
Abstract
Similarity joins represent a useful operator for data mining, data analysis and data exploration applications. With the exponential growth of data to be analyzed, distributed approaches like MapReduce are required. So far, the state-of-the-art similarity join approaches based on MapReduce mainly focused on the processing of vector data with less than one hundred dimensions. In this paper, we revisit and investigate the performance of different MapReduce-based approximate k-NN similarity join approaches on Apache Hadoop for large volumes of high-dimensional vector data.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
- 2.
- 3.
Note that the effectiveness of the distance function and feature extraction mapping from \(o_i\) to \(v_i\) is the subject of similarity modeling.
- 4.
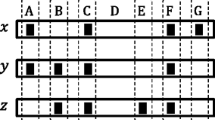
The presence of k lower and k higher z-values of database objects is ensured during the partitioning phase by replication.
References
Awad, G., Fiscus, J., Michel, M., Joy, D., Kraaij, W., Smeaton, A.F., Quénot, G., Eskevich, M., Aly, R., Jones, G.J.F., Ordelman, R., Huet, B., Larson, M.: TRECVID 2016: evaluating video search, video event detection, localization, and hyperlinking. In: Proceedings of TRECVID 2016. NIST, USA (2016)
Čech, P., Kohout, J., Lokoč, J., Komárek, T., Maroušek, J., Pevný, T.: Feature extraction and malware detection on large HTTPS data using MapReduce. In: Amsaleg, L., Houle, M.E., Schubert, E. (eds.) SISAP 2016. LNCS, vol. 9939, pp. 311–324. Springer, Cham (2016). doi:10.1007/978-3-319-46759-7_24
Chavez Gonzalez, E., Figueroa, K., Navarro, G.: Effective proximity retrieval by ordering permutations. IEEE Trans. Pattern Anal. Mach. Intell. 30(9), 1647–1658 (2008)
Datar, M., Immorlica, N., Indyk, P., Mirrokni, V.S.: Locality-sensitive hashing scheme based on p-stable distributions. In: Proceedings of the Twentieth Annual Symposium on Computational Geometry, SCG 2004, NY, USA, pp. 253–262. ACM, New York (2004)
Dean, J., Ghemawat, S.: MapReduce: simplified data processing on large clusters. Commun. ACM 51(1), 107–113 (2008)
Ferhatosmanoglu, H., Tuncel, E., Agrawal, D., Abbadi, A.E.: Approximate nearest neighbor searching in multimedia databases. In: Proceedings 17th International Conference on Data Engineering, pp. 503–511 (2001)
Giacinto, G.: A nearest-neighbor approach to relevance feedback in content based image retrieval. In: Proceedings of the 6th ACM International Conference on Image and Video Retrieval, CIVR 2007, NY, USA, pp. 456–463. ACM, New York (2007)
Guðmundsson, G.Þ., Amsaleg, L., Jónsson, B.Þ., Franklin, M.J.: Towards engineering a web-scale multimedia service: a case study using spark. In: Proceedings of the 8th ACM on Multimedia Systems Conference, MMSys 2017, Taipei, Taiwan, pp. 1–12, 20–23 June 2017 (2017)
Kohout, J., Pevny, T.: Unsupervised detection of malware in persistent web traffic. In: 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2015)
Lokoč, J., Kohout, J., Čech, P., Skopal, T., Pevný, T.: k-NN classification of malware in HTTPS traffic using the metric space approach. In: Chau, M., Wang, G.A., Chen, H. (eds.) PAISI 2016. LNCS, vol. 9650, pp. 131–145. Springer, Cham (2016). doi:10.1007/978-3-319-31863-9_10
Lu, W., Shen, Y., Chen, S., Ooi, B.C.: Efficient processing of k nearest neighbor joins using mapreduce. Proc. VLDB Endow. 5(10), 1016–1027 (2012)
Marin, J.M., Mengersen, K., Robert, C.P.: Bayesian modelling and inference on mixtures of distributions. In: Dey, D., Rao, C. (eds.) Bayesian Thinking: Modeling and Computation, Handbook of Statistics, vol. 25, pp. 459–507. Elsevier, Amsterdam (2005)
Mera, D., Batko, M., Zezula, P.: Towards fast multimedia feature extraction: Hadoop or storm. In: 2014 IEEE International Symposium on Multimedia, pp. 106–109, December 2014
Moise, D., Shestakov, D., Gudmundsson, G., Amsaleg, L.: Indexing and searching 100m images with Map-Reduce. In: International Conference on Multimedia Retrieval, ICMR 2013, Dallas, TX, USA, 16–19 April 2013, pp. 17–24 (2013)
Moise, D., Shestakov, D., Gudmundsson, G., Amsaleg, L.: Terabyte-scale image similarity search: experience and best practice. In: Proceedings of the 2013 IEEE International Conference on Big Data, 6–9 October 2013, Santa Clara, CA, USA, pp. 674–682 (2013)
Novak, D., Batko, M.: Metric index: an efficient and scalable solution for similarity search. In: Proceedings of the 2009 Second International Workshop on Similarity Search and Applications, pp. 65–73. IEEE, Washington, DC (2009)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. CoRR abs/1409.1556 (2014)
Song, G., Rochas, J., Huet, F., Magoulès, F.: Solutions for processing k nearest neighbor joins for massive data on MapReduce. In: 2015 23rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, pp. 279–287, March 2015
Stupar, A., Michel, S., Schenkel, R.: RankReduce - processing k-nearest neighbor queries on top of MapReduce. In: LSDS-IR (2010)
Yao, B., Li, F., Kumar, P.: K nearest neighbor queries and kNN-joins in large relational databases (almost) for free. In: ICDE (2010)
Zaharia, M., Xin, R.S., Wendell, P., Das, T., Armbrust, M., Dave, A., Meng, X., Rosen, J., Venkataraman, S., Franklin, M.J., Ghodsi, A., Gonzalez, J., Shenker, S., Stoica, I.: Apache spark: a unified engine for big data processing. Commun. ACM 59(11), 56–65 (2016)
Zezula, P., Amato, G., Dohnal, V., Batko, M.: Similarity Search: The Metric Space Approach. Advances in Database Systems. Springer, Boston (2006). doi:10.1007/0-387-29151-2
Zhang, C., Li, F., Jestes, J.: Efficient parallel kNN joins for large data in MapReduce. In: Proceedings of the 15th International Conference on Extending Database Technology, EDBT 2012, NY, USA, pp. 38–49. ACM, New York (2012)
Zhu, P., Zhan, X., Qiu, W.: Efficient k-nearest neighbors search in high dimensions using MapReduce. In: 2015 IEEE Fifth International Conference on Big Data and Cloud Computing, pp. 23–30, August 2015
Acknowledgments
This project was supported by the GAČR 15-08916S and GAUK 201515 grants.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Čech, P., Maroušek, J., Lokoč, J., Silva, Y.N., Starks, J. (2017). Comparing MapReduce-Based k-NN Similarity Joins on Hadoop for High-Dimensional Data. In: Cong, G., Peng, WC., Zhang, W., Li, C., Sun, A. (eds) Advanced Data Mining and Applications. ADMA 2017. Lecture Notes in Computer Science(), vol 10604. Springer, Cham. https://doi.org/10.1007/978-3-319-69179-4_5
Download citation
DOI: https://doi.org/10.1007/978-3-319-69179-4_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-69178-7
Online ISBN: 978-3-319-69179-4
eBook Packages: Computer ScienceComputer Science (R0)