are well separated in GGD parameter space, a set of pristine images from the Berkeley image segmentation database was taken. Similar kinds of distortions as present in the LIVE image quality database were introduced in each image at varying degrees of severity to form the distorted image set: JPEG 2000, JPEG, white noise, Gaussian blur, and fast fading channel errors. A model for the statistical relationships between neighboring pixels is also built. While normalised coefficients are definitely more homogeneous for pristine images, the signs of adjacent coefficients also exhibit a regular structure, which gets disturbed in the presence of distortion. To model this structure the empirical distributions of pairwise products of neighboring normalised coefficients along four orientations are used.
At the second stage a mapping is learned from feature space to quality scores using a regression module, yielding a measure of image quality. For that purpose a support vector machine (SVM) regressor (SVR) is used. SVMs are popular as classifiers since they perform well in high-dimensional spaces, avoid over-fitting and have good generalisation capabilities. In contrast to algorithms like NIQE and BLIINDS-2, BRISQUE requires training (a pre-trained version is employed in the experiments).
3.5 DIIVINE - Distortion Identification-Based Image Verity and Integrity Evaluation
DIIVINE [20] is based on a 2-stage framework involving distortion identification followed by distortion-specific quality assessment. Most present-day NR IQM algorithms assume that the distorting medium is known - for example, compression, loss induced due to noisy channel etc. Based on this assumption, distortions specific to the medium are modelled and quality is assessed. By far the most popular distorting medium is compression which implies that blockiness and blurriness should be evaluated. DIIVINE targets three common distortion categories, i.e. JPEG compression, JPEG2000 compression, and blur.
In order to extract statistics from distorted images the steerable pyramid decomposition is utilised. The steerable pyramid is an over-complete wavelet transform that allows for increased orientation selectivity. Since NR IQM algorithms are generally trained and tested on various splits of a single dataset (as described above), it is natural to wonder if the trained set of parameters are database specific. However, the training process of DIIVINE is simply a calibration, and once such training is performed, DIIVINE is capable of assessing the quality of any distorted image, since the performance of the algorithm was evaluated on an alternate database. A support vector machine (SVM) regressor (SVR) is used for the classification into the distortion categories.
DIIVINE was actually not developed under the constraint of real-time analysis of images, given that the performance of DIIVINE is as good as leading full-reference quality assessment (FR QA) algorithms.
3.6 BIQI - Blind Image Quality Index
BIQI [21] is also based on a 2-stage framework like DIIVINE. The two steps are image distortion classification based on a measure of how the natural scene statistic (NSS) are modified, followed by quality assessment, using an algorithm specific to the decided distortion. Once trained, an algorithm of the proposed framework does not require further knowledge of the distortion affecting the images to be assessed. The framework is modular in that it can be extended to any number of distortions.
BIQI starts with wavelet transforming an image over three scales and three orientations using the Daubechies 9/7 wavelet basis. The subband coefficients so obtained are parametrised using a generalised Gaussian distribution (GGD). An 18-D vector is formed and it is the representative feature vector for each image.
Given a training and test set of distorted images, a classifier is based on the feature vector to classify the images into five different distortion categories, based on the distortion type JPEG, JPEG2000, WN (white noise), Blur, and FF (fast fading). DIIVINE in contrast only classifies the distortion images into 3 categories. The classifier used is a support vector machine (SVM), which is also utilised in DIIVINE and BRISQUE. BIQI works well for images corrupted by WN and blur and to some extent for JPEG2000 and FF. However, the performance for JPEG compression is less impressive.
4 Experiments
4.1 Experimental Settings
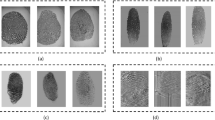
The The Spoofing-Attack Finger Vein Database as used in the “1st Competition on Counter Measures to Finger Vein Spoofing Attacks” as described above and provided by IDIAP Research Institute consists of 440 index finger vein images of both real authentications and fake ones (i.e. attack attempts) to 110 different identities. The samples are split into two different categories (as shown in Fig. 1): Full (printed) images and cropped images where the resolution of the full images is 665 \(\times \) 250 and that of the cropped images is 565 \(\times \) 150 pixel, respectively.

Finger Vein DB samples
For each image in the database quality scores were calculated with the IQM described in Sect. 3. We used the MATLAB implementations from the developers of BIQI, BLIINDS-2, NIQE, DIIVINE, BRISQUEFootnote 1 and BIQAAFootnote 2. In all cases, we used the default settings. We normalised the result data with the result that 0 represents a good quality and 100 the bad one which is already the default result in all cases except BIQAA. Originally the data of BIQAA is between 0 and 1. However, the values are so small that we had to define our own limits for the normalisation. A thorough analysis shows that the values output by the software are all between 0.00005 and 0.05 therefore we used these figures as our limits. Moreover we had to change the “orientation” of the BIQAA quality scores to be conforming to our definition. Summarising, the following formula (1) was built:
In the first experimental stage we consider the distribution of the quality scores only. Our aim was to eventually find a threshold between the values of the real data and the fake ones for the various IQM.
Afterwards, in the second stage, we used the quality scores for a leave-one-out cross validation to get an exact assertion about the classification possibility with NR IQM. To classify our data we used k-nearest neighbours (kNN) classification. Our used k were 1, 3, 5, 7 and 9 for this experiment according to first pre-results. First, we only used one quality score for the classification. In the next step, we combined several quality scores of the different measures into one vector and used this for the kNN-classification. This method allowed us to test all possible combinations of IQM in a simple way. The distance for the kNN-classification was in the first case the difference between the two values and in the second case the distance between the two vectors. At the end, we got the classification accuracy for discriminating real from fake images for all IQM combinations.
4.2 Experimental Results
In Fig. 2, we display the distribution of IQM values for real and fake data. For some cases, we notice a decent separation of the values almost allowing to specify a separation threshold. However, this is not possible for most configurations. In many cases (see e.g. Fig. 3) we could not recognise any differences between the distributions of the metric values for real and fake data because they exhibited almost the same mean and similar spread. That was the reason for employing kNN-Classification.

Quality score distribution (positive examples)
Note that in Fig. 3 we see DIIVINE exhibiting highly overlapping value distributions for real and fake versions of cropped fingervein data, while for the full images a decent separation could be observed. This already indicates that the performance of the metrics in discriminating real from fake data obviously highly depends on the actual dataset under investigation.

Quality score distribution (negative examples)
In the case of kNN-classification with only one IQM, we already obtain good results for the full images. In Table 1 we can see that we got over 99% classification accuracy for BIQI. In this case we already could see the differences of the distributions of the real and the fake values of the quality scores (see Fig. 2a). For this reason, a high accuracy with kNN-classification was already expected. In good correspondence to the value distributions, we also get decent distinction accuracy with DIIVINE (>95%) while BLIINDS is only slightly superior to guessing.
The result is somewhat less convincing for the cropped images as also displayed in Table 1 (right table). Surprisingly, BIQAA, an IQM not well perceived in literature clearly delivers the best result with >80% distinction accuracy while BLIINDS is again the worst IQM for our purpose. Our result conforms well to the competition results [8] where also different texture-based descriptors were used to discriminate real from fake images considering the full images and the cropped ones, respectively.
It seems that the different distortions present in the spoofed data are quite specific in terms of the nature and characteristic of the distortions, which is the only explanation of different IQM performing best on different datasets. In fact, our results confirm the general results on IQM quality prediction performance [14, 15] in that it is highly dataset and distortion dependent which IQM provides the best results.
A further increase in classification accuracy was obtained by the combination of several IQM (a feature vector of IQM values is used instead of a scalar IQM value). Table 2 shows the best combinations for the considered databases from an exhaustive search. For the full images, we have finally found many metric combination configurations with a distinction accuracy of 99.79% while only that one with the lowest k and the lowest number of combined metrics is shown in the table.
For the cropped images, we could improve our results by 5% compared to the single measure results and the best result is over 85% and many results are over 80%.
From the latter table we are not able to confirm the trend of getting best results when combining a larger number of IQM [4]. In order to look into this effect more thoroughly (and to clarify the role of the k-parameter in kNN-classification) we have systematically plotted the results of the exhaustive classification scenarios.
We average all classification results by keeping the number of combined metrics fixed (Fig. 4b) and and by keeping the parameter k fixed (Fig. 4a). Combining more metrics and choosing k large leads to better results on average, where a large number of metrics has a higher influence than a large value for k. Top results in Table 2 for full images do not conform to these average observations, neither in terms of metrics combined, nor in terms of the k value, while for the cropped images the average behaviour is reflected in the best results.

Average quality score
5 Conclusion
We have found a high dependency on the actual dataset under investigation when trying to answer the question about the optimal choice of an image quality measure, even though the cropped images are just a part of the full images.
BIQI and BIQAA are found to be the top performing IQM for full and cropped images, respectively. Therefore, we are not able to identify a clear “winner” among the IQM based on the results analysed while BLIINDS seems to be the “looser”. Still, BLIINDS is used in the best-performing IQM combination for cropped images, while BIQAA (the best-performing IQM for these images) is not.
Since the optimal choice of IQM is dependent on the dataset, it is probably also the nature of attack type that plays a certain role (e.g. if the attack is based on replayed data or if actual artifacts are being used). Thus, the generalisation of the results to unseen attack types might be not straightforward. A similar observation has been made recently in the context of open set spoofing detection where most detector types exhibited extremely degraded attack detection performance on unseen attack data (i.e. data, they have not been trained on) [22].
Notes
- 1.
All available from http://live.ece.utexas.edu/research/quality/.
- 2.
References
Marcel, S., Nixon, M., Li, S. (eds.): Handbook of Biometric Anti-Spoofing. Springer, New York (2014)
Gragnaniello, D., Poggi, G., Sansone, C., Verdoliva, L.: An investigation of local descriptors for biometric spoofing detection. IEEE Trans. Inf. Forensics Secur. 10(4), 849–861 (2015)
Menotti, D., Chiachia, G., Pinto, A., Schwartz, W., Pedrini, H., Falcao, A.X., Rocha, A.: Deep representations for iris, face, and fingerprint spoofing detection. IEEE Trans. Inf. Forensics Secur. 10(4), 864–879 (2015)
Galbally, J., Marcel, S., Fierrez, J.: Image quality assessment for fake biometric detection: application to iris, fingerprint, and face recognition. IEEE Trans. Image Process. 23(2), 710–724 (2014)
Wen, D., Han, H., Jain, A.: Face spoof detection with image distortion analysis. IEEE Trans. Inf. Forensics Secur. 10(4), 746–761 (2015)
Tome, P., Vanoni, M., Marcel, S.: On the vulnerability of finger vein recognition to spoofing. In: 2014 International Conference of the Biometrics Special Interest Group (BIOSIG), pp. 1–10, September 2014
Raghavendra, R., Avinash, M., Marcel, S., Busch, C.: Finger vein liveness detection using motion magnification. In: 2015 IEEE 7th International Conference on Biometrics Theory, Applications and Systems (BTAS), pp. 1–7, September 2015
Tome, P., Raghavendra, R., Busch, C., Tirunagari, S., Poh, N., Shekar, B.H., Gragnaniello, D., Sansone, C., Verdoliva, L., Marcel, S.: The 1st competition on counter measures to finger vein spoofing attacks. In: 2015 International Conference on Biometrics (ICB), pp. 513–518, May 2015
Nguyen, D.T., Park, Y.H., Shin, K.Y., Kwon, S.Y., Lee, H.C., Park, K.R.: Fake finger-vein image detection based on fourier and wavelet transforms. Digit. Signal Proc. 23(5), 1401–1413 (2013)
Tirunagari, S., Poh, N., Bober, M., Windridge, D.: Windowed DMD as a microtexture descriptor for finger vein counter-spoofing in biometrics. In: 2015 IEEE International Workshop on Information Forensics and Security (WIFS), pp. 1–6, November 2015
Raghavendra, R., Busch, C.: Presentation attack detection algorithms for finger vein biometrics: a comprehensive study. In: 2015 11th International Conference on Signal-Image Technology Internet-Based Systems (SITIS), pp. 628–632, November 2015
Kocher, D., Schwarz, S., Uhl, A.: Empirical evaluation of IBP-extension features for finger vein spoofing detection. In: Proceedings of the International Conference of the Biometrics Special Interest Group (BIOSIG’16), Darmstadt, Germany, p. 8 (2016)
Mythily, B., Sathyaseelan, K.: Measuring the quality of image for fake biometric detection: application to finger vein. In: National Conference on Research Advances in Communication, Computation, Electrical Science and Structures (NCRACCESS), pp. 6–11 (2015)
Nouri, A., Charrier, C., Saadane, A., Fernandez-Maloigne, C.: Statistical comparison of no-reference images quality assessment algorithms. In: Proceedings of the Colour and Visual Computing Symposium (CVCS 2013) (2013)
Charrier, C., Saadane, A., Fernandez-Maloigne, C.: Comparison of no-reference image quality assessment machine learning-based algorithms on compressed images. In: Image Quality and System Performance XII. Prooceedings of SPIE, vol. 9396 (2015)
Mittal, A., Soundararajan, R., Bovik, A.C.: Making image quality assessment robust. In: Proceesings of the 46th Asilomar Conference on Signals, Systems and Computers (ASILOMAR) (2012)
Saad, M., Bovik, A.C., Charrier, C.: Blind image quality assessment: a natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 21(8), 3339–3352 (2012)
Gabarda, S., Cristobal, G.: Blind image quality assessment through anisotropy. J. Opt. Soc. Am. A 24, B42–B51 (2007)
Mittal, A., Moorthy, A.K., Bovik, A.C.: No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 21(12), 4695–4708 (2012)
Moorthy, A.K., Bovik, A.C.: Blind image quality assessment: from natural scene statistics to perceptual quality. IEEE Trans. Image Process. 20(12), 3350–3364 (2011)
Moorthy, A.K., Bovik, A.C.: A two-step framework for constructing blind image quality indices. IEEE Signal Process. Lett. 17(5), 513–516 (2010)
Rattani, A., Scheirer, W., Ross, A.: Open set fingerprint spoof detection across novel fabrication materials. IEEE Trans. Inf. Forensics Secur. 10(11), 2447–2460 (2015)
Acknowledgments
This work has been partially supported by the Austrian Science Fund, project no. 27776.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Bhogal, A.P.S., Söllinger, D., Trung, P., Hämmerle-Uhl, J., Uhl, A. (2017). Non-reference Image Quality Assessment for Fingervein Presentation Attack Detection. In: Sharma, P., Bianchi, F. (eds) Image Analysis. SCIA 2017. Lecture Notes in Computer Science(), vol 10269. Springer, Cham. https://doi.org/10.1007/978-3-319-59126-1_16
Download citation
DOI: https://doi.org/10.1007/978-3-319-59126-1_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-59125-4
Online ISBN: 978-3-319-59126-1
eBook Packages: Computer ScienceComputer Science (R0)
