
Abstract
The attention scheme is believed to align the words with objects in the task of image caption. Considering the location of objects vary in the image, most attention scheme use the set of region features. Compared with global feature, the region features are lower level features. But we prefer high-level features in image caption generation because words are high-level concepts. So we explore a new attention scheme based on the global feature and it can be appended to the original image caption generation model directly. We show that our global feature based attention scheme (GFA) can achieve the same improvement as the traditional region feature based attention scheme. And our model can achieve aligning the words with different regions as the traditional attention scheme. We test our model in Flickr8k dataset and Flickr30k dataset.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
Describing the visual scene or some details after a glance of an image is simple for people but quite difficult for visual recognition models. The task has great impact in some areas such as helping the blind people perceive the environment. So it becomes a focus in the computer vision community.
The task involves some subproblems such as object detection, behavior recognition etc. Therefore, most previous works are based on these tasks, they rely on hardcoded visual concepts and sentence templates [5, 12]. However, the sentences templates limit the variety of generated sentences. But with the success of recurrent neural networks in processing the sequence problems like machine translation [25], some neural encoder-decoder models have been explored [23]. The neural encoder-decoder models take the task as a translation problem, which translate the image information to text information. In these models, the encoder is convolutional neural networks, which get a great success in some computer vision problems such as image classification, object detection, and the decoder is recurrent neural networks, which show a great potential in handling the sequence. And without the sentence templates, the generated sentences are more flexible and more similar to natural language.
Recently, with the attention scheme, which usually align each word of the sentence with some regions in the image, the neural encoder-decoder models make a great progress. However, these attention schemes need to get the region features and change the initial model structure. But our attention scheme is based on the global feature of the image, which is the input of the initial model. Thus we do not need extra procedure to get the feature of image regions. In summary, our main contribution is we propose a new attention scheme without any region features of the image, which can be directly appended to the initial model.
2 Related Work
2.1 Convolutional Neural Networks for Feature Extraction
Recently, convolutional neural networks achieve great success in the field of computer vision like image classification [8, 19, 20, 22], object detection [6, 7], image annotation. The success of CNNs is believed to be the result of its powerful ability to extract features. The feature extracted by CNNs works better than most of outstanding handcrafted features like HOG [3] and SIFT [16]. Thanks to the remarkable performance of the CNNs in the object detection and image annotation, which are the subproblems of image caption, we can represent nearly all the image information in a simple way. And it’s comprehensive representation of objects and attribute, which build an essential foundation for the image caption task.
2.2 Image Caption with Templates
Based on the previous work of the image processing and sentence processing, a number of approaches take the task as a retrieval problem. They break up all the samples in the training set and the predict result is the combination of the result, which is stitched from the training annotations [13,14,15]. Other approaches generate caption with fixed templates whose place are filled with the results of object detection, attribute classification and scene recognition. But these approaches limit the variety of possible outputs.
2.3 Image Caption with Neural Networks
Inspired by the success of sequence-to-sequence encoder-decoder frameworks in the field of machine translation [1, 2, 19, 21], the image caption task is regard as translating from image to text. [17] first develop a multimodal recurrent neural networks to translate the image into the text. [11] propose a feed forward neural network with a multimodal log-bilinear model to predict the next word given the previous output and image. [9] simplify the model and replace the feed forward network with a LSTM as the decoder, it also shows that the image only need to be input into the LSTM at the beginning of the model. [21] developes a new method to align the text with image, especially the word with region, by the output of bidirectional RNN [18] and the object detection results of the image from R-CNN [13]. The result of alignment in the joint embedding helps the caption generation. [4] replaces the vanilla recurrent neural networks with a multilayer LSTM as the decoder to generate caption. In their models, the first and second LSTM produce a joint representation of the visual and language inputs, the third and fourth LSTM transform the outputs of the previous LSTMs to produce the output.
2.4 Attention Scheme for Image Caption
Recently, attention scheme has been integrated into the encoder-decoder frameworks. [26] learns a latent alignment from scratch by incorporating the attention mechanisms when generating the word. [24] introduces a method to incorporate the high-level semantic concepts into the encoder-decoder approach. [27] reveals several architectures for augmenting high-level attributes from image to image representation for description generation. In all above attention schemes, some of them use the region features, which usually are mid-level features. Though [10] uses high-level semantic concepts, the high-level feature is extracted by manual selection which is unpractical for large data.
3 Our Model
In this section, we introduce our end-to-end neural network model. Our model is based on the encoder-decoder network in natural language translation. So it’s a probabilistic framework, which directly maximize the probability of the correct sentence given the image. But the difference between the natural language translation model and our model is we use the CNNs as the encoder for the image, not the recurrent neural network for sequence input. Both of the models use recurrent neural networks as the decoder to generate the target sequence output. Therefore the problem can be solved by the following formulation
where \(\theta \) is the parameters of our model, I is the image, and S is the correct description. Because S is a sequence data, its length varies in different sentences. Therefore, we apply the chain rule to model the joint probability over \({S_0,\dots ,S_N}\) where N is the length of this particular sentence as
And given the image information and the information extracted from syntax structure, the attention scheme we used can control the model to focus on specific part of images information and decide the output content. Therefore the complete version of our model can be written as
where \(\theta \) is the parameter of basic model, \(\theta _a\) is the parameter of attention scheme, \(f_a(\cdot )\) means the attention scheme.
3.1 Encode Images
Following prior works [10, 12], we regard the generated description as the combination of objects and their attributes which can be represented as some high-level features. Then we follow the work of NIC [23] to encode the image with CNNs, and we use the VGGNet as the image feature extractor. The VGGNet is pretrained on ImageNet, it can classify 1000 classes. So we believe it has powerful ability to extract features from image, which can obtain near all information we need such as object classes, attributes etc. Concretely, in our model, we use the 16-layers version of VGG-Net. Following NIC, we only use the second full connected layer in the CNNs, it’s a 4096-dimensional vector. Since our model need to process both image information and text information, so we need convert all information we needed into the multimodal space. The encoder can be represented as
where I represents the image, \({CNN_{\theta _c}(I)}\) translates the image pixel information into 4096-dimensinal feature vector, \(W_I\in R^{m\times d}\) is weight to be learned, which translate the image information into the multimodal space, \(b_I\) is the bias. We set the activation function \(f(\cdot )\) to the rectified linear unit (ReLU), which computes \(f:x\mapsto \max (x,0)\).

The image encoding procedure.
Specifically, there are two reasons why we use the second full connected layer of the CNNs. On the one hand, the features extracted from the convolutional layer are distributed, and the data has stronger sparsity with the convolutional layer going deeper, while the bottom layer extract the underlying features we do not need. On the other hand, for the three full connected layers, we’d like to choose the top layers because we think it contains more higher-level features. But the last full connected layer has 1000 dimensions, which corresponds to the 1000 classes in the ImageNet Large Scale Visual Recognition Challenge, not all the 1000 classes are included in our image. Therefore, we choose the features extracted from the second full connected layer in VGGNet to represent the image. And before encoding the image features, we use ReLU function to remove the negative output (Fig. 1).
3.2 Decoding Sentences
Since our target is a sentence, which is in the form of a sequence of words, our decoder need to be able to handle sequence problem. So we choose the recurrent neural networks, it achieved a great success in sequence problem, especially in machine translation [25], which is the base of our model. In our model, we build a recurrent neural network which has 2 inputs, image and previous output. Both of them need be encoded into the multimodal space, the process for image has been declared in Sect. 3.1. When encoding the previous output, which is a word, we traverse all the sentences in the training data to formulate a vocabulary. And following [10], we cut out the words whose frequency is lower than the threshold, which is 5 in our model. And for convenience, we add the start and end symbol to each sentence. Then every word has a unique code by the method of one-hot encoding. The encoding result is sparse and high dimensional, thus we need to convert it into the dense multimodal space in the following from
where \(s_{t-1}\) is the output of RNNs at time step \(t-1\), which is the encoding result by the method of one-hot encoding, \(x_t\) is the encoding result in the multimodal space, \(W_s\) is the weight to be learned, which convert the word into the multimodal space, \(b_s\) is the bias.
Then with the multimodal data as inputs and the sequence of words as the labels, we can train our model by minimizing the cross-entropy loss. The full recurrent neural networks can be represented by the following formulations
where \(x_t\) is the input to the recurrent neural networks at time step t, v is the image encoding result in the multimodal result, \(h_t\) and \(h_{t-1}\)are the hidden layers state at time step t and \(t-1\), \(s_t\) is the output of RNNs at time step t, \(softmax(\cdot )\) is the softmax function. We use the Stochastic Gradient Descent algorithm to train our model (Fig. 2).

The word decoding procedure.
3.3 Global Feature Based Attention Scheme
Attention scheme is the key of a good model when generating the description. Because the image is in a static state, but the description is dynamitic (i.e. the description is a list of words which are generated over time). So when generating different words, we need focus on different regions in the image, sometimes maybe the center of the image, sometimes just the background of the full image. It means the input should be dynamic not static. So when we generating the word, we need to decide which part of image information to be focused based on the content we previous generated, it’s the core insight of attention scheme. The most similar model to our global feature based attention scheme (GFA) is [26], but the difference is we do not use features extracted from regions but from the full image and we use a different activation function.
In our model, we use a simple feed forward network with only one hidden layer to serve as attention scheme to decide the weights of different part of image information. The scheme can be represented as the following formulation
where v is the image feature in the multimodal space, \(s_{t-1}\) is the previous output, \(h_t^a\) is the hidden layer state of our feed forward network at time step t, \(\sigma (\cdot )\) means we use sigmoid function as the active function, \(o_t^a\) is the weight, \(\bigodot \) means we use element-wise product, \(W_g,W_y,W_m\) are weights to be learned (Fig. 3).

Our global feature based attention scheme. And \(\bigodot \) means the element-wise product.
The reason why we use sigmoid function is it can normalize the weight into the range of (0, 1) and add nonlinearity as an activation function, and more importantly, the global feature based attention scheme do not need the competition between different parts of image information but other nonlinearity function like \(softmax(\cdot )\) will compete between each other. Therefore, the input of our model can be written as
where \(v_t\) is the result of global feature based attention scheme worked in multimodal space.
3.4 Our Full Model
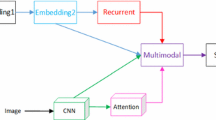
Because our attention scheme is based on the image feature, we do not need other information. We can append our attention scheme to the initial model directly. And we can train the attention scheme with our original model as an end to end system.
Therefore, at each time step, the image feature will be input into the attention scheme first, then the output will instead the original image feature. So we do not need change the structure of the initial model.

Our neural image caption model with global feature based attention scheme.
4 Results
4.1 Implementation Details
Encoder-CNN. We use the 16-layer version of VGG-Net as the encoder-CNN, specifically, the second fully connected layer outputs are used as the representation of images, which is a 4096-dimension vector. Besides, we add a ReLU function to remove the negative outputs. In our training stage, we fix the convolutional layers and fine-tune the full connected layers on the ISLVRC16 dataset for 10 epochs (Fig. 4).
Decoder-RNN. We concatenate the word embedding vector and image feature to get the input in multimodal space. Our decoder-RNN only has one hidden layer with the size of 256. And in order to make our model be a nonlinear system, we add ReLU function after the hidden layer, which can also avoid the vanishing gradient problem. Besides, we use dropout to avoid over-fitting problem, the dropout ratio is set to 0.4 in our model.
Training. We set the learning rate to 0.001 and decayed by 0.1 after every 50 epochs. Because every image has several descriptions in the dataset, we extract the image with only one description for each sample. We use the Stochastic Gradient Descent algorithm to train our model and the batch size is 128.
Evaluation. Because the target output of our image caption model is the same as the machine translation problem. We use the same evaluation criteria to evaluate our model and we choose the BLEU algorithm and METEOR.
4.2 Quantitative Analysis
We test our model on Flickr8k dataset and Flickr30k dataset, and we contrast our model with some classic models. Our original model is based on RNNs, which is proved to have poor performance than LSTM used in NIC. But our GFA shows the same improvement performance compared with classic models. Our GFA improves the BLEU-n score and METEOR score by 5.0/4.8/4.8/3.9/0.017 in Flickr8k and 1.6/0.9/0.8/0.5/0.012 in Flickr30k, compared with hard-attention, which improves the score by 4/4.7/4.4/-/0.015 in Flickr8k and 0.6/1.6/1.9/1.6/0.003 in Flickr30k, and soft-attention, which improves the score by 4/3.8/2.9/-/0.001 in Flickr8k and 0.4/1.1/1.1/0.8/0.002 in Flickr30k.
Since our GFA is based on the global feature and we know the weights and biases of full connected layers in CNNs. Then we can derive the equation to get the weights of the different parts of the last convolutional neural networks. In the derivation procedure, we use least-square method to solve the over-determined system of equations, and we ignore the influence of ReLU function attached to the second full connected layer. Finally, we use Polynomial Interpolation Algorithm to recover the weighs of different parts of original image. Because in the procedure of derivation, we ignore the affection of the nonlinearity function, the derivation result is just the inference of the alignment between the word and the image. Even so, the result shows our global feature based attention scheme can achieve aligning the word with relevant regions (Tables 1 and 2) (Fig. 5).

The alignment result between regions and words.
5 Conclusion
We propose a neural image caption extractor with a new attention scheme. Our global feature based attention scheme is based on the features of the full image rather than regions and we use a simpler structure. And we achieve the same improvement result compared with other attention scheme.
References
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. In: Computer Science (2014)
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Computer Science (2014)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2005, pp. 886–893 (2005)
Donahue, J., Hendricks, L.A., Rohrbach, M., Venugopalan, S., Guadarrama, S., Saenko, K., Darrell, T.: Long-term recurrent convolutional networks for visual recognition and description. Elsevier (2015)
Farhadi, A., Hejrati, M., Sadeghi, M.A., Young, P., Rashtchian, C., Hockenmaier, J., Forsyth, D.: Every picture tells a story: generating sentences from images. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010. LNCS, vol. 6314, pp. 15–29. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-15561-1_2
Girshick, R.: Fast R-CNN. In: Computer Science (2015)
Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 580–587 (2014)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Karpathy, A., Feifei, L.: Deep visual-semantic alignments for generating image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 39(4), 664–676 (2017)
Karpathy, A., Joulin, A., Li, F.-F.: Deep fragment embeddings for bidirectional image sentence mapping, vol. 3, pp. 1889–1897 (2014)
Kiros, R., Salakhutdinov, R., Zemel, R.: Multimodal neural language models. In: International Conference on International Conference on Machine Learning, pp. II-595 (2014)
Kulkarni, G., Premraj, V., Dhar, S., Li, S.: Baby talk: understanding and generating simple image descriptions. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1601–1608 (2011)
Kuznetsova, P., Ordonez, V., Berg, A.C., Berg, T.L., Choi, Y.: Collective generation of natural image descriptions. In: Meeting of the Association for Computational Linguistics: Long Papers, pp. 359–368 (2012)
Kuznetsova, P., Ordonez, V., Berg, T.L., Choi, Y.: TREETALK Composition and compression of trees for image descriptions. TACL 2, 351–362 (2014)
Li, S., Kulkarni, G., Berg, T.L., Berg, A.C., Choi, Y.: Composing simple image descriptions using web-scale n-grams. In: Fifteenth Conference on Computational Natural Language Learning, pp. 220–228 (2011)
Lowe, D.G.: Object recognition from local scale-invariant features. In: The Proceedings of the Seventh IEEE International Conference on Computer Vision, p. 1150 (2002)
Mao, J., Xu, W., Yang, Y., Wang, J., Huang, Z., Yuille, A.: Deep captioning with multimodal recurrent neural networks (m-rnn), Eprint Arxiv (2014)
Mikolov, T., Karafiát, M., Burget, L., Cernocký, J., Khudanpur, S.: Recurrent neural network based language model. In: INTERSPEECH 2010, Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September, pp. 1045–1048 (2010)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Computer Science (2014)
Smirnov, E.A., Timoshenko, D.M., Andrianov, S.N.: Comparison of regularization methods for imagenet classification with deep convolutional neural networks. Aasri Proc. 6(1), 89–94 (2014)
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. 4, 3104–3112 (2014)
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Computer Vision and Pattern Recognition, pp. 1–9 (2015)
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: a neural image caption generator. In: Computer Vision and Pattern Recognition, pp. 3156–3164 (2015)
Wu, Q., Shen, C., Liu, L., Dick, A., Van Den Hengel, A.: What value do explicit high level concepts have in vision to language problems? In: Computer Vision and Pattern Recognition, pp. 203–212 (2016)
Yonghui, W., Schuster, M., Chen, Z., Le, Q.V., Norouzi, M., Macherey, W., Krikun, M., Cao, Y., Gao, Q., Macherey, K.: Bridging the gap between human and machine translation. In: Google’s Neural Machine Translation System (2016)
Kelvin, X., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, R., Bengio, Y.: Show, attend and tell: neural image caption generation with visual attention. In: Computer Science, pp. 2048–2057 (2015)
Yang, Z., Yuan, Y., Wu, Y., Salakhutdinov, R., Cohen, W.W.: Encode, review, and decode: reviewer module for caption generation (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Wang, Y., Xiong, H. (2017). Neural Image Caption Generation with Global Feature Based Attention Scheme. In: Zhao, Y., Kong, X., Taubman, D. (eds) Image and Graphics. ICIG 2017. Lecture Notes in Computer Science(), vol 10667. Springer, Cham. https://doi.org/10.1007/978-3-319-71589-6_5
Download citation
DOI: https://doi.org/10.1007/978-3-319-71589-6_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-71588-9
Online ISBN: 978-3-319-71589-6
eBook Packages: Computer ScienceComputer Science (R0)
