
Abstract
Privacy-preserving is a challenging problem in real-world data classification. Among the existing classification methods, the support vector machine (SVM) is a popular approach which has a high generalization ability. However, when datasets are privacy and complexity, the processing capacity of SVM is not satisfactory. In this paper, we propose a new method CI-SVM to achieve efficient privacy-preserving of the SVM. On the premise of ensuring the accuracy of classification, we condense the original dataset by a new method, which transforms the privacy information to condensed information with little additional calculation. The condensed information carries the class characteristics of the original information and doesn’t expose the detailed original data. The time-consuming of classification is greatly reduced because of the fewer samples as condensed information. Our experiment results on datasets show that the proposed CI-SVM algorithm has obvious advantages in classification efficiency.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Classification is an important method used to analyze mass data in data mining so that better data prediction can be realized [1, 2]. Nevertheless, this case causes to anxiety about privacy and secure considerations. Most classification algorithms rely on the learning of the original training samples, which is easy to expose the training data and lead to the leakage of privacy information, especially for hospital diagnosis results and financial information [3]. However, when we try to protect the original data, the accuracy and time-consuming of classification may be affected. Therefore, it is the main task to maintain a good trade-off between privacy-preserving and classification effective.
Support vector machine (SVM) is widely used as a reliable classification algorithm for high dimensional and nonlinear data [4]. In recent years, many researches have been made in privacy-preserving SVM classification. Nevertheless, if the training dataset is large in the realization, the learning speed of SVM will be very slow. Meanwhile, as a single SVM can only be used for two-class classification, researches often combine multiple SVMs to achieve multi-class classification, such as LIBSVM [5], which may lead to excessive numbers of iterations and much more time-consuming in learning stage.
In order to preserve privacy dataset and improve the classification efficiency of SVM, researchers proposed some methods to compress the original dataset, so that privacy information may be hidden and the reduced dataset may save the time-consuming of classification. Literature [6] applied a global random reduced kernel composed by local reduced kernels to generate a fast privacy-preserving algorithm. Literature [7] proposed the use of edge detection technology to extract the potential support vectors and remove the samples from the classification boundaries, so as to reduce the training samples to improve the training speed. Literature [8] used RSVM (The reduced SVM) [9] to save time in the data classification stage. Unfortunately, most of the existing schemes are at the expense of cutting the dataset, which may inevitably lead to the loss of original information. Nowadays, researchers put forward the method of clustering the data before classification, the condensed information can be used to hide the original data and improve the classification speed. Literature [10] used the fuzzy clustering method (FCM) to reduce and compress the training data, the clustering centers were applied to the SVM in the training phase. However, in fact, the purpose of us is to realize the compression of the original information but not find the global optimal clustering centers, the iterative process for finding cluster centers in FCM is superfluous under the circumstances, which may lead to unnecessary time-consuming.
In this paper, we focus on the privacy-preserving of SVM and design a scheme for training the SVM from the condensed information by clustering. Unlike traditional methods, condensed information SVM (CI-SVM) refers breadth-first search (BFS) algorithm to access all nodes and generate similarity matrix, then the process of global clustering is based on the similarity between samples. CI-SVM enables the data owner to provide condensed data with fuzzy attributes to the public SVM without revealing the actual information since the public SVM may be untrustworthy. On the other hand, as the determination of attribute weights indirectly affects the clustering results, some researchers have taken into account its impact on the clustering results [11]. In this paper we introduce the weighted clustering based on dispersion degree into the similarity matrix, which aim is to ensure more realistic clustering centers. In addition to the condensed data itself, the amount of data can be reduced obviously compared with the original data, which means the classification speed may be greatly improved.
The rest of this paper is organized as follows: In Sect. 2, we review SVM and FCM-SVM proposed by the previous researchers, discuss the reason for improvement. Section 3 introduces our CI-SVM privacy preserving classifier, which achieves SVM classification from clustering data to protect original information. Then in Sect. 4, we list the experimental results and make a brief analysis. Finally, we conclude the paper in Sect. 5.
2 Related Work
2.1 Support Vector Machines
The SVM is based on the theory of structural risk minimization and performs well on training data [12]. Usually a SVM classifier should be given an input pair \( (x_{i} ,y_{i} ) \) with \( p \) features in \( i{\text{-th}} \) data point and \( y \in ( + 1, - 1) \) is the corresponding class label. We often use a soft constraint \( y_{i} ({\varvec{\upomega}} \cdot x_{i} + b) \ge 1 - \xi_{i} \) to handle nonlinear separable data, \( {\varvec{\upomega}} \) is the weight vector of the linear SVM and \( b \) is the bias value. Therefore, the following primal objective should be minimized:
Where \( C > 0 \) is the regularization parameter, we usually solve the following dual problem:
Where \( Q_{ij} \) is decided by \( k \) positive semi-definite matrix, \( Q_{ij} = y_{i} y_{j} K(x_{i} ,y_{i} ) \) is the kernel function and \( K(x_{i} ,y_{i} ) \equiv \phi (x_{i} )^{T} \phi (y_{i} ) \), the decision function is
We utilize LIBSVM to handle multi-class datasets and the strategy of classification is one-versus-one [5]. It designs a SVM classifier between any two samples, which means \( k\text{-class} \) samples need to design \( k(k - 1)/2 \) classifiers. For training data from \( i{\text{-th}} \) and \( j{\text{-th}} \) class:
Each classifier obtains the corresponding classification results. There is a voting strategy in multi-class classification: each classification result is regarded as a voting where votes can be accumulated for all samples. In the end a sample is designated to be in a class with the maximum number of votes.
2.2 Review of FCM-SVM
In recent years, an effective method to speed up the training of SVM is clustering the original data before classification to release the initial data size [13,14,15]. Researchers usually use the FCM to condense information so that the meaning of original data can be reserved. FCM is a kind of fuzzy iterative self-organizing data analysis algorithm (ISODATA). It divides the dataset \( x_{i} (i = 1,2, \ldots ,n) \) into \( c \) fuzzy classes, where each cluster center should be calculated. It transforms the aim clustering to minimize the non-similarity index of the value function. Different with the hard clustering, FCM allows each data point to belong to all clustering centers and uses \( u_{ij} = (0,1) \) to measure the attribution degree, where \( \sum\limits_{i = 1}^{M} {u_{ij} = 1,(j = 1,2, \ldots ,n)} \), \( M \) is the number of clustering centers. The objective function of FCM is defined as follows:
Where \( q \in [1, + \infty ) \) is the weighted index, \( d_{ij} = \left\| {c_{m} - x_{j} } \right\| \) is the Euclidean distance between the clustering center \( c_{m} \) and data point \( x_{j} \). Then update as follows:
In FCM-SVM, FCM is the iterative process to find the optimal clustering centers, then the generated clustering centers will be used as the reduced dataset to train the SVM. The time complexity of FCM is \( O(n^{3} p) \). However, what we only need is the condensed information to classify in the SVM, the traditional clustering methods like FCM have too many unnecessary iterations in the process of finding clustering centers, which means the time-consuming of clustering is too much and unnecessary.
3 Secure SVM with Condensed Information
In this section, we design a data security solution CI-SVM which makes SVM known to the public. To overcome the security weakness of SVM and the overlong time-consuming of classification, we design a condensed information scheme and use the clustering centers to replace the essential information between samples, so that public SVM can only obtain the condensed data clustered by the undirected weighted graph.
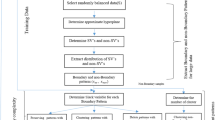
Figure 1 shows the proposed CI-SVM for privacy-preserving. The left-hand expresses the process of data owner training and testing data. The data owner clusters data through our clustering method and sends the condensed information to the public SVM. The right-hand is the CI-SVM in public, it derives the condensed data to classify, then returns classification information of samples to the data owner.

CI-SVM privacy-preserving scheme.
3.1 Feature Weight Calculation
In a dataset, the data resources may contain many data features with different attributes, some of the features may cause high contribution rate to the clustering results that named high separable features. In contrast, others’ contribution rate to the clustering results is very little, which are named isolated features or noise features. If we ignore the impact of them, the clustering accuracy may be difficult to improve, which is doomed to low classification accuracy in SVM. To overcome the robustness of the traditional algorithm and reduce the effect of noise data on the clustering results, we adopt variation coefficient weighting method to determine the contribution of each feature, which may increase the weights of high separable features so that the accuracy of clustering may be improved.
Set a set of data \( X = \{ x_{1} ,x_{2} , \ldots ,x_{n} \} \), the variation coefficient \( v_{x} \) is calculated as follows:
Where \( \overline{X} = \frac{1}{n}\sum\limits_{i = 1}^{n} {X_{i} } , \, i = (1,2, \ldots ,n) \) is described as the mean of data, \( S_{x} = \sqrt {\frac{1}{n - 1}\sum\limits_{i = 1}^{n} {(X_{i} - \overline{X} )^{2} } } \) is the standard deviation. \( v_{x} \) represents the dispersion degree of the feature, which is named variation coefficient here. Accordingly, each feature’s contribution rate is calculated as follows:
\( p \) represents the number of features. Different data sets have different feature dimensions \( p \), we use \( w_{k} \) as the symbol for the weight of the \( k{\text{-th}} \) feature, where \( k = (1,2, \ldots ,p) \).
3.2 Proposed Condensed Information Algorithm
Generally, the clustering method is used to concentrate the information of samples, and the sample points generated by clustering are used instead of the essential information. In order to overcome the large time-consuming caused by the excessive number of iterations in traditional clustering algorithms, we propose a fast clustering method to protect the privacy information. The main idea of the algorithm is to treat all the sample data as the nodes in the weighted network. The similarity matrix is generated to represent the similarity between them, which is used to distinguish classifications until all nodes are marked to their respective classification.
Specific algorithm steps are as follows:
-
(1)
Calculate the weights \( S_{ij} \) between any two nodes in the weighted network. Taking into account all attribute features, the similarity between the object \( x_{i} \) and \( y_{i} \) should be calculated as follows:
$$ s_{ij} = \frac{{\sum\limits_{k = 1}^{p} {(x_{ik} w_{k} )(x_{jk} w_{k} )} }}{{\sqrt {\sum\limits_{k = 1}^{p} {(x_{ik} w_{k} )^{2} } } \sqrt {\sum\limits_{k = 1}^{p} {(x_{jk} w_{k} )^{2} } } }} $$(9)
Where \( x_{ik} \) and \( x_{jk} \) respectively denotes the attributes of the feature k in node \( x_{i} \) and \( x_{j} \).
-
(2)
Establishing the undirected weighted graph means setting up the sample similarity matrix. It can be known from formula (9) that \( S_{ij} = S_{ji} \), \( S_{ii} = 1 \). So the similarity matrix is symmetric about the main diagonal. In the algorithm, we only preserve the lower triangular matrix:
$$ S_{n \times n} = \left( {\begin{array}{*{20}r} \hfill 1 & \hfill 0 & \hfill \ldots & \hfill 0 \\ \hfill {S_{21} } & \hfill 1 & \hfill \ldots & \hfill 0 \\ \hfill \vdots & \hfill \vdots & \hfill \ddots & \hfill \vdots \\ \hfill {S_{n1} } & \hfill {S_{n2} } & \hfill \ldots & \hfill 1 \\ \end{array} } \right) $$(10) -
(3)
Searching the maximum similarity value in the similarity matrix \( S_{ab} \), then the nodes \( x_{a}^{1} \) and \( x_{b}^{1} \) are classified into the first classification \( b_{1} \), Continue searching for all connection nodes of \( x_{a}^{1} \) and \( x_{b}^{1} \) to find the node \( x_{c}^{1} \) as the following formula:
$$ \overline{{S_{c} }} = MAX\left( {\frac{{S_{ac} + S_{bc} }}{2}} \right) $$(11)
Then the node \( x_{c}^{1} \) will be classified into the first classification as \( b_{1} = \{ x_{a}^{1} ,x_{b}^{1} ,x_{c}^{1} \} \). \( x_{a}^{1} \), \( x_{b}^{1} \) and \( x_{c}^{1} \) should be marked as visited node, which means they will not be accessed for the next iteration.
-
(4)
Repetitive executing the step (3) until all nodes are marked to their respective classification. Data \( X = \{ x_{1} ,x_{2} , \ldots ,x_{n} \} \) will be divided into \( M \) classes as Y, where \( m = (1,2, \ldots ,M) \):
$$ Y = [b_{1} = \{ x_{a}^{1} ,x_{b}^{1} ,x_{c}^{1} \} , \ldots ,b_{m} = \{ x_{a}^{m} ,x_{b}^{m} ,x_{c}^{m} \} \ldots ,b_{M} = \{ x_{a}^{M} ,x_{b}^{M} ,x_{c}^{M} \} ] $$(12)
Then calculate the cluster center of each class as \( \overline{{b_{m} }} \):
That is to say, \( \overline{{b_{m} }} \) is the condensed information of each three simples. The schematic diagram of the condensed information is shown in Fig. 2.

The result of the condensed information.
It can be seen from Fig. 2(a) that before concentrating on the original information of training samples, attackers can get the training samples and the location of the related field information easily in the learning process. Moreover, they can also get the related support vectors at the end of the training, which makes it easy to cause the leakage of privacy information. Figure 2(b) shows that the original training samples are replaced by the clustering centers. As we all know, the decision function of SVM in the process of classification is generated by the support vector expansion, and the generation of support vector depends on the learning process of the original data. According to the classification criteria of SVM, the learning process is completely visible, so the information of the support vector and some data is exposed. The support vector is different from other data, which contains important information of the sample, so it is easy to cause the leakage of important information. In our scheme we only need to use the new samples made up by clustering centers to train, so that the real support vectors can be hidden to avoid the exposing of privacy information. At the same time, the clustering process of this paper can not completely hide the statistical distribution of datasets, but most of the condensed information produced is not coincident with the original information, to some extent, the distribution of the original data can be hidden.
There is a rule to decide the labels of the clustering centers: Setting \( L_{m} \) as the label of the \( m{\text{-th}} \) condensed data \( \overline{{b_{m} }} \), \( Lx_{i}^{m} \, i = a,b,c \) representatives the label of the original sample in the \( m{\text{-th}} \) class. In most cases, the label of \( \overline{{b_{m} }} \) is decided by the highest frequency label in \( b_{m} \): \( Lb_{m} = \hbox{max} \,num(Lx_{i}^{m} ) \). If \( Lx_{i}^{m} \) is different from each other in \( b_{m} \), which means \( Lx_{a}^{m} \ne Lx_{b}^{m} \ne Lx_{c}^{m} \). Then \( Lb_{m} \) will be decided by the label of nearest simple with the clustering center \( \overline{{b_{m} }} \): selecting \( x_{i}^{m} \) that satisfied \( \hbox{min} \left\| {x_{i}^{m} \, - \,\overline{{b_{m} }} } \right\| \), then \( Lb_{m} = Lx_{i}^{m} \).
The time complexity of the condensed information algorithm is calculated as follows: (1) Computing the weights of \( p \) features in \( n \) samples, which cost \( O(np) \); (2) Calculating the similarity \( S_{ij} \) between any two nodes in the weighted network, which cost \( O(n^{2} p) \); (3) Searching the maximum similarity value in the similarity matrix \( S_{ab} \), which cost \( O(n^{2} ) \). Accordingly, the total computation cost is \( O(np + n^{2} p + n^{2} ) \approx O(n^{2} p) \).
4 Experiments and Results Analysis
4.1 Experimental Conditions
In this section, we compare the accuracy and time-consuming of our algorithm with several previous privacy-preserving classification algorithms and normal classification algorithms. The experience datasets we choose are from LIBSVM websites and UCI data base, which are real world data. Some of them are diagnosis result, financial data and population statistics that contain sensitive information and need to be protected. Given the fact that our method can also achieve multi-class classification, the datasets we choose contains both of them. All of our experiments are conducted on Matlab R2016b and Windows7 with Intel Core i5-6500 CPU at 2.1 GHz, 4 GB RAM. The basic information of the experimental data is shown in Table 1:
4.2 Accuracy and Time-Consuming
In this part, we calculate the weights of features in several datasets. In order to verify the classification accuracy of CI-SVM, we compare it with the LIBSVM in literature [5], FCM-SVM in literature [10], and RSVM in literature [9]. FCM-SVM is a classification algorithm which can improve classification speed. RSVM is a privacy-preserving method with random linear transformation, it uses randomly generated vectors to reduce the training data quantity. All of the four classification algorithms apply the RBF kernel function. The parameter \( C \) and \( g \) are separately optimized by grid search, the search range is \( C = \{ 2^{ - 5} ,2^{ - 3} , \ldots ,2^{11} ,2^{13} \} \) and \( g = \{ 2^{ - 15} ,2^{ - 13} , \ldots ,2^{1} ,2^{3} \} \). In each experiment we randomly select 80% as the training sample, to reduce the impact of randomness, we use 300 times fivefold cross-validation.
Figures 3 and 4 respectively shows the classification performance of two-class and multi-class. RSVM is almost not used in multi-class datasets because the accuracy is usually unsatisfactory. We can see that for two-class classification, the CI-SVM is consistent with the RSVM in accuracy, and the accuracy is greatly improved compared with LIBSVM and FCM-SVM both in two-class and multi-class classification. However, for muti-class classification, the accuracy of CI-SVM is basically flat with LIBSVM and FCM-LIBSVM, even slightly lower than the latter two. It is because that the class of condensed information depends on the highest frequency class of samples in the collection. Therefore, for two-class datasets, it is easy to figure out the label of condensed information, so the exact clustering in advance can improve the classification accuracy to some extent. But for multi-class datasets, if the frequency of each class is equal in a collection, the label is decided on the class of the sample nearest to clustering center, which may causes inevitable clustering error and affects the accurancy of classification.

Comparison of cross-validation accuracy in SVMs for two-class datasets.

Comparison of cross-validation accuracy in SVMs for multi-class datasets.
In this paper, we measure the training time of the 4 algorithms in the above two-class and multi-class datasets, the aim is to display how much time-consuming can be saved by CI-SVM. The training time contains average parameter research process and the training time of classifier by the selected parameter. Literature [10] used FCM algorithm in the process of clustering. Tables 2 and 3 separately show the time-consuming in training SVMs and clustering.
In view of RSVM is a different implementation of the SVM compared with the others, it is just as a reference and we don’t try to compare the training time with it. It can be seen from the above tables that: no matter for two-class or multi-class datasets, the time-consuming of CI-SVM is generally less than the other two methods, especially to low dimensional datasets. Compared with LIBSVM, it is because the number of condensed samples obtained by the new clustering algorithm is reduced to 33%, so the number of support vectors is greatly reduced. As the time-consuming of SVM classification process is directly proportional to the number of support vectors, the time complexity may reach \( O(Nsv^{3} ) \) in the worst case (\( Nsv \) is the number of support vectors), so the classification efficiency of CI-SVM is much better than LIBSVM. As for FCM-SVM, when it has the same clustering centers with CI-SVM, the time-consuming of classification between them is almost flat. However, in clustering phase, the time complexity of FCM is \( O(n^{3} p) \), while it is \( O(n^{2} p) \) in CI-SVM. The time-consuming of clustering is shown in Table 3, it confirms the high efficiency of our algorithm in the clustering process. In summary, the clustering efficiency of our scheme is significantly higher than the existing methods.
5 Conclusion
In this paper, we propose a classification scheme CI-SVM for privacy preserving by designing a new clustering method before entering into SVM classifier, which can be applied to both the two-class and multi-class datasets. It avoids excessive iterations caused by traditional clustering method and the dataset are reduced while the similarity relationship of original dataset can also be retained. To evaluate and verify the significance of this paper, we conducted experiments and applied the datasets from LIBSVM websites and UCI data base. Moreover, we also carried out a comparative study with LIBSVM and FCM-SVM to display the superiority of the CI-SVM.
The compare of time complexity and experiment results indicate that the time-consuming can be greatly saved while the classification accuracy is guaranteed. What’s more, the stage of clustering incurs little computation time compared with other clustering methods, which means the extra calculation imposed on data proprietor can also be executed fast.
References
Gu, B., Sheng, V.S., Tay, K.Y., et al.: Incremental support vector learning for ordinal regression. IEEE Trans. Neural Netw. Learn. Syst. 26(7), 1403–1416 (2015)
Paul, S., Magdon-Ismail, M., Drineas, P.: Feature selection for linear SVM with provable guarantees. Pattern Recogn. 60, 205–214 (2016)
Kokkinos, Y., Margaritis, K.G.: A distributed privacy-preserving regularization network committee machine of isolated Peer classifiers for P2P data mining. Artif. Intell. Rev. 42(3), 385–402 (2014)
Chen, W.J., Shao, Y.H., Hong, N.: Laplacian smooth twin support vector machine for semi-supervised classification. Int. J. Mach. Learn. Cybernet. 5(3), 459–468 (2014)
Chang, C.C., Lin, C.J.: LIBSVM: a library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2(3), 27 (2011)
Sun, L., Mu, W.S., Qi, B., et al.: A new privacy-preserving proximal support vector machine for classification of vertically partitioned data. Int. J. Mach. Learn. Cybernet. 6(1), 109–118 (2015)
Li, B., Wang, Q., Hu, J.: Fast SVM training using edge detection on very large datasets. IEEJ Trans. Electr. Electron. Eng. 8(3), 229–237 (2013)
Zhang, Y., Wang, W.J.: An SVM accelerated training approach based on granular distribution. J. Nanjing Univ. (Nat. Sci.), 49(5), 644–649 (2013). (in Chinese). [张宇, 王文剑, 郭虎升. 基于粒分布的支持向量机加速训练方法[J]. 南京大学学报: 自然科学版, 2013, 49(5): 644-649]
Lin, K.P., Chang, Y.W., Chen, M.S.: Secure support vector machines outsourcing with random linear transformation. Knowl. Inf. Syst. 44(1), 147–176 (2015)
Almasi, O.N., Rouhani, M.: Fast and de-noise support vector machine training method based on fuzzy clustering method for large real world datasets. Turk. J. Electr. Eng. Comput. Sci. 24(1), 219–233 (2016)
Peker, M.: A decision support system to improve medical diagnosis using a combination of k-medoids clustering based attribute weighting and SVM. J. Med. Syst. 40(5), 1–16 (2016)
Aydogdu, M., Firat, M.: Estimation of failure rate in water distribution network using fuzzy clustering and LS-SVM methods. Water Resour. Manage. 29(5), 1575–1590 (2015)
Shao, P., Shi, W., He, P., et al.: Novel approach to unsupervised change detection based on a robust semi-supervised FCM clustering algorithm. Remote Sens. 8(3), 264 (2016)
Kisi, O.: Streamflow forecasting and estimation using least square support vector regression and adaptive neuro-fuzzy embedded fuzzy c-means clustering. Water Resour. Manage. 29(14), 5109–5127 (2015)
Wang, Z., Zhao, N., Wang, W., et al.: A fault diagnosis approach for gas turbine exhaust gas temperature based on fuzzy c-means clustering and support vector machine. Math. Probl. Eng. 2015, 1–11 (2015)
Acknowledgment
This work was supported by the Fundamental Research Funds for the Central Universities (JUSRP51510).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Li, X., Zhou, Z. (2017). An Efficient Privacy-Preserving Classification Method with Condensed Information. In: Zhao, Y., Kong, X., Taubman, D. (eds) Image and Graphics. ICIG 2017. Lecture Notes in Computer Science(), vol 10668. Springer, Cham. https://doi.org/10.1007/978-3-319-71598-8_49
Download citation
DOI: https://doi.org/10.1007/978-3-319-71598-8_49
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-71597-1
Online ISBN: 978-3-319-71598-8
eBook Packages: Computer ScienceComputer Science (R0)
