
Abstract
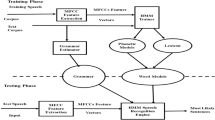
One of the most important parts of the synthesis of natural speech is the correct pause placement. Properly placed pauses in speech affect the perception of information. In this article, we consider the method of predicting pause positions for the synthesis of speech. For this purpose, two speech corpora were prepared in the Kazakh language. The input parameters were vector representations of words obtained from the cluster model and from the algorithm of the canonical correlations analysis. The support vector machine was used to predict the pauses within the sentence. Our results show F-1 = 0.781 for pause prediction.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
The bigram is two words (tokens), which are adjacent in the text box.
- 2.
POS tagging - automatic morphological marking.
References
Parlikar, A., Black, A.W.: Modeling pause-duration for style-specific speech synthesis. In: INTERSPEECH, pp. 446–449. ISCA (2012)
Norkevicius, G., Raskinis, G.: Modeling phone duration of Lithuanian by classification and regression trees, using very large speech corpus. Inf. Lith. Acad. Sci. 19(2), 271–284 (2008)
Bali, K., Nemala, S.K., Ramakrishnan, A.G., Talukdar, P.P.: Duration modeling for Hindi text-to-speech synthesis system. In: INTERSPEECH (2004)
Brown, P.F., et al.: Class-based n-gram models of natural language. Comput. Linguist. 18(4), 467–479 (1992)
Stratos, K. Kim, D., Collins, M., Hsu., D.: A spectral algorithm for learning class-based n-gram models of natural language. In: Zhang, N.L., Tian, J. (eds.) UAI, pp. 762–771. AUAI Press (2014)
Cortes, C., Vapnik, V.: Support vector networks. Mach. Learn. 20, 273–297 (1995)
Sarkar, P., Sreenivasa, R.K.: Data-driven pause prediction for speech synthesis in storytelling style speech. In: Twenty First National Conference on Communications (2015)
Parlikar, A., Black, A.W.: A grammar based approach to style specific phrase prediction. In: INTERSPEECH, pp. 2149–2152. ISCA (2011)
Miller, S., Guinness, J., Zamanian, A.: Name tagging with word clusters and discriminative training. In: HLT-NAACL, pp. 337–342 (2005)
Koo, T., Carreras, X., Collins, M.: Simple semi-supervised dependency parsing. In: Proceedings of ACL 2008: HLT, pp. 595–603. Association for Computational Linguistics, Columbus (2008)
Stratos, K., Collins, M.: Simple semi-supervised POS tagging. In: Blunsom, P., et al. (eds.) VS@HLT-NAACL, pp. 79–87. The Association for Computational Linguistics (2015)
Loh, W.-Y.: Classification and regression tree methods. In: Encyclopedia of Statistics in Quality and Reliability, pp. 315–323. Wiley (2008)
Breiman, L.: Random forests. Mach. Learn. 45, 5–32 (2001)
van Rijsbergen, C.J.: Information Retrieval. Butterworths, London (1979)
Chistikov, P., Khomitsevich, O.: Improving prosodic break detection in a Russian TTS system. In: Železný, M., Habernal, I., Ronzhin, A. (eds.) SPECOM 2013. LNCS (LNAI), vol. 8113, pp. 181–188. Springer, Cham (2013). doi:10.1007/978-3-319-01931-4_24
Chistikov, P.G., Khomitsevich, O.G., Rybin, S.V.: Statistical methods for automatic prosodic break detection in a text-to-speech systems. J. Instrum. Eng. 57(2), 28–32 (2014). (in Russian)
Acknowledgments
This work was financially supported by the Government of the Russian Federation, Grant 074-U01.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Kaliyev, A., Rybin, S.V., Matveev, Y. (2017). The Pausing Method Based on Brown Clustering and Word Embedding. In: Karpov, A., Potapova, R., Mporas, I. (eds) Speech and Computer. SPECOM 2017. Lecture Notes in Computer Science(), vol 10458. Springer, Cham. https://doi.org/10.1007/978-3-319-66429-3_74
Download citation
DOI: https://doi.org/10.1007/978-3-319-66429-3_74
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-66428-6
Online ISBN: 978-3-319-66429-3
eBook Packages: Computer ScienceComputer Science (R0)