
Abstract
Random Forests (RF) of tree classifiers are a popular ensemble method for classification. RF are usually preferred with respect to other classification techniques because of their limited hyperparameter sensitivity, high numerical robustness, native capacity of dealing with numerical and categorical features, and effectiveness in many real world classification problems. In this work we present ReForeSt, a Random Forests Apache Spark implementation which is easier to tune, faster, and less memory consuming with respect to MLlib, the de facto standard Apache Spark machine learning library. We perform an extensive comparison between ReForeSt and MLlib by taking advantage of the Google Cloud Platform (https://cloud.google.com). In particular, we test ReForeSt and MLlib with different library settings, on different real world datasets, and with a different number of machines equipped with different number of cores. Results confirm that ReForeSt outperforms MLlib in all the above mentioned aspects. ReForeSt is made publicly available via GitHub (https://github.com/alessandrolulli/reforest).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
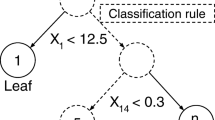

References
Anguita, D., Ghio, A., Oneto, L., Ridella, S.: In-sample and out-of-sample model selection and error estimation for support vector machines. IEEE Trans. Neural Netw. Learn. Syst. 23(9), 1390–1406 (2012)
Baldi, P., Sadowski, P., Whiteson, D.: Searching for exotic particles in high-energy physics with deep learning. Nature Commun. 5(4308), 1–9 (2014)
Bishop, B.M.: Neural Networks for Pattern Recognition. Oxford University Press, Oxford (1995)
Breiman, L.: Random forests. Mach. Learn. 45(1), 5–32 (2001)
Chen, J., et al.: A parallel random forest algorithm for big data in a spark cloud computing environment. IEEE Transactions on Parallel and Distributed Systems (2016, in press)
Chung, S.: Sequoia forest: random forest of humongous trees. In: Spark Summit (2014)
Dean, J., Ghemawat, S.: MapReduce: simplified data processing on large clusters. Commun. ACM 51(1), 107–113 (2008)
Efron, B.: Bootstrap methods: another look at the jackknife. Ann. Stat. 7(1), 1–26 (1979)
Fernández-Delgado, M., Cernadas, E., Barro, S., Amorim, D.: Do we need hundreds of classifiers to solve real world classification problems? JMLR 15(1), 3133–3181 (2014)
Genuer, R., Poggi, J., Tuleau-Malot, C., Villa-Vialaneix, N.: Random forests for big data. arXiv preprint arXiv:1511.08327 (2015)
Germain, P., Lacasse, A., Laviolette, A., ahd Marchand, M., Roy, J.F.: Risk bounds for the majority vote: from a PAC-Bayesian analysis to a learning algorithm. JMLR 16(4), 787–860 (2015)
Hernández-Lobato, D., Martínez-Muñoz, G., Suárez, A.: How large should ensembles of classifiers be? Pattern Recogn. 46(5), 1323–1336 (2013)
Loosli, G., Canu, S., Bottou, L.: Training invariant support vector machines using selective sampling. In: Large Scale Kernel Machines (2007)
Meng, X., et al.: Mllib: Machine learning in apache spark. J. Mach. Learn. Res. 17(34), 1–7 (2016)
Vapnik, V.N.: Statistical Learning Theory. Wiley, New York (1998)
Wainberg, M., Alipanahi, B., Frey, B.J.: Are random forests truly the best classifiers? J. Mach. Learn. Res. 17(110), 1–5 (2016)
Wakayama, R., et al.: Distributed forests for MapReduce-based machine learning. In: Asian Conference on Pattern Recognition (2015)
Yuan, G., Ho, C., Lin, C.: An improved GLMNET for l1-regularized logistic regression. J. Mach. Learn. Res. 13, 1999–2030 (2012)
Zaharia, M., Chowdhury, M., Franklin, M.J., Shenker, S., Stoica, I.: Spark: cluster computing with working sets. HotCloud 10(10–10), 1–9 (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Lulli, A., Oneto, L., Anguita, D. (2017). ReForeSt: Random Forests in Apache Spark. In: Lintas, A., Rovetta, S., Verschure, P., Villa, A. (eds) Artificial Neural Networks and Machine Learning – ICANN 2017. ICANN 2017. Lecture Notes in Computer Science(), vol 10614. Springer, Cham. https://doi.org/10.1007/978-3-319-68612-7_38
Download citation
DOI: https://doi.org/10.1007/978-3-319-68612-7_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-68611-0
Online ISBN: 978-3-319-68612-7
eBook Packages: Computer ScienceComputer Science (R0)