
Abstract
Deep learning can explore robust and powerful feature representations from data and has gained significant attention in visual tracking tasks. However, due to its high computational complexity and time-consuming training process, the most existing deep learning based trackers require an offline pre-training process on a large scale dataset, and have low tracking speeds. Therefore, aiming at these difficulties of the deep learning based trackers, we propose an online deep learning tracker based on Sparse Auto-Encoders (SAE) and Rectifier Linear Unit (ReLU). Combined ReLU with SAE, the deep neural networks (DNNs) obtain the sparsity similar to the DNNs with offline pre-training. The inherent sparsity make the deep model get rid of the complex pre-training process and can be used for online-only tracking well. Meanwhile, the technique of data augmentation is employed in the single positive sample to balance the quantities of positive and negative samples, which improve the stability of the model to some extent. Finally, in order to overcome the problem of randomness and drift of particle filter, we adopt a local dense sampling searching method to generate a local confidence map to locate the target’s position. Moreover, several corresponding update strategies are proposed to improve the robustness of the proposed tracker. Extensive experimental results show the effectiveness and robustness of the proposed tracker in challenging environment against state-of-the-art methods. Not only the proposed tracker leaves out the complicated and time-consuming pre-training process efficiently, but achieves an online fast and robust tracking.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Visual tracking
- Online fast tracking
- Deep sparse neural networks
- Rectifier Linear Unit (ReLU)
- Local confidence maps
1 Introduction
Visual tracking technology is one of the hot research directions in computer vision field, which is widely used in military and civil fields [1, 2].
In recent years, a large number of tracking algorithms have been proposed. Existing tracking algorithms can be divided into two categories [3]: generative methods and discriminative methods. The generative methods, e.g., IVT [4] (incremental visual tracking), L1T [5] (the l 1 tracker), and MTT [6] (multitask tracking), establish the appearance model of the target, and then search the most similar candidate samples as current tracking result. The discriminative methods treat the tracking problem as a binary classification of the target and background. Some popular discriminative trackers include MIL [7] (multiple instance learning), TLD [8] (tracking-learning-detection), and Struck [9]. Although the above trackers have achieved good results under simple controlled conditions, these trackers based on hand-crafted features are still facing enormous challenges in complex environments, e.g., illumination variation, severe occlusion, and background clutters.
Due to Deep Neural Networks (DNNs) [10] can exploit robust and powerful feature representations automatically using its deep structure, the deep learning based tracking algorithms have gained significant attention in visual tracking tasks. Combined offline pre-training with online fine-tuning, Wang and Yeung [11] first applied the stacked denoising auto-encoders (SDAE) architecture to the visual tracking tasks, and achieved a robust tracking performance in some complicated scenarios. Li et al. [12] applied a single-CNN (Convolutional Neural Network) on visual tracking, and combined with multiple image cues to improve the tracking success rate. In [13], Zhang et al. propose a CNT tracker, which take the advantage of local structure feature and global geometric information to improve the tracking performance. Ma et al. [14] utilized hierarchical features with CNNs and gained a state-of-the-art result in complicated tracking situations. With the fast development of deep learning, the trackers based on deep learning outperform the traditional tracking algorithms significantly in tracking success rate and accuracy.
However, there are still several difficulties of the deep learning based trackers that are desired to be solved. (i) A complex and time-consuming offline pre-training process is indispensable to most existing deep learning based trackers. The offline pre-training process requires an auxiliary large scale dataset and the learned generic representations from the auxiliary dataset may not be suitable to track a specific object. (ii) The traditional nonlinear activation functions like sigmoid or tanh have complex mathematical expressions. It results in high computational complexity in error back propagation (BP) during the training of deep networks and will reduce the tracking speed. (iii) The trackers like DLT or CNT use the particle filter to obtain the candidate samples. The bad particles will affect the tracking performance and easily cause the tracking drift. Meanwhile, the randomness of the particles will result in the inconsistency of the tracking results in the repeat experimentations.
In this work, we propose an online fast deep learning tracker to solve the above problems. The main contributions of our works can be summarized as follows:
-
(1)
We adopt Rectifier Linear Unit (ReLU) as the activation function of Sparse Auto-Encoders (SAE) and build a simple yet effective Deep Sparse Neural Network (DSNN) for tracking. The ReLU and sparsity constraint make DSNN highly sparse and get rid of the complex pre-training process. It makes the proposed tracker achieve an online-only training and tracking. Meanwhile, the simple mathematical expression reduces the computational complexity in training and improves the tracking speed.
-
(2)
In order to overcome the problem of randomness and drift of particle filter, we adopt a local dense sampling searching method to generate a local confidence map. By searching the maximum confidence value, the current position of target is located accurately. In addition, in order to balance the quantities of positive and negative samples, a technique of data augmentation is employed for the single positive sample.
-
(3)
We present an online adaptive model update strategy aiming at the long-term tracking tasks. By establishing a sliding time window and adaptively adjusting the local searching area, the update strategy improves the robustness of the proposed tracker in challenging environment.
Extensive experimental results on OTB2013 [15] show that the proposed tracker is effective and efficient in challenging environment against state-of-the-art methods. Not only the proposed tracker leaves out the complicated and time-consuming pre-training process efficiently, but achieves an online fast and robust tracking.
2 Deep Sparse Neural Network for Tracking
The sparsity of neural networks means that the features of the input layer are represented by the least hidden neurons. It is actually to look for a set of “overcomplete” basis vectors to represent the data efficiently and has better sparsity and expressiveness.
2.1 Sparse Auto-Encoders with ReLU
Sparse Auto-Encoder (SAE) [16] is an unsupervised learning model, which is one basic algorithm in deep learning. By using the “Layer-by-Layer Greedy Algorithm” to stack multiple SAEs, we obtain a deep sparse networks. Figure 1(a) shows the basic structure of stacked-SAEs. Let \( \hat{x}_{i} \) denote the reconstruction of the input data \( x_{i} \), \( \varvec{W} \) and \( \varvec{W}^{{\prime }} \) denote the weight matrix of encoder and decoder respectively, and \( \varvec{b} \) denote the bias vector of encoder. In our work, the loss function of the stacked-SAEs is defined as:
where m is the number of samples, \( \lambda \) is a penalty factor which balances the reconstruction loss and weights, \( \mu \) is the sparsity penalty factor, and \( \left\| \cdot \right\|_{F} \) denotes the Frobenius norm. The cross-entropy \( H\left( {\left. \rho \right|\left| {\hat{\varvec{\rho }}} \right.} \right) \) is given as:
where k and n are the number of neurons in input and hidden layer respectively. \( h_{j} \text{(}x_{i} \text{)} \) denotes the activation value in the j th hidden layer to the input \( x_{i} \). The sparsity target \( \varvec{\rho} \) is close to 0, and it is set to 0.05 in our experiments.

The basic stacked-SAEs and its variant with ReLU: (a) basic stacked-SAEs, (b) activation function curves, and (c) the variant of stacked-SAEs with ReLU.
In order to obtain the robust and powerful capacity of extracting features, the offline pre-training on a large scale dataset is usually used in deep networks. The key of pre-training is to obtain the sparse distributed representation of deep networks [17]. Rectifier Linear Unit (ReLU) [18, 19] is a sparse activation function. As shown in Fig. 1(b), the rectifier function ReLU(x) = max(0, x) is a one-side activation function, which enforces hard zeros in the learned feature representation and leads to the sparsity of hidden units. So we adopt ReLU as an activation function to the aforementioned stacked-SAEs to improve the sparsity of the DNN. The variant of stacked-SAEs with ReLU is shown in Fig. 1(c).
It is proven in [19, 20] that ReLU will bring the inherent sparsity to DNNs, which let the pre-training become less effective for DNNs with the activation function of ReLU. So the usage of ReLU as activation function leaves out the offline pre-training process of DNN. It will solve the over-fitting problem in pre-training well. Meanwhile, the unilateral activation side of ReLU is an unsaturated linear function, which effectively solves the problem of gradient vanishing in the training process. Moreover, since the gradient of ReLU is the fixed value of 1 or 0, it isn’t necessary to perform complex gradient calculation in the network training. This reduces the computational complexity and improves the training speed effectively.
2.2 Online Tracking Network
In order to achieve the purpose of tracking, we add a softmax classifier as the last layer to the stacked-SAEs to classify learned features. The logistic regression is included in the softmax classifier:
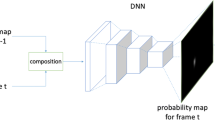
where \({l}_{\theta } (\varvec{x}) \) is a value in [0, 1], i.e. represents the probability of the sample t as the true target; \( \theta \) is the model parameters. The final model of deep sparse neural networks for tracking is shown in Fig. 2.

The model of tracking network. The number in each layer denotes the number of neurons in this layer.
3 Proposed Tracking Algorithm
Based on the aforementioned deep sparse neural networks, we propose an online fast deep learning tracker. In this Section, we will describe our proposed tracking algorithm in detail.
3.1 Initialization of the Tracking Network
Given the initial state \( s_{\text{0}} = \{ x_{\text{0}} ,y_{\text{0}} ,w_{\text{0}} ,h_{\text{0}} \} \) of target, we can obtain a single positive sample patch by sampling at the initial frame, where \( \text{(}x_{\text{0}} ,y_{\text{0}} \text{)} \) denotes the initial position, \( w_{\text{0}} \) and \( h_{\text{0}} \) denote the initial width and height, respectively. Meanwhile, we also obtain 100 negative sample patches by random sampling around \( \text{(}x_{\text{0}} ,y_{\text{0}} \text{)} \). Normalizing all patches, we can get the standard gray-scale images of 32 × 32 pixels as the input data for the tracking network.
Meanwhile, considering the imbalance between positive and negative will affect the robustness of the tracking network, so we need to augment the quantity of positive samples to balance the quantity of positive and negative samples. A method of sampling within 2 pixels near the positive sample to data augmentation was proposed in [11]. However, this method is prone to accumulate the error and affect the tracking results. In [21], new data was created by transforming the images such as scaling, translation, rotation, noising, changing brightness, mirroring and cropping to expand the quantity of samples. We extend the single positive sample in initial frame to 10 samples by changing the brightness, contrast, noise, and smoothing and mirroring. The results are shown in Fig. 3.

Data augmentation for single positive sample.
Using these 10 positive samples and 100 negative samples as the label data, we can get the tracking network parameters corresponding to the specific task by training the tracking network of Fig. 2.
3.2 Local Confidence Maps
During the tracking process, each sample patch can get a value into [0, 1] through the softmax classifier in the tracking network. The value reflects the probability that the sample patch is a positive sample (i.e. the target), and we call it “confidence value” of the sample patch. In our proposed algorithm, we use local dense sampling method to sample all the pixels in the candidate area as the sampling center. Sending all the sample patches to the tracking network, we can get the confidence value of all the pixels in the candidate area. As is shown in Fig. 4, the local confidence map of the candidate area can be obtained by visualizing all the confidence value, which can intuitively reflect the possible position of the target in local area.

Local confidence maps of some videos. The darker the red denote the higher confidence value. (Color figure online)
According to Eq. (5), the sample patch with the highest confidence is determined as the tracking result in current frame.
where \( \varsigma_{i} \) denotes the confidence value of the i th sample patch, \( s_{t} = \{ x_{t} ,y_{t} ,w_{t} ,h_{t} \} \), i.e. the target state in frame t.
In addition, we add a random disturbance \( (w_{r} ,h_{r} ) \) to the size \( (w_{i} ,h_{i} ) \) of the sample patch to accommodate the scale change of the target during tracking. In this paper, both \( w_{r} \) and \( h_{r} \) follow a normal distribution with mean of 0 and variance of 0.1.
3.3 Online Adaptive Model Update
In the long-term tracking, the target is susceptible to the illumination variation, deformation, background clutter and so on, and it is easy to cause tracking drifting. At this time, the tracking network parameters need to be updated. The update criteria of tracking network are as follows:
where \( \tau_{1} \) is the threshold of network update, \( fn \) is the number of cumulative frames after the last update, and \( \eta \) is the maximum of cumulative frames.
The update strategy is to establish a sliding time window of positive samples [22] and put the tracking results of current frame and its adjacent 9 frames into the sliding window, which is shown in Fig. 5. And the positive samples in the sliding window are replaced and updated in real time. When Eq. (6) is satisfied, we resample 100 negative samples in current frame, and take them together with 10 positive samples of the initial frame and 10 positive samples of the sliding time window as the label data to train the tracking network and update the network parameters.

Sliding time window of positive samples.
Meanwhile, the initial local searching area may not detect the correct target when the target is occluded, so the searching area is needed to expand that the target can be tracked correctly. The update criteria of searching area are as follows:
where \( \tau_{\text{2}} \) is the threshold of searching area updating.
The searching area is updated as follows:
where N is the length of square searching area, and the initial N is set to 10 pixels. \( \delta \) is the increment of N.
3.4 Overall Process of Proposed Algorithm
We present the main steps of the proposed tracking algorithm in Table 1. The flow chart as shown in Fig. 6.

Flow chart of the proposed tracking algorithm.
4 Experiments
The proposed tracking algorithm is realized in MATLAB under the experimental platform of CPU (Intel Xeon 2.4 GHz) and GPU (TITAN X). We empirically compare our tracker with some state-of-the-art trackers using the OTB2013 benchmark dataset [15], which includes 51 fully-annotated sequences. These trackers are: SST [23], SCM [24], Struck [9], DLT [11], LLC [25], CN [26], MIL [7], and NRMLC [27]. The results of these trackers are provided by their authors.
The setting of experimental parameters of our tracker are as follows: \( \lambda = \text{0.005} \), \( \mu = \text{0.2} \), \( \eta = \text{50} \), \( \tau_{1} = \text{0.9} \), \( \tau_{2} = \text{0.5} \), \( \delta = \text{5} \). In experiments, we use the OPE evaluate method of and the evaluation indicators mentioned in [15].
4.1 Qualitative Comparison
We use all 51 sequences of OTB2013 in our experiments. Some tracking results of the 9 challenging sequences are shown in Fig. 7. Then we analyse the performance in the following different scenarios:

Qualitative comparison of 9 trackers (denoted in different colors). (Color figure online)
-
(1)
Illumination variation: There are severe illumination changing in “Car4”, “Singer2”, and “Trellis”. Compared with other trackers, the proposed tracker tracks the targets more accurately. And in “Car4”, our tracker can better adapt to the scale changing of target along the whole sequence.
-
(2)
Occlusion and Rotation: The targets are partially or completely occluded in “Suv” and “Tiger2”. Our tracker always tracks the target continuously from beginning to end. In “Fleetface” and “Tiger2”, out-of-plane or in-plane rotation increase the difficulty of tracking, yet our tracker can still provide accurate results relatively.
-
(3)
Fast motion and Motion blur: In “Boy” and “Basketball”, the motion of target is very fast and even causes the motion blur. The proposed tracker has the capacity to track the target more reliably and accurately than others.
-
(4)
Deformation and Background clutter: There are deformation and similar background to target in “Basketball” and “Freeman4”. This is a challenge to the robustness of the features extracted by trackers. From the tracking results, our tracker explores more robust and powerful features to track the correct target stably.
4.2 Quantitative Comparison
For quantitative comparison, the precision plots and success plots of these trackers for all 51 sequences on OTB2013 are given respectively in Fig. 8. Our tracker ranks 1st for both plots and outperforms these state-of-the-art trackers in overall performance. For precision plots, our tracker achieves 0.660 which is higher than DLT (the similar deep learning based tracker) by 12.4%. For success plots, our tracker achieves 0.501 which is improved by 14.9% over DLT tracker.

Precision plots and success plots of 9 trackers on OTB2013.
Tables 2 and 3 show the precision values and success rates of 9 trackers on 11 different attributes, respectively. In both tables, these abbreviations represent different attributes which are defined in [15]: IV-Illumination Variation, SV-Scale Variation, OCC-Occlusion, BC-Background Clutters, DEF-Deformation, MB-Motion Blur, FM-Fast Motion, IPR-In Plane Rotation, OPR-Out of Plane Rotation, OV-Out of View, LR-Low Resolution. The number below the abbreviation represents the quantity of sequences within this attribute in OTB2013. The best results are in red and the second best in green. From Tables 2 and 3, we observe that our tracker ranks the optimal or suboptimal results on 8 attributes. Only on two attributes of BC and LR, our tracker doesn’t rank the top 3. These data show that our tracker has a favorable performance on different challenging environments against the contrast trackers.
4.3 Tracking Speed Comparison
FPS (frames per second) measures the tracking speed and represents the time complexity of the tracker. Table 4 show the tracking speed of 9 trackers. From that, we find that our proposed tracker achieves average 16.5 FPS in our experimental environment. It is faster than DLT and other similar deep learning based trackers like DeepTrack (2.5 FPS) [28].
5 Conclusions
In this paper, we propose a robust and fast visual tracking algorithm based on deep sparse neural networks. Combined ReLU with stacked-SAEs, the deep sparse network avoids the complex and time-consuming pre-training, and realizes online-only training and tracking. Data augmentation of single positive sample relieves the imbalance between positive and negative samples, which improves the reliability of deep networks. Meanwhile, the local dense searching method and adaptive update strategy solve the problem of particle drift and randomness. A lot of experimental results on OTB2013 dataset show that our proposed algorithm achieves state-of-the-art results in complicated environment and realize a practical tracking speed.
However, there are still several possible research directions to improve our algorithm. For example, it is not robust enough for our tracker when the target’s scale changes significantly or the complete occlusion sustains too long time. Therefore, the problem of scale adaptability and long-time occlusion will be the focus of our future work.
References
Smeulders, A.W.M., Chu, D.M., Cucchiara, R., et al.: Visual tracking: an experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 36(7), 1442–1468 (2014)
Yilmaz, A., Javed, O., Shah, M.: Object tracking: a survey. ACM Comput. Surv. 38(4), 1–45 (2006)
Li, X., Hu, W.M., Shen, C.H., et al.: A survey of appearance models in visual object tracking. ACM Trans. Intell. Syst. Technol. 4(4), Article 58 (2013)
Ross, D.A., Lim, J., Lin, R.S.: Incremental learning for robust visual tracking. Int. J. Comput. Vis. 77(1–3), 125–141 (2008)
Mei, X., Ling, H.: Robust visual tracking using l1 minimization. In: IEEE International Conference on Computer Vision, pp. 1436–1443. IEEE, Washington, D.C. (2009)
Zhang, T.Z., Ghanem, B., Liu, S., et al.: Robust visual tracking via multi-task sparse learning. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2042–2049. IEEE, Washington, D.C. (2012)
Babenko, B., Yang, M.H., Belongie, S.: Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 33(8), 1619–1632 (2011)
Kalal, Z., Mikolajczyk, K., Matas, J.: Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 34(7), 1409–1422 (2012)
Hare, S., Saffari, A., Torr, P.H.: Struck: structured output tracking with kernels. In: IEEE International Conference on Computer Vision, pp. 263–270. IEEE, Washington, D.C. (2011)
Lecun, Y., Bengo, Y., Hinton, G.: Deep learning. Nature 521(7553), 436–444 (2015)
Wang, N.Y., Yeung, D.: Learning a deep compact image representation for visual tracking. In: Advances in Neural Information Processing Systems, pp. 809–817. IMLS, Nevada (2013)
Li, H., Li, Y., Porikli, F.: Robust online visual tracking with a single convolutional neural network. In: Cremers, D., Reid, I., Saito, H., Yang, M.-H. (eds.) ACCV 2014. LNCS, vol. 9007, pp. 194–209. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-16814-2_13
Zhang, K.H., Liu, Q.S., Wu, Y., et al.: Robust visual tracking via convolutional networks. IEEE Trans. Image Process. 25(4), 1779–1792 (2015)
Ma, C., Huang, J.B., Yang, X.K., et al.: Hierarchical convolutional features for visual tracking. In: IEEE International Conference on Computer Vision, pp. 3074–3082. IEEE, Washington, D.C. (2015)
Wu, Y., Lim, J., Yang, M.H.: Online object tracking: a benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 37(9), 1834–1848 (2015)
Wang, X., Hou, Z., Yu, W., et al.: Robust visual tracking via multiscale deep sparse networks. Opt. Eng. 56(4), 043107 (2017)
Arpit, D., Zhou, Y., Ngo, H., et al.: Why regularized auto-encoders learn sparse representation? In: International Conference on Machine Learning, pp. 134–144. IMLS, Nevada (2015)
Nair, V., Hinton, G.,: Rectified linear units improve restricted Boltzmann machines. In: International Conference on Machine Learning, pp. 807–814. IMLS, Nevada (2010)
Glorot, X., Bordes, A., Bengio, Y.: Deep sparse rectifier neural networks. In: International Conference on Artificial Intelligence and Statistics, pp. 315–323. Microtome, Brookline (2011)
Li, J., Zhang, T., Luo, W., et al.: Sparseness analysis in the pretraining of deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. PP(99), 1–14 (2016)
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using scale deep network. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2366–2374. IEEE, Washington, D.C. (2014)
Gao, C., Chen, F., Yu, J.G., et al.: Robust visual tracking using exemplar-based detectors. IEEE Trans. Circ. Syst. Video Technol. 27(2), 300–312 (2016)
Zhang, T.Z., Liu, S., Xu, C.S., et al.: Structural sparse tracking. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 150–158. IEEE, Washington, D.C. (2015)
Zhong, W., Lu, H., Yang, M.H.: Robust object tracking via sparsity-based collaborative model. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1838–1845. IEEE, Washington, D.C. (2012)
Wang, G.F., Qin, X.Y., Zhong, F., et al.: Visual tracking via sparse and local linear coding. IEEE Trans. Image Process. 24(11), 3796–3809 (2015)
Danelljan, M., Khan, F.S., Felsberg, M., et al.: Adaptive color attributes for real-time visual tracking. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1090–1097. IEEE, Washington, D.C. (2014)
Liu, F., Zhou, T., Yang, J., et al.: Visual tracking via nonnegative regularization multiple locality coding. In: IEEE International Conference on Computer Vision Workshop, pp. 912–920. IEEE, Washington, D.C. (2016)
Li, H., Li, Y., Porikli, F.: DeepTrack: learning discriminative feature representations by convolutional neural networks for visual tracking. In: British Machine Vision Conference, pp. 1–12 (2014)
Acknowledgments
This research has been supported by the National Natural Science Foundation of China (No. 61473309) and the Natural Science Foundation of Shaanxi Province (No. 2016JM6050).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Wang, X., Hou, Z., Yu, W., Jin, Z. (2017). Online Fast Deep Learning Tracker Based on Deep Sparse Neural Networks. In: Zhao, Y., Kong, X., Taubman, D. (eds) Image and Graphics. ICIG 2017. Lecture Notes in Computer Science(), vol 10666. Springer, Cham. https://doi.org/10.1007/978-3-319-71607-7_17
Download citation
DOI: https://doi.org/10.1007/978-3-319-71607-7_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-71606-0
Online ISBN: 978-3-319-71607-7
eBook Packages: Computer ScienceComputer Science (R0)
