
Abstract
Most of the existing pavement image crack detection methods cannot effectively solve the noise problem caused by the complicated pavement textures and intensity inhomogeneity. In this paper, we propose a novel fully automatic crack detection approach by incorporating a pre-selection process. It starts by dividing images into small blocks and training a deep convolutional neural network to screen out the non-crack regions in a pavement image which usually cause lots of noise and errors when performing crack detection; then an efficient thresholding method based on linear regression is applied to the crack-block regions to find the possible crack pixels; at last, tensor voting-based curve detection is employed to fill the gaps between crack fragments and produce the continuous crack curves. We validate the approach on a dataset of 600 (2000 × 4000-pixel) pavement images. The experimental results demonstrate that, with pre-selection, the proposed detection approach achieves very good performance (recall = 0.947, and precision = 0.846).
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Road maintenance plays an important role in safe driving. The world’s road network has reached 64,285,009 km and the United States has 6,586,610 km [1]. It needs a huge cost for maintenance and upgrade of such immense road network. Pavement crack is one of the most common road distresses and is also the most important information to be collected in road management system.
During the last three decades, researchers have paid a lot of attention to automatic pavement crack detection using various image processing methods. Reference [2] gives a comprehensive summaries about existing pavement cracking detection methods. Intensity thresholding was used in the early approaches widely because it is fast and straightforward; however, due to the complexity of pavement textures at different scales and non-uniform illuminance, thresholding cannot achieve good performance [3]. A dynamic optimization method was utilized to detect pavement cracks and showed good performance, but the time complexity is too high [4]. Shi et al. [5] proposed a method named “CrackForest” which applied random structured forest [6] to crack detection and achieved good performance; they use the distribution differences of the statistical feature histogram and statistical neighborhood histogram to discriminate true cracks from noises; but it cannot remove the noises which connected to the true crack regions. In addition, Cheng et al. [7, 8] used fuzzy logic and neural network to find the proper thresholds and segment the darker crack pixels from the background; Zou et al. [9] used tensor voting to find the local maximum as the crack seeds and to build the minimal spanning tree to represent the actual crack pattern; Wang et al. [10] proposed a wavelet-based method which uses different scales of wavelet transformation information to detect pavement cracks; Zalama et al. [11] used visual features extracted by Gabor filters for road crack detection; Oliveira and Correia [12] developed an automatic detection system based on an unsupervised pattern recognition method; and Song et al. [13] proposed a dual-threshold method for pavement crack detection. All these methods achieved some success in their cases, but still cannot get a satisfying performance considering both the detection accuracy and time complexity; especially, on different datasets. Two main problems still exist in current approaches: (1) they are sensitive to image noise, and would produce lots of false positives which cause a low precision; and (2) most of the approaches can only produce discontinuous crack fragments because of their sensitivity to non-uniform intensity.
For the last ten years, deep learning has achieved great success and obtained better performance in solving many problems [14] comparing to the traditional hand-crafted feature extraction methods [15, 16]; and transfer learning showed great advantage in training complex deep neural network [17, 18]. Zhang et al. [19] designed a 6-layer convolutional neural network to do crack detection using the dataset captured by a cellphone. The major problems of this approach are: it used the cellphone captured images which are easy to process due to the high quality and less noise; however, they are far from the practice, that makes the work less useful; the generalization ability of the network architecture is weak, and it is hard to process different datasets containing actual industry images; and using patch-wise classification [20, 21] for pixel-level/pixel-wise detection is unrealistic due to its huge time complexity.
To solve the above problems, we proposed a novel pre-selection method to remove most noise by discarding the non-crack image regions which can reduce the false positives significantly in later crack detection; then an efficient thresholding method based on linear regression is proposed to segment crack-block regions; and in order to overcome the discontinuous fragment problem existing in most threholding methods, tensor voting based curve detection is employed to fill the gaps between crack fragments successfully. The experimental results demonstrate the effectiveness of the proposed approach.
2 Proposed Method
The main idea of this work is doing a pre-selection to screen out most non-crack areas in an image before crack detection. We first divide the images into small crack blocks and train a deep convolutional neural network to classify the crack/non-crack blocks which are used to divide the pavement image area into crack/non-crack regions; the generic knowledges learned from ImageNet dataset [22] is transferred to train the network successfully; then a linear model is built to quickly find the best thresholds and segment the crack-block regions of the image; likewise, the segmented results contain many crack fragments; therefore, tensor voting based curve detection method is finally applied to fill the gaps between crack fragments and produce the real long crack curves refer Fig. 1 for an overview of the proposed method.

Flowchart of the proposed method
2.1 Preprocessing
Different from Zhang’s dataset [19], our pavement images are captured by single line-scan industry camera. The camera could scan 4 m wide road area into a 4000-pixel wide line, and store a 2000 × 4000-pixel image for every 2000 lines. Due to different lighting conditions, the illuminance along the scanning line could be different which may cause the non-uniform intensity levels in different columns, see Fig. 2 (left). The column-wised illuminance balancing from [11] is performed to eliminate the non-uniform gray levels. The mean value of each column is set to 128.

Original low-quality pavement image captured by a vehicle running at 100 km/h (left) and the illuminance balanced image (right).
2.2 T-DCNN Pre-selection
To conduct pre-selection, a transfer leaning-based deep convolutional neural network (T-DCNN) is trained to classify the crack and non-crack image blocks. 600 (2000 × 4000-pixel) crack images with low similarity are selected from 30,000 images. Among them, 400 images were used to yield the training set of 40,000 crack and 40,000 non-crack blocks (200 × 200-pixel). The other 200 images were used to yield the test set of 20,000 crack and 20,000 non-crack blocks. In order to make the dataset with more variability, we use both image resize and image rotation to augment the dataset. These two methods can efficiently expand the variability of the dataset because: (1) crack has the property of direction invariance, since a crack changes its direction, it is still a crack; and (2) different cracks may have different widths, and the pavement textures might have different coarse levels; therefore, the resized images (we used 90%, 95%, 100%, 105% and 110% of the original images, respectively) can also be used to generate the image blocks.
For training the network using transfer learning, three issues need to be considered: what knowledge could be transferred; how to transfer the knowledge and when to transfer [17]. The knowledge learned by a multi-layer neural network contains plenty of knowledge from the source task, but not all of them are useful for different tasks. In deep convolutional neural networks, low-level layers learned more generic features, e.g. edges or color blobs, which occur regardless of the exact cost function and image dataset [17, 18]. Those features could be utilized to build different kinds of parts and produce various objects. Middle and high-level knowledges contain more information specified by the source task which have weaker transferability.
In our case, only the basic generic knowledge is transferred from the pre-trained model using ImageNet dataset [22], see Fig. 3. The reasons are: (1) the pattern of crack is relatively simple; therefore, the generic knowledge could be used to extract the crack successfully (the feature maps in Fig. 4 proves this assumption); (2) the pattern of crack has low similarity with the natural objects like dog, cat, etc.; therefore, the middle and high level knowledges are useless and we do not transfer them. The related fine-tuning details are described in experiment section.

Transfer the ImageNet generic knowledge. C1, C2, …, and C5 are convolution layers; F6, F7 and F8 are fully connected layers; the green lock shows that the generic features are transformed directly without change during training; the red unlocked locks are for fine tuning, which means that they transfer the weights and allow them to be relearned during training; and the weights of last two fully connected layers are randomly initialized and trained from scratch. (Color figure online)

An image block sample with crack (left) and the related feature maps (right) after convolution layer 5 of the T-DCNN (see Fig. 3 about the network architecture). It is noticed that many of the feature maps show the crack pattern as the original image which supports the assumption that generic knowledge transferred from ImageNet could be used to extract the crack pattern and perform the classification.
Before doing the crack detection, a pavement image is firstly divided into small blocks; then the trained network is used to classify the image blocks as crack/non-crack blocks and divide the image area into crack and non-crack regions at the same time. In order to get more accurate crack regions, the image blocks are sampled every 100 pixels with overlap between sample blocks. Then, most of the non-crack regions are discarded so that the crack detection could be done by only focusing on the crack regions, see Fig. 5.

Crack and non-crack regions classified using T-DCNN pre-selection. (a) Result after the pre-selection: the white regions are those classified as crack regions and the black regions are non-crack regions. (b) Result after removing false positive crack regions in (a) whose size is smaller than 3 times of the block-size. (c) The image only focuses on the crack regions.
2.3 Crack Detection
After T-DCNN pre-selection, the proposed detection method is applied to the crack regions for obtaining the detection results. Since crack pixels are usually darker than non-crack pixels, we segment the crack-block regions using intensity-thresholding method and find the possible crack pixels. A linear model is built by using linear regression to find the best threshold for each crack block. The best threshold is defined as the threshold which maximizes the F 1-measure \( \left( {\frac{2*precison*recall}{precision + recall}} \right) \) [26] of the segmented result against the ground truth of each crack block. In our experiment, the segmented results using thresholds from M − 30 to M + 30 (M is the mean value of the block) are stored and compared with the ground truth to find the best threshold for each crack block (best thresholds of 4,000 different crack blocks are used to build the model). Then the initial model is built with mean (M), standard deviation (SD), smoothness (SM), third momentum (TM) and uniformity (UF) [21] as the predictors; and the best threshold (T) as the response variable:
Then LASSO [24] is used to find the most significant predictors. In our case, M, SD and TM were selected as the most significant predictors, and the prediction model is:
Focusing on the crack-block regions, we calculate the best threshold using Eq. (2) and apply the thresholding to obtain the thresholded image; after that, the noise removing operation is employed to eliminate small noises; there are many discontinuous crack fragments after the above steps; therefore, the tensor voting-based curve detection [25] is employed to fill the gaps between the crack fragments and produce the elongated crack curves. Note that some small gaps are produced by using the maximum formula from examining the orthogonal along the curve [27]; then a morphology close operation [23] is conducted and the noise fragments smaller than experiment-determined value 40 pixels are removed to generate the final results. Refer Figs. 6 and 7 about the related results.

Thresholded image after T-DCNN pre-selection (left) and the result removing small noises less than 30 pixels (right).

Tensor voting based curve detection result (left) and noise fragments removed result (right).
3 Experiment
The experiments are performed using an HP Z220 workstation with 8G memory; a Nvidia QuadroK4000 GPU is used for training and testing the deep convolutional neural network. The models are built with software package Caffe [28]; Matlab R2014a is used as the programming tool.
3.1 Dataset and Metrics
The dataset is obtained from the images captured by a line-scan camera. The camera is set at a height of 2.3 m on the top of a vehicle and could scan 2 m × 4 m road area to generate an image of 2000 × 4000-pixel, i.e., a road area of 1 mm2 corresponds to 1 pixel. Furthermore, the capturing vehicle is able to run at 100 km/h without frame loss which is hard to achieve by using cellphone camera. The speed also makes it usable for actual engineering application to capture huge amount of images of highways. To process this kind of images is more challenging due to low resolution and high noise.
Pre-selection performances (Table 1) of four different methods were evaluated based on recall, accuracy and the converge time for different convolutional neural network models are also present using number of iterations/epochs. We also compared the proposed method with the current state-of-the-art method in [5]; the performances are evaluated using recall, precision and F 1-measure \( \left( {\frac{2*precison*recall}{precision + recall}} \right) \). The precision and recall can be computed on true positive (TP), false negative (FN) and false positive (FP) by the following way:
3.2 Fine-Tuning ImageNet-Based Model
The architecture of the network in Fig. 3 is adopted from [22], which is pre-trained with Caffe [28] using ImageNet dataset. The fine-tuning strategies are as follows: the generic knowledge from first convolution layer are transferred directly without any change during training; base learning rate is changed from 0.01 to 0.001; the test iteration is set as 100, which means that for each time the network calculates the average accuracy of 100 iterations; min-batch for each iteration is set as 200; learning policy is for every “step size” (100 is used) iterations, the learning rate decreases to:
where base_lr is the base learning rate, gamma is the decreasing factor (set as 0.2), iter is the current iteration time and step is the step size; “weight decay” used to update the back-propagate gradient is set as 0.005; all the weights of the convolution layers are copied from the source pre-trained network; weights of the last 2 fully-connected layers are set randomly; the number of outputs from the last layer is set to 2 which stands for the crack and non-crack categories; and the max iteration is set to 40000.
Considering the efficiency and accuracy, 200 × 200-pixel image blocks are used as the training and test sets. During training, a test operation was performed every 100 iterations; finally, we obtained a 0.943 pre-selection accuracy after 40000 iterations on the test set; however, we found that the network had already reached the best performance after 400 iterations and changed little from 400 to 40000 iterations.
3.3 Experimental Results
The 6-layer network in [19] is trained using our dataset. The classification accuracy stayed on low level without change after 200 iterations (see Table 1); the recall is 0.933 and the accuracy is very low (0.513) which means most non-crack blocks are classified as crack blocks wrongly. The method using Hog (histogram of oriented gradients) with cell sizes of 32 × 32-pixel and 16 × 16-pixel as feature extractor and SVM (support vector machine) with Gaussian kernel as the classifier is also tested; the recall is 0.920, but the accuracy is 0.683 because the non-crack blocks with complicated textures cannot be discriminated from the crack blocks by only using statistical features. In addition, we also did the pre-selection operation by training the network in [22] without fine-tuning; 0.921 recall and 0.886 accuracy were achieved; however, it used 6100 iterations to converge to the results which cost a lot of time than using transfer learning (converged to 0.997 recall and 0.943 accuracy after only 400 iterations). The results demonstrate that the transfer leaning-based method using the deep convolutional neural network in [22] is easy-to-train and has good generality; furthermore; and transferring the generic features to classify the crack patterns is effective.
For evaluation of the detection performance, ground truths of the 200 test images are manually marked. Due to the manually marked difference, the detected pixels located in no more than 6 pixels away from manually marked ground truth are considered as true positives. We compared the detection performance with state-of-the-art approach CrackForest in [5]; as shown in Table 2, CrackForest achieved quite low precision (0.506) and F1-measure (0.620) because many noises cannot be removed effectively, especially it fails to cope with the noises connected to the true crack regions; benefit from the T-DCNN pre-selection, the proposed approach achieved very good performance (see Table 2). Please refer the related results in Fig. 8.

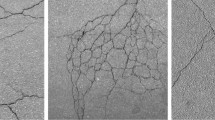
Comparison of different methods on the challenging images. (a) and (b) are original images; (c) and (d) are the manually marked ground truths; (e) and (f) are the detection results of CrackForest; (g) and (h) are the results of proposed method.
4 Conclusion
In this paper, we proposed a novel fully automatic crack detection approach by incorporating a transfer learning-based pre-selection which significantly reduced the number of false positives from the noisy non-crack image regions; an efficient thresholding method based on linear regression is also developed to quickly segment the crack-block regions and find the possible crack pixels; moreover, tensor voting based curve detection method is employed to link the non-continuous crack fragments and extract the crack curves successfully. The proposed method achieves better performance comparing to the current state-of-the-art approach “CrackForest”. In the future, we will design an intelligent detection system which can detect more kinds of complex distresses under different road conditions.
References
C.I.A.: The world fact book. https://www.cia.gov/library/publications/resources/the-world-factbook/. Accessed 15 March 2017
Zhang, K., Cheng, H.D., Zhang, B.: Unified approach to pavement crack and sealed crack detection using pre-classification based on transfer learning. J. Comput. Civil Eng. (2017). https://doi.org/10.1061/(ASCE)CP.1943-5487.0000736
Koutsopoulos, H.N., Sanhouri, I.E., Downey, A.B.: Analysis of segmentation algorithms for pavement distress images. J. Transp. Eng. 119(6), 868–888 (1993)
Tsai, Y.C., Kaul, V., Mersereau, R.M.: Critical assessment of pavement distress segmentation methods. J. transportation Eng. 136(1), 11–19 (2010)
Shi, Y., Cui, L., Qi, Z., Meng, F., Chen, Z.: Automatic road crack detection using random structured forest. IEEE Trans. Intell. Transp. Syst. 17(12), 3434–3445 (2016)
Dollar, P., Zitnick, C.L.: Structured forest for fast edge detection. In: Proceedings of the IEEE ICCV, Sydney, pp. 1841–1848 (2013)
Cheng, H.D., Chen, J., Glazier, C., Hu, Y.G.: Novel approach to pavement crack detection based on fuzzy set theory. J. Comput. Civil Eng. 13(4), 270–280 (1999)
Cheng, H.D., Wang, J., Hu, Y., Glazier, C., Shi, X., Chen, X.: Novel approach to pavement cracking detection based on neural network. J. Transp. Res. Board 1764(13), 119–127 (2001)
Zou, Q., Cao, Y., Li, Q., Mao, Q., Wang, S.: CrackTree: automatic crack detection from pavement images. Pattern Recogn. Lett. 33(2012), 227–238 (2012)
Wang, K., Li, Q., Gong, W.: Wavelet-based pavement distress image edge detection with a trous algorithm. J. Transp. Res. Rec. 2024, 24–32 (2000)
Zalama, E., Gomez-Garcia-Bermejo, J., Medina, R., Llamas, J.: Road crack detection using visual features extracted by Gabor filters. Comput. Aided Civil Infrastruct. Eng. 29(5), 342–358 (2014)
Oliveira, H., Correia, P.L.: Automatic road crack detection and characterization. IEEE Trans. Intell. Transp. Syst. 14(1), 155–168 (2013)
Song, H.X., Wang, W.X., Wang, F.P., Wu, L.C., Wang, Z.W.: Pavement crack detection by ridge detection on fractional calculus and dual-thresholds. Int. J. Multimedia Ubiquit. Eng. 10(4), 19–30 (2015)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 512(28), 436–444 (2015)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego (2005)
Zhou, R., Kaneko, S., Tanaka, F.: Early detection and continuous quantization of plant disease using template matching and support vector machine algorithms. In: Proceedings of the IEEE Symposium on Computing and Networking, Japan, pp. 300–304 (2013)
Pan, S.J., Yang, Q.: A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22(10), 1345–1359 (2010)
Oquab, M., Bottou, L., Laptev, I., Sivic, J.: Learning and transferring mid-level image representations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, pp. 1717–1724 (2014)
Zhang, L., Yang, F., Zhang, Y.D., Zhu, Y.J.: Road crack detection using deep convolutional neural network. In: Proceedings of the IEEE Conference on Image Processing, Phoenix, pp. 3708–3712 (2016)
Hariharan, B., Arbeláez, P., Girshick, R., Malik, J.: Simultaneous detection and segmentation. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8695, pp. 297–312. Springer, Heidelberg (2014). https://doi.org/10.1007/978-3-319-10584-0_20
Pinheiro, P.H., Collobert, R.: Recurrent convolutional neural networks for scene labeling. In: Proceeding of International Conference on Machine Learning, Beijing, pp. 82–89 (2014)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural network. In: Proceeding of Neural Information Processing Systems, Nevada (2012)
Gonzalez, R.C., Woods, R.E., Steven, S.L.: Digital Image Processing Using Matlab. Addison-Wesley, Boston (2009)
Sheather, S.J.: A Modern Approach to Regression with R. Springer, Heidelberg (2009). https://doi.org/10.1007/978-0-387-09608-7
Medioni, G., Tang, C.: Tensor voting: theory and applications. In: Proceedings of the 12th Congress Francophone AFRIF-AFIA de Reconnaissance des Formes et Intelligence Artificielle (2000)
Power, D.: Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Technol. 2(1), 37–63 (2011)
Linton, T.: Tensor voting. https://www.mathworkcia.gov/library/publications/resources
Jia, Y.: Caffe: an open source convolutional architecture for fast feature embedding (2013). http://caffe.berkeleyvision.org/
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Zhang, K., Cheng, H. (2017). A Novel Pavement Crack Detection Approach Using Pre-selection Based on Transfer Learning. In: Zhao, Y., Kong, X., Taubman, D. (eds) Image and Graphics. ICIG 2017. Lecture Notes in Computer Science(), vol 10666. Springer, Cham. https://doi.org/10.1007/978-3-319-71607-7_24
Download citation
DOI: https://doi.org/10.1007/978-3-319-71607-7_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-71606-0
Online ISBN: 978-3-319-71607-7
eBook Packages: Computer ScienceComputer Science (R0)
