
Abstract
Activity recognition plays a key role in providing activity assistance and care for users in intelligent homes. This paper presents a two layer of convolutional neural networks to perform human action recognition using images provided by multiple cameras. We consider one PTZ camera and multiple Kinects in order to offer continuity over the users movement. The drawbacks of using only one type of sensor is minimized. For example, field of view provided by Kinect sensor is not wide enough to cover the entire room. Also, the PTZ camera is not able to detect and track a person in case of different situations, such as the person is sitting or it is under the camera. Also the system will identify abnormalities that can appear in sequences of performed daily activities. The system is tested in Ambient Intelligence Laboratory (AmI-Lab) at the University Politehnica of Bucharest.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The percentage of elderly in todays societies keeps growing. As a consequence, we are faced with the problem of supporting older adults to compensate for their loss of cognitive autonomy in order to continue living independently in their homes as opposed to being forced to live in a care facility. Smart environments have been developed and proven to be able to support end-users and society in general in this era of demographic change [1].
Dementia is frequently invoked for aging population. One symptom of dementia consists in repetition of simple actions such as wandering. Researchers are trying to detect symptoms of dementia at early stages.
This can be detected using an activity recognition system integrated with abnormality detection in daily activities. Activity recognition of older persons daily life should be done indirectly in a comfortable manner using non-intrusive sensors capable to track the user all day long.
The objective of this paper is the development of an non-intrusive technology in support of independent living of older adults in their home. The main focus is on monitoring their daily living activities and recognition of unusual situations. User tracking is performed using multiple cameras: one PTZ camera and multiple Kinect sensor. Also, abnormality in daily activities is detected by analysing the sequence of activities and the duration of each performed activity using a learned user behaviour.
We consider only one person in the supervised room. Generally, users prefer noninvasive sensors. Visual and audio data gathered from cameras, infrared sensors or microphones are more intrusive and can pose privacy concerns, but the acquired performance can be higher. In this paper, we don’t treat privacy implications, we perform activity recognition for a single user.
The rest of the paper is organized as follows: Sect. 2 describes some existing work. System description is given in Sect. 3. Section 4 presents evaluation of the proposed system. Conclusions and future work are given in Sect. 5.
2 Related Works
The main methods of daily activity recognition are based on images analysis acquired from one or more cameras. It requires processing phase for extracting a set of features that will be used with a machine learning algorithm for performing activity recognition.
The main issues are (i) selecting image processing methods in order to acquire good results regardless of the image quality (resolution, noise, the influence of lighting, occlusion between objects), (ii) selecting the machine learning algorithms (iii) optimization of the response time in order to obtain a real-time method.
Frequently used methods are based on Hidden Markov Models (HMM) [2, 3] and Bayesian networks [4] - they can have characterized additional properties. They are not suitable for modeling complex activities that have large state and observation spaces. Parallel HMM are proposed to recognize group activities by factorizing the state space into several temporal processes. Methods based on motion (optical flow) [5] allow analysis of actions in time, modeling long time activities with variable structure of their sub-components. A number of descriptors such as: Histogram of Oriented Gradients (HOG), HOG3D, extended SURF, Harris3D or cuboids [6, 7] have been proposed for image description.
Methods from deep learning show that could revolutionize the results obtained in machine learning [8], by eliminating of the featured extracted from the images. Convolutional neural networks (CNN) is a main method from “deep learning” [9] - represent a class of supervised learning algorithms that can learn a hierarchy of features by building a set of high-level features from a lot of low features [10]. Paper [11] uses CNN for human posture recognition. In [12] CNN are used for study different features to be applied for different sport actions. Also researches are at the beginning. One major problem with this approach consist in choosing the architecture of the CNN. In [13] is presented a method based on a hierarchically CNN that recognize human actions, showing high accuracy and favorable execution time for real time execution. Another approach is based on a combination of motion and appearance features of the human body, based on different methods of temporal aggregation using CNN [14], showing the method is more robust in errors estimation due to a higher accuracy for human posture recognition.
A combination of CNN and hand-crafted features is used in paper [15] that combines HOG and CNN obtaining results that outperform CNNs.
Approaches that use multiple CNNs provide better accuracy for activity recognition compared to the use of a single CNN. In paper [16] is described an architecture using two different recognition streams: spatial and temporal, that are combined by late fusion. The spatial stream performs action recognition from still video frames, and the temporal stream is trained to recognise action from motion in the form of dense optical flow. Decoupling the spatial and temporal networks is exploiting the availability of large existing amounts of annotated image data using pre-training spatial network with the ImageNet dataset [17]. Evaluation of the method described in [16] is performed on large action recognition databases (UCF-101 [18] and HMDB-51 [19]) and results compare better with other similar existing methods (both in accuracy and time).
This paper describes a system for daily activity recognition using two layers of CNNs having as input images provided by multiple cameras that are used for user tracking. The recognition of daily activities is integrated with a method for abnormalities detection in daily activities, especially regarding the wandering symptoms that can appear in case of dementia illness.
3 System Description
The proposed system will track and supervise one user in a smart room. In order to eliminate “black spots” for user detection, this system will consider multiple cameras. Thus, the user will be tracked by multiple cameras, a PTZ camera and a set of Kinect sensors, as given in [20]. RGB images captured from these cameras will be analysed in order to perform daily activity recognition. Based on the promising existing results from [16], we use a two layer CNNs for activity recognition: one spatial CNN and other optical CNN. At the end their results are fusioned using a SVM. There are situations for which the user behaviour must be analysed in order to detect some possible abnormalities. After the activity recognition step, sequences of recognised activities will be analysed in order to detect some changes in user behaviour (for example, wandering behaviour). Thus, we consider a sequence of activities - each activity is being composed of a set of events. Each event will be analysed if it is relevant or not for the current activity (based on the previously observed behaviour of the user). A similarity measure between activities is composed based on the duration of the events and on the number of occurrences in the training event sequences.
The system is designed and tested in the AmI-Lab at the University Politehnica of Bucharest. This laboratory is a rectangular room of 8.5 m \(\times \) 4.5 m that is equipped with regular office furniture. The laboratory is equipped with various tracking sensors, installed in a non-intrusive manner, as described in [20].
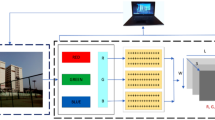
The sensors relevant to this project are Microsoft Kinect sensors and a Samsung PanTilt-Zoom surveillance camera. The schema of the laboratory and the positions of the sensors are presented in the Fig. 1:
-
9 Microsoft Kinect sensors are installed in the AmI-Lab. These sensors contain an RGB camera and a depth sensing circuit. They are able to deliver up to 30 fps of RGB and depth information. The range field according to the official specifications is 0.7 to 6 m. There are areas of the room that are outside of the Kinect sensors view (i.e. room corners).
-
One pan-tilt-zoom Samsung H.264 Network PTZ Dome Camera. The purpose of this device is the tracking of a person throughout the environment. The PTZ camera allows the free movement of the optical sensor: a \(360^{\circ }\) angle on the horizontal plane, an \(180^{\circ }\) angle on the vertical plane. The pan angle generally covers the horizontal orientation of the camera, while the tilt controls the vertical orientation. It is also capable of performing optical zoom (up to 12X). Based on its specifications the streaming rate is 30 fps.

AmI-Lab sensor configuration, as given in [20]
The set of Kinect sensors can continuously track the user inside the room. Also, there are some blind spots the corner of the room, where the Kinect sensors cannot offer information. The PTZ camera has the ability to track the user more accurately than the Kinect sensors. Thus, we combine the PTZ camera with the set of Kinect sensors in order to perform human activity recognition.
3.1 Human Tracking
Supervising a person into a smart room needs to track the user into the room at every moment. This implies to detect and track the user in different poses (standing, sitting, lying), also when located in dead angles into the room (there might be portions of the room which are not covered by the tracking system) or in uncomfortable angles in which the detection has to be performed (a person might be sitting right under the camera or might be keeping his hands crossed in front of the Kinect sensor). All this information is obtained by analyzing images with cluttered background (usually, a room is filled with objects, which sometimes increases the difficulty of detecting a person). In order to avoid such situations, we propose a solution for user tracking by collecting images from multiple and different types of sensors: multiple Kinect sensors and a PTZ camera, as it is presented in [21]. The information gathered from these two types of sensors are combined in order to obtain continuity over the users movement.
For tracking the user, first he needs to be detected and after that user tracking is performed. Integral Channel Features method is used for person detection [22]. 10 channels, as proposed in [21] are used for the person detection: three channels for the color components in the CIELUV color space (L, U, V channels), 6 channels for gradient orientation bins and one channel for gradient magnitude. We used random feature pools of size 5000. A simple boosted classifier and a cascade of 5 boosted classifiers are used for image classifier.
Optical flow computed using the Farneback method is used for human tracking. The flow image contains a large blob representing the moving person. The flow image is converted to grayscale and a threshold is applied (Fig. 2). The largest blob is extracted from the previous image. This blob represents the moving person with a high probability.

Steps in selecting the region of a moving person using optical flow. (a), (b) original successive frames; (c) - optical flow; (d) - blob extraction
Tracking the user with both the PTZ and the Kinect sensors is made as follows: once a Kinect detected a person, it will transmit the location of the person to the PTZ camera. The PTZ will perform the necessary camera movements in order to center the subject. After that, person detection is performed on the acquired images.
3.2 Activity Recognition
Convolutional neural networks represent the earliest successfully established deep architecture. A convolutional neural network classifier comprises a convolutional neural network for feature extraction and a classifier in the last step for classification. Each unit from a CNN layer receives inputs from a set of units located in a small neighbourhood from the previous one. Hidden layers are organized with several planes (called feature map) within which all the units share the same weights. There are two kinds of hidden layers in CNN: convolution layer and subsampling layer. Feature maps can extract different types of features from a previous layer. Thus, convolution layers are used as features extractors. A subsampling layer follows a convolution layer. Each feature map in subsampling layers performs subsampling on the feature map from the previous one, reducing the resolution of the feature map. The number of units from the output layer is equal to the number of predefined activities classes.
Based on the good results obtained for activity recognition described in [16], we use two layers of CNNs: a spatial CNN and an optical CNN, as in Fig. 3.
The Spatial CNN processes individual video frames, performing action recognition from still images. Based on existing results, spatial CNNs are essentially for image classification, as suggested in the proposed architecture used for large-scale image recognition methods [17].
The optical CNN receives as input a set of optical flow images between several consecutive frames (obtained as described in Sect. 3.1). This input will describe the motion between video frames, which makes the recognition easier, as the network does not need to estimate motion implicitly.

Two architecture layer for activity recognition
For spatial and temporal CNN architecture, we use the model described in [17]. The CNN architecture corresponds to the CNN-M-2048 architecture from [23] combined with the architecture proposed in [17]. The weights of the hidden layers use the rectification activation function; maxpooling is performed over 33 spatial windows with stride 2 and the settings for local response normalisation are used as in [17].
Fusion for the final classification is performed with a multi-class linear Support Vector Machine (SVM) [24]. The SVM fusion is composed of a multi-class linear Support Vector Machine trained with the output of the CNNs from the validation dataset. For testing, the SVM predicts the class with the largest score.
3.3 Observing Abnormal Activities
Once the daily activities are identified and the behaviour of the user is learned it is necessary to identify abnormal situations during the daily life of the user. We propose abnormalities detection in the activities performed by people with early stages of dementia. In order to detect anomalies in daily activities we consider the algorithm described in [25].
To analyze and derive useful information about the structure of the performed activity, we consider a sequence of activities. Each activity is composed of a set of events. These events are entered in a matrix m, which contains one row and one column for each of the possible events that may occur in the activity. If an event \({\varvec{e}}_{\varvec{i}}\), occurs in a sequence, then m[i,i] is incremented by 1.
Based on the matrix m, the following aspects can be given:
-
1.
if m[i,j] = n (n is the number of given sequences of activities) then event \(e_{i}\) will occur in every sequence
-
2.
if m[i,i] \(\ge \) m[i,j] = m[j,j] and m[j,i] = 0 then \(e_{j}\) will appear after the \(e_{i}\), otherwise ordering of events \(e_{i}\) and \(e_{j}\) are irrelevant in order.
To decide if an activity performed by the user has any abnormality, whenever a new event occurs, the following need to be checked.
-
1.
whether the event is irrelevant to the currently pursued activity
-
2.
whether all events that need to precede the event have occurred earlier.
We computed a similarity measure that is used for comparing the performed sequence of activities. The similarity measure is composed based on the weights of the contained events. We introduced the duration of an event. For events with lower duration, their weight will be lower. In our case, for each event \(e_i\), we associated a weight w( \(e_{i}\) ) as in Eq. 1:
where:
-
w( \(e_{i}{\_}duration\) ) is the weight associated with event \(e_{i}\) based on its duration relative to the total duration of the actions (from the sequence)
-
w( \(e_i{\_}number\) ) is the weight associated with event \(e_i\) based on its number of occurrences in the training event sequences (it is equal with \(n_{e_{i}}\)/n, where \(n_{e_{i}}\) is the number of occurrences of \(e_i\) in the training event sequences and n the number of training event sequences.
The similarity measure sm, for a sequence e = {\(e_1\), \(e_2\), \(\cdots \), \(e_n\)} is defined as in Eq. 2:
The similarity measure is computed based on the idea the more number of times of an event appears in the actions set, the more similar the activity is to the one existing in the training set. If the value of sm is greater than a threshold, the sequence will be considered similar with the activities usually performed by the user.
4 Evaluation Results
The CNN for activity recognition was evaluated on the MSR Daily Activity dataset 3D [26]. This database was captured using a Kinect device. The dataset consists of 320 scenes each having the depth map, the skeleton position and the RGB video. There are 16 actions in the dataset: walk, sit down, stand up, sit still, use laptop, read book, drink, write on paper, eat, toss paper, play guitar, use vacuum cleaner, play game, call phone, cheer up, lie down on sofa. Each action is performed by 10 subjects for a number of two times: once in standing position and once in sitting position. We extend the database with a set of images with images captured from the AmI-Lab, named AmI Database. In this laboratory there is a cluttered background - many objects can be distinguished in the background, including wooden panels, which can be easily mistaken for patches of human skin, due to the similarity of colors.
For both CNNs we used a CNN architecture for both object detection and recognition [17]. The parameters used for the training phase are based on the similarly CNN architecture from [27] which uses stochastic gradient with momentum (0.8). For each iteration, the network forwards a batch of 128 samples. All convolutions use rectified linear activation functions. Weights are initialization using automatically determined based on the number of input neurons. To reduce the chances of overfitting, we apply dropout on the fully-connected layers with a probability of 76%. The learning rate is set to 103 and it is decreased by a factor of 50 at every epoch, the training is stopped after (40 epochs).
We train the multi-class Support Vector Machine using the implementation from the scikit-learn toolbox [28]. We used a linear kernel and default scikit-learn regularization parameter C = 1 with the square of the hinge loss as loss function.
Activity recognition was tested first onthe MSR Daily Activity Dataset. In this case, we use only part of these activities. We are interested only in three general types of such activities: walking, standing and sitting. Sit down activities are composed of: sit still, read book and eat. All other activities from the MSR Daily Activity dataset are ignored.
We divided the dataset into training, validation and test sets. The training set contains 7 subjects. The validation set is used in order to obtain the configuration with the highest accuracy. The confusion matrix obtained for these three types of activities is given in Table 1. Based on the results given in Table 1, the recognition rate is good. Also, there are some misclassified activities. This happens between activities walking and standing. These situations appear in case of a lower speed of the user when these two activities can’t be distinguished.
In order to see if our model is suitable for real-time classification applications, we made experiments which measure the classification time. The timed obtained for classification of about 0.0017 s per frame which, from our point of view, is low enough for real time classification.
As can be seen from Table 1, the proposed solution that combines the two convolutional networks together with the SVM improves the existing results compared with the recognised activities from the analysed database, as given in [26].
For testing the algorithm of finding abnormalities in daily activities we consider different activities composed of sequence of events. In our case an event will be an activity recognised by the two layer of CNNs: walking, standing and sitting. We create a training set with images acquired in Ami-Lab from by tracking the user with the set of cameras existing there: the PTZ and the set of Kinects. We recorded 20 h of activities composed of walking, sitting and standing. The recorded activities are splitted in sequences of 30 min based on which we computed the matrix m and the value of \(n_{e_{i}}\). For testing the algorithm, we collect another 5 h of activities, also splitted in sequences of 30 min. For testing database, users perform activities in completely different order than the existing ones in the training database. Also, the activities are executed with different duration, especially shorter walking activities were interleaved between standing and sitting ones. The effectiveness of the detected abnormality in a sequence of daily activities depends on the training event sequences. The training event sequences should reflect all the possibilities for sequences of activities that can be performed without any abnormality.
5 Conclusion and Future Work
Activity recognition and abnormality detection in daily activities is an important field of research with real applicability in medical applications. This paper describes a system that supervises a user using multiple cameras, recognises performed activities and detects abnormalities regarding his daily behaviour. Activity recognition is performed through deep learning using a two layer of CNNs, one spatial CNN and other optical CNN, at the end their results are fusioned using a SVM. Abnormality in daily activities is detected by analysing the sequence of activities and the duration of each performed activity using a learned user behaviour. As future work, we will extend the set of activities that are used for both recognition and abnormality detection. Also, for a better detection of abnormalities in daily activities, different attributes will be associated with daily activities (for example: number of performed steps or the users trajectory through the room).
References
Popescu, D., Dobrescu, R., Maciuca, A., et al.: Smart sensor network for continuous monitoring at home of elderly population with chronic diseases. In: 20th Telecommunications Forum, pp. 603–606 (2012)
Chiperi, M., Mocanu, I., Trascau, M.: Human tracking using multiple views. In: 40th International Conference on Telecommunications and Signal Processing. IEEE Press (2017)
Zhu, C., Sheng, W.: Human daily activity recognition in robotassisted living using multisensor fusion. In: IEEE International Conference on Robotics and Automation, pp. 2154–2159 (2009)
Vinh, L., Lee, S., Le, H., Ngo, H., Kim, H., Han, M., Lee, Y.-K.: Semimarkov conditional random fields for accelerometer-based activity recognition. Appl. Intell. 35, 226–241 (2011)
Lara, O.D., Labrador, M.A.: A mobile platform for real time human activity recognition. In: Proceedings of IEEE Conference on Consumer Communications and Networks, pp. 667–671 (2012)
Tang, K., Fei-Fei, L., Koller, D.: Learning latent temporal structure for complex event detection. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1250–1257 (2012)
Wang, H., Schmid, C.: Action recognition with improved trajectories. In: IEEE International Conference on Computer Vision, pp. 3551–3558 (2013)
Jiang, Z., Lin, Z., Davis, L.S.: A unified tree-based framework for joint action localization, recognition and segmentation. Comput. Vis. Image Underst. 117, 1345–1355 (2013)
Can Deep Learning Revolutionize Mobile Sensing? http://niclane.org/pubs/lane_hotmobile15.pdf
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems, pp. 1097–1105 (2012)
Ji, S., Xu, W., Yang, M., et al.: 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 35, 221–231 (2013)
Toshev, A., Szegedy, C.: DeepPose: human pose estimation via deep neural networks. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1653–1660 (2014)
Sun, L., Jia, K., Chan, T., et al.: DL-SFA: deeply-learned slow feature analysis for action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2625–2632 (2014)
Jin, C.-B., Li, S., Do, T.D., Kim, H.: Real-time human action recognition using CNN over temporal images for static video surveillance cameras. In: Ho, Y.-S., Sang, J., Ro, Y.M., Kim, J., Wu, F. (eds.) PCM 2015. LNCS, vol. 9315, pp. 330–339. Springer, Cham (2015). doi:10.1007/978-3-319-24078-7_33
P-CNN: Pose-Based CNN Features for Action Recognition. https://hal.inria.fr/hal-01187690/file/PCNN_cheronICCV15.pdf
Zhang, T., Zeng, Y., Xu, B.: HCNN: a neural network model for combining local and global features towards human-like classification. Int. J. Pattern Recogn. Artif. Intell. 30, 1–19 (2016)
Two-Stream Convolutional Networks for Action Recognition in Video. https://papers.nips.cc/paper/5353-two-stream-convolutional-networks-for-action-recognition-in-videos.pdf
Large scale visual recognition challenge. http://www.image-net.org/challenges/LSVRC/2010/
UCF101: A dataset of 101 human actions classes from videos in the wild. http://crcv.ucf.edu/data/UCF101.php
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T.: HMDB: a large video database for human motion recognition. In: IEEE International Conference on Computer Vision, pp. 2556–2563 (2011)
Ismail, A.A., Florea, A.M.: Multimodal indoor tracking of a single elder in an AAL environment. In: van Berlo, A., Hallenborg, K., Rodríguez, J., Tapia, D., Novais, P. (eds.) mbient Intelligence - Software and Applications. AISC, vol. 219, pp. 137–145. Springer, Heidelberg (2013). doi:10.1007/978-3-319-00566-9_18
Integral Channel Features. http://pages.ucsd.edu/ztu/publication/dollarBMVC09ChnFtrs_0.pdf
Return of the devil in the details: delving deep into convolutional nets. http://www.bmva.org/bmvc/2014/files/paper054.pdf
Crammer, K., Singer, Y.: On the algorithmic implementation of multiclass kernelbased vector machines. J. Mach. Learn. Res. 2, 265–292 (2001)
Karamath, H.A., Amalarethinam, D.I.G.: Detecting abnormality in activities performed by people with dementia in a smart environment. Int. J. Comput. Sci. Inf. Technol. 5, 2453–2457 (2014)
Wang, J., Liu, Z., Wu, Y., Yuan, J.: Mining actionlet ensemble for action recognition with depth cameras. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1290–1297 (2012)
Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Proceedings of the Computer Vision and Pattern Recognition (2015)
Scikit-learn. http://scikit-learn.org/
Acknowledgments
This work has been funded by University Politehnica of Bucharest, through the Excellence Research Grants Program, UPB GEX. Identifier: UPB-EXCELENTA-2016 Optimizarea Activitatilor Zilnice Folosind Deep Learning Implementata pe Sisteme Reconfigurabile/Daily Activities Using Deep Learning Implemented on FPGA, Contract number 8/26.09.2016 (code 341).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Mocanu, I., Cramariuc, B., Balan, O., Moldoveanu, A. (2017). A Framework for Activity Recognition Through Deep Learning and Abnormality Detection in Daily Activities. In: Battiato, S., Gallo, G., Schettini, R., Stanco, F. (eds) Image Analysis and Processing - ICIAP 2017 . ICIAP 2017. Lecture Notes in Computer Science(), vol 10485. Springer, Cham. https://doi.org/10.1007/978-3-319-68548-9_66
Download citation
DOI: https://doi.org/10.1007/978-3-319-68548-9_66
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-68547-2
Online ISBN: 978-3-319-68548-9
eBook Packages: Computer ScienceComputer Science (R0)
