
Abstract
Successful automated detection of short needles during an intervention is necessary to allow the physician identify and correct any misalignment of the needle and the target at early stages, which reduces needle passes and improves health outcomes. In this paper, we present a novel approach to detect needle voxels in 3D ultrasound volume with high precision using convolutional neural networks. Each voxel is classified from locally-extracted raw data of three orthogonal planes centered on it. We propose a bootstrap re-sampling approach to enhance the training in our highly imbalanced data. The proposed method successfully detects 17G and 22G needles with a single trained network, showing a robust generalized approach. Extensive ex-vivo evaluations on 3D ultrasound datasets of chicken breast show 25% increase in F1-score over the state-of-the-art feature-based method. Furthermore, very short needles inserted for only 5 mm in the volume are detected with tip localization errors of \({<}\)0.5 mm, indicating that the tip is always visible in the detected plane.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Ultrasound-guided interventions are broadly applied in medical procedures, e.g. for regional anaesthesia or ablation. However, for a typical 2D US system, bi-manual coordination of the needle and ultrasound (US) transducer for maintaining the perfect alignment is challenging and an inadequate view of the tool leads to an erroneous placement. For this reason, medical specialists need considerable practicing and training to increase the success of interventions. As an alternative, 3D US transducers can improve the quality of the image-guided intervention provided that an automated detection of the needle is used. In such a system, the instrument is conveniently placed in the 3D US field of view and the transducer need not to be further adjusted. Instead, the processing unit automatically localizes and visualizes the entire needle to the medical specialist. Of all available options for finding the needle, an image-based detection technique is most interesting when the important components and devices (e.g. needle, signal generation and transducer) of the system remain unaltered.
Several image-based needle localization techniques have been proposed based on maximizing the intensity over parallel projections [1]. Due to the complexity of in-vivo data, methods that solely rely on brightness of the needle are not robust for localizing thin objects in a cluttered background. Therefore, information regarding the tubular shape of a needle is used by Hessian-based line filtering methods [2]. Furthermore, intensity changes caused by needle movement are used to track the needle in the US data [3]. Nevertheless, arbitrary movements of the transducer and the subject should be avoided for a successful tracking. Attenuation of the US signal due to energy loss beyond the US beam incident with the needle, is also used to detect the position of the needle [4, 5]. However, other attenuating structures in the vicinity of the needle may degrade the accuracy of estimation. Alternatively, supervised needle-voxel classifiers that employ the needle shape and its brightness have shown to be superior to the traditional methods [6]. However, as the needle is assumed to be the longest straight structure in the volume, they typically do not achieve high detection precision and therefore cannot localize the needle when it is partially acquired in the volume.
Recent developments in training convolutional networks (ConvNets) have shown substantial improvement to the performance of automated detection systems in biomedical applications [7], and particularly in US data processing [8]. In this paper, we aim at achieving high precision at a low false negative rate in detecting the needle voxels using ConvNets. Therefore, the system will successfully perform the detection when only a short part of the needle is inserted into the patient’s body, yielding an early correction of inaccurate insertions. The needle is then visualized in an intuitive manner, eliminating the need for advanced manual coordination of the transducer. The main contributions of this paper are: (1) an original approach for classification of needle voxels in 3D US data using ConvNets, (2) a novel update strategy for ConvNets parameters using most-aggressive non-needle samples, which significantly improves the performance on highly imbalanced datasets, and (3) extensive evaluation of the proposed methods on ex-vivo data giving a promising average 83% precision at 76% recall rate.
2 Methods
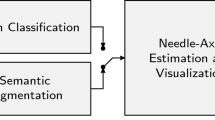
The architecture of the proposed system is depicted in Fig. 1, which consists of two main stages. In the first stage, US voxels belonging to the needle are classified using their triplanar orthogonal views. Second, a pre-defined model of the needle is fitted to the extracted voxels and the cross-section containing the entire needle and the tip is presented to the medical specialist.

Block diagram of our method; (a) full approach; (b) voxel classification stage.
2.1 Needle-Voxel Classification
In order to robustly classify the needle voxels from other echogenic structures such as bones and muscular tissues in the 3D US volumes, we use ConvNets. Our voxel-classification network predicts the label of each voxel from the raw voxel values of local proximity. In a 3D volume, this local neighborhood can simply be a 2D cross-section in any orientation, multiple cross-sections, or a 3D patch. Here, we use three orthogonal cross-sections centered at the reference voxel, which is a compromise with respect to the complexity of the network. We extract triplanar cross-sections of \(21\,\times \,21\) pixels at a resolution of approximately 0.2 mm, which provides enough global shape information and still remains spatially accurate.
ConvNets Architecture: We evaluate two ConvNets architectures based on shared convolutional (ShareConv) and independent convolutional (IndepConv) filters. In ShareConv, a single convolutional filter bank is trained for the three input planes to have the same set of filters for all the planes. In IndepConv, three sets of filter banks are trained independently, each to be convolved with one of the three planes. As depicted in Fig. 1, both architectures consist of four convolutional layers having 32, 48, 64 and 96 filters of \(3\,\times \,3\) kernel size, three fully connected layers having 128, 64 and 2 neurons, and one softmax layer. According to the given number of filters, ShareConv and IndepConv architectures have 2,160 and 6,480 parameters in their convolutional layers, respectively. In both architectures, extracted feature maps after the last convolutional layer are concatenated prior to the fully connected layers [7].
Training: Our dataset is significantly imbalanced due to the small size of a needle compared to the full volume, i.e. approximately only 1 voxel out of 3,000 voxels in a volume belongs to the needle. This is common in representation of an instrument in 3D US volumes. Therefore, in order to avoid a prediction bias towards the majority class, we downsample the negative training data to match the number of needle samples. For an informed sampling of the negative (non-needle) set, we propose an iterative scheme based on bootstrapping [9] to achieve the maximum precision. In the first step, we train our network with uniformly sampled needle and non-needle patches. Training patches are rotated arbitrarily by 90\(^\circ \) steps around the axial axis to improve the orientation invariance. The trained network then classifies the same training set for validation. Finally, misclassified false positives are harvested as the most-aggressive non-needle voxels, which are used to update the network. It is worth mentioning that commonly used methods for imbalanced data, like weighted loss function, do not necessarily improve precision. For example, the majority of our negative set consists of “easy” samples that can be classified beyond the model’s margin and will influence the loss function in their favour.
The ConvNets parameters are trained using stochastic gradient descent and the categorical cross-entropy cost function. All activation functions are chosen to be rectified linear units [10]. Furthermore, for an efficient optimization of the network weights, we divide the learning rate by the exponentially weighted average of recent gradients (RMSProp) [11]. Initial learning rates are chosen to be \(10^{-4}\) and \(10^{-5}\) for train and update iterations, respectively. In order to prevent overfitting, we implement the dropout approach [12] with a probability of 0.5 in the first two fully-connected layers. The trained network computes a label per voxel indicating whether it belongs to the needle or not.
2.2 Needle-Axis Estimation and Visualization
In order to robustly detect the instrument axis in the presence of outliers, we fit a model of the needle to the detected voxels using the RANSAC algorithm [13]. The needle model can be represented by a straight cylinder having a fixed diameter. In cases of large instrument deflection, the model can be adapted to define a parabolic segment. Using the RANSAC algorithm, the cylindrical model that contains the highest number of voxels is chosen to be the estimated needle. As needle diameter is in the order of 1–2 mm (e.g. 1.5 mm for a 17G needle), we set the cylindrical model diameter to be approximately 2 mm.
After successful detection of needle axis, the 2D cross-section of the volume is visualized that contains the plane with the entire needle, which is also perpendicular to coronal (C-scan) planes. This cross-section is the in-plane view of the needle that is very intuitive for physicians to interpret. This ensures that while advancing the needle, the entire instrument is visualized and any misalignment of the needle and target can be corrected without maneuvering the transducer.
3 Experimental Results
The proposed algorithm is evaluated on 3D US data of a chicken breast, acquired with a 5–13 MHz motorized linear array transducer (Philips, Bothell, WA). The dataset consists of 10 trials of a 17G needle and 10 trials of a 22G needle, inserted with various steepness angles between 10 and 35\(^\circ \). Each volume contains \(174\,\times \,189\,\times \,188\) voxels (lat. \(\times \) ax. \(\times \) elev.) at a resolution of approximately 0.2 mm/voxel. We perform five-fold cross-validation across the 20 ex-vivo 3D US volumes. For each fold, we use 4 subsets for training and 1 subset for testing, to make the training and testing data completely distinct.

Multi-dimensional projection of voxels in the test set using the t-SNE algorithm. Red and blue points represent needle and non-needle voxels, respectively.
Classification: Capability of the network to transform the input space to meaningful features is visualized using a multi-dimensional scaling that projects the representation of feature space onto a plane. For this purpose, we applied t-distributed Stochastic Neighbor Embedding (t-SNE) [14] to the first fully-connected layer of the network. The result of the multi-dimensional projection of the test set in one of the folds is depicted in Fig. 2, where close points have similar characteristics in the feature space. As shown, the two clusters are clearly separated based on the features learned by the network.
Performances of our proposed methods are evaluated and shown in Table 1, listing recall, precision and specificity metrics. Furthermore, we compare the results with the approach of [6], which is based on supervised classification of voxels from their responses to hand-crafted Gabor wavelets. As shown, our system outperforms the Gabor features yielding a 25% improvement on F1-score. Furthermore, ShareConv achieves higher precision than IndepConv at approximately similar recall rate. The degraded performance of IndepConv can be explained by the large increase in the number of network parameters in our small-sized data.

Examples of classification results for 17G and 22G needles. (Left) Detected needle voxels in 3D volumes shown in red and ground-truth voxels in green. (Right) Triplanar orthogonal patches classified as true positive, false positive, and false negative.
Figure 3 shows examples of the classification results for 17G and 22G needles. As shown in the left column, detected needle voxels correctly overlap the ground-truth voxels, which results in a good detection accuracy. Furthermore, example patches from true and false positives are visualized, which show a very high local similarity. Most of the false negative patches belong to the regions with other nearby echogenic structures, which distorts appearance of the needle.
Axis Estimation: Because of very high detection precision, estimation of the needle axis is possible even for short needles after a simple RANSAC fitting. The accuracy of our proposed system in localizing the needle axis is evaluated as a function of the needle length as portrayed by Fig. 4. Voxels in the first 2 mm are undetectable, as the minimum distance of extracted 3D patches from the volume borders corresponds to half of a patch length. We use three measurements for defining and evaluating spatial accuracy. The needle position error (\(\varepsilon _{p}\)) is calculated as the average point-line distances between the two end-points of the ground-truth axis and the detected axis. The orientation error (\(\varepsilon _{\mathbf {v}}\)) is the angle between the detected and the ground-truth needle. Moreover, needle tip error (\(\varepsilon _{t}\)) is calculated as the point-plane distance of the ground-truth needle tip and the detected needle plane. As shown in Fig. 4, for needle lengths of approximately 5 mm or larger, needle detection is accurate with \(\varepsilon _p\) of less than 0.5 mm and 0.7 mm for 17G and 22G needles, respectively. The \(\varepsilon _v\) shows more sensitivity to shorter needles and varies more for the 22G needle, which is more difficult to estimate, compared to a thicker needle. Most importantly, the needle tip error, \(\varepsilon _t\), remains lower than 0.5 mm at needle lengths of 5 mm. This shows that after insertion of only 5 mm, the tip will be always visible in the detected plane as their distance is less than the thickness (\(\approx \)1 mm) of US planes.

Needle position error (\(\varepsilon _{p}\)), orientation error (\(\varepsilon _{\mathbf {v}}\)), and tip error (\(\varepsilon _{t}\)) as a function of needle length. Dashed lines represent standard errors of the measured values.
The computational complexity of the proposed system depends on the number of processed voxels. For each voxel, the classification is performed on average in 0.074 ms on a standard PC with a GeForce GTX TITAN X GPU. Therefore, when implementing a naive search with all voxels processed, needle detection can take up to a few minutes. However, in a coarse-fine classification method with a hierarchical grid strategy, we achieved 2.19 s on average per volume.
4 Discussions and Conclusions
Ultrasound-guided interventions are increasingly used to minimize risks to the patient and improve health outcomes. However, the procedure of needle and transducer positioning is extremely challenging and possible external guidance tools would add to the complexity and costs of the procedure. Instead, an automated localization of the needle in 3D US can overcome 2D limitations and facilitate the ease of use of such transducers, while ensuring an accurate needle guidance. In this work, we have introduced a novel image processing system for detecting needles in 3D US data, which achieves very high precision at a low false negative rate. This high precision is achieved by exploiting a dedicated convolutional network for needle detection in 3D US volumes. This network is based on the ConvNets concept, but was improved by proposing a new update strategy to handle highly imbalanced datasets. This strategy improves detection performance and its robustness, by informed re-sampling of non-needle voxels.
The proposed system evaluated on several ex-vivo datasets outperforms classification of the state-of-the-art handcrafted features, achieving 83% precision at 76% recall rate. This shows the capability of ConvNets in modeling more semantically meaningful information in addition to simple shape features, which substantially improves needle detection in complex and noisy 3D US data. Quantitative analysis of localization error with respect to the needle length shows that the tip error is less than 0.5 mm for needles of only 5 mm long. Therefore, the system is able to accurately detect short needles, enabling the physician to correct inaccurate insertions at early stages. Furthermore, the needle is visualized intuitively by its in-plane view while ensuring that the tip is always visible, which eliminates the need for advanced manual coordination of the transducer.
Future work will evaluate the proposed method in more challenging in-vivo datasets with different transducers and acquisition frequencies. Moreover, further analysis is required to limit the complexity of ConvNets with respect to its performance for embedding this technology as a real-time application.
References
Barva, M., Uherčík, M., Mari, J.M., Kybic, J., Duhamel, J.R., Liebgott, H., Hlavac, V., Cachard, C.: Parallel integral projection transform for straight electrode localization in 3-D ultrasound images. IEEE Trans. Ultrason. Ferroelect. Freq. Control (UFFC) 55(7), 1559–1569 (2008)
Uherčík, M., Kybic, J., Zhao, Y., Cachard, C., Liebgott, H.: Line filtering for surgical tool localization in 3D ultrasound images. Comput. Biol. Med. 43(12), 2036–2045 (2013)
Beigi, P., Rohling, R., Salcudean, T., Lessoway, V.A., Ng, G.C.: Needle trajectory and tip localization in real-time 3-D ultrasound using a moving stylus. Ultrasound Med. Biol. 41(7), 2057–2070 (2015)
Pourtaherian, A., Mihajlovic, N., Zinger, S., Korsten, H.H.M., de With, P.H.N., Huang, J., Ng, G.C.: Automated in-plane visualization of steep needles from 3D ultrasound volumes. In: Proceedings of IEEE International Ultrasonics Symposium (IUS), pp. 1–4 (2016)
Mwikirize, C., Nosher, J.L., Hacihaliloglu, I.: Enhancement of needle tip and shaft from 2D ultrasound using signal transmission maps. In: Ourselin, S., Joskowicz, L., Sabuncu, M.R., Unal, G., Wells, W. (eds.) MICCAI 2016. LNCS, vol. 9900, pp. 362–369. Springer, Cham (2016). doi:10.1007/978-3-319-46720-7_42
Pourtaherian, A., Zinger, S., de With, P.H.N., Korsten, H.H.M., Mihajlovic, N.: Benchmarking of state-of-the-art needle detection algorithms in 3D ultrasound data volumes. In: Proceedings of SPIE Medical Imaging, vol. 9415, p. 94152B-1-8 (2015)
Prasoon, A., Petersen, K., Igel, C., Lauze, F., Dam, E., Nielsen, M.: Deep feature learning for knee cartilage segmentation using a triplanar convolutional neural network. In: Mori, K., Sakuma, I., Sato, Y., Barillot, C., Navab, N. (eds.) MICCAI 2013. LNCS, vol. 8150, pp. 246–253. Springer, Heidelberg (2013). doi:10.1007/978-3-642-40763-5_31
Baumgartner, C.F., Kamnitsas, K., Matthew, J., Smith, S., Kainz, B., Rueckert, D.: Real-time standard scan plane detection and localisation in fetal ultrasound using fully convolutional neural networks. In: Ourselin, S., Joskowicz, L., Sabuncu, M.R., Unal, G., Wells, W. (eds.) MICCAI 2016. LNCS, vol. 9901, pp. 203–211. Springer, Cham (2016). doi:10.1007/978-3-319-46723-8_24
Rowley, H.A., Baluja, S., Kanade, T.: Neural network-based face detection. IEEE Trans. Pattern Anal. Mach. Intell. (PAMI) 20(1), 23–38 (1998)
Glorot, X., Bordes, A., Bengio, Y.: Deep sparse rectifier neural networks. In: Proceedings of International Conference on Artificial Intelligence and Statistics (AISTATS), vol. 15, pp. 315–323 (2011)
Tieleman, T., Hinton, G.: Lecture 6.5-RmsProp: divide gradient by running average of its recent magnitude. COURSERA: Neural Netw. Mach. Learn. 4(2), 26–31 (2012)
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958 (2014)
Fischler, M.A., Bolles, R.C.: Random sample consensus: paradigm for model fitting with applications to image analysis. Commun. ACM 24(6), 381–395 (1981)
van der Maaten, L., Hinton, G.: Visualizing high-dimensional data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605 (2008)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Pourtaherian, A. et al. (2017). Improving Needle Detection in 3D Ultrasound Using Orthogonal-Plane Convolutional Networks. In: Descoteaux, M., Maier-Hein, L., Franz, A., Jannin, P., Collins, D., Duchesne, S. (eds) Medical Image Computing and Computer-Assisted Intervention − MICCAI 2017. MICCAI 2017. Lecture Notes in Computer Science(), vol 10434. Springer, Cham. https://doi.org/10.1007/978-3-319-66185-8_69
Download citation
DOI: https://doi.org/10.1007/978-3-319-66185-8_69
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-66184-1
Online ISBN: 978-3-319-66185-8
eBook Packages: Computer ScienceComputer Science (R0)