
Abstract
Imbalance among components of large scale parallel simulations can adversely affect overall application performance. Software induced imbalance has been extensively studied in the past, however, there is a growing interest in characterizing and understanding another source of variability, the one induced by the hardware itself. This is particularly interesting with the growing diversity of hardware platforms deployed in high-performance computing (HPC) and the increasing complexity of computer architectures in general. Nevertheless, characterizing hardware performance variability is challenging as one needs to ensure a tightly controlled software environment.
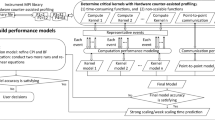
In this paper, we propose to use lightweight operating system kernels to provide a high-precision characterization of various aspects of hardware performance variability. Towards this end, we have developed an extensible benchmarking framework and characterized multiple compute platforms (e.g., Intel x86, Cavium ARM64, Fujitsu SPARC64, IBM Power) running on top of lightweight kernel operating systems. Our initial findings show up to six orders of magnitude difference in relative variation among CPU cores across different platforms.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Markidis, S., et al.: The EPiGRAM project: preparing parallel programming models for exascale. In: Taufer, M., Mohr, B., Kunkel, J.M. (eds.) ISC High Performance 2016. LNCS, vol. 9945, pp. 56–68. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46079-6_5
Beckman, P., Iskra, K., Yoshii, K., Coghlan, S.: The influence of operating systems on the performance of collective operations at extreme scale. In: 2006 IEEE International Conference on Cluster Computing, pp. 1–12, September 2006
Ferreira, K.B., Bridges, P., Brightwell, R.: Characterizing application sensitivity to OS interference using kernel-level noise injection. In: Proceedings of the 2008 ACM/IEEE Conference on Supercomputing, SC 2008, pp. 19:1–19:12. IEEE Press, Piscataway (2008)
Hoefler, T., Schneider, T., Lumsdaine, A.: Characterizing the influence of system noise on large-scale applications by simulation. In: Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2010, pp. 1–11. IEEE Computer Society, Washington, DC (2010)
Petrini, F., Kerbyson, D., Pakin, S.: The case of the missing supercomputer performance: achieving optimal performance on the 8,192 processors of ASCI Q. In: Proceedings of the 15th Annual IEEE/ACM International Conference for High Performance Computing, Networking, Storage and Anaylsis, SC 2003 (2003)
Gerofi, B., Takagi, M., Hori, A., Nakamura, G., Shirasawa, T., Ishikawa, Y.: On the scalability, performance isolation and device driver transparency of the IHK/McKernel hybrid lightweight kernel. In: 2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pp. 1041–1050, May 2016
Giampapa, M., Gooding, T., Inglett, T., Wisniewski, R.W.: Experiences with a lightweight supercomputer kernel: lessons learned from Blue Gene’s CNK. In: Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis. SC (2010)
Pedretti, K.T., Levenhagen, M., Ferreira, K., Brightwell, R., Kelly, S., Bridges, P., Hudson, T.: LDRD final report: a lightweight operating system for multi-core capability class supercomputers. Technical report SAND2010-6232, Sandia National Laboratories, September 2010
Kale, L., Zheng, G.: Charm++ and AMPI: adaptive runtime strategies via migratable objects. In: Advanced Computational Infrastructures for Parallel and Distributed Applications. Wiley (2009)
Kaiser, H., Brodowicz, M., Sterling, T.: ParalleX: an advanced parallel execution model for scaling-impaired applications. In: Proceedings of the International Conference on Parallel Processing Workshops, ICPPW 2009 (2009)
Chunduri, S., Harms, K., Parker, S., Morozov, V., Oshin, S., Cherukuri, N., Kumaran, K.: Run-to-run variability on Xeon Phi based Cray XC systems. In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2017, pp. 52:1–52:13. ACM, New York (2017)
Dighe, S., Vangal, S., Aseron, P., Kumar, S., Jacob, T., Bowman, K., Howard, J., Tschanz, J., Erraguntla, V., Borkar, N., De, V., Borkar, S.: Within-die variation-aware dynamic-voltage-frequency-scaling with optimal core allocation and thread hopping for the 80-core TeraFLOPS processor. IEEE J. Solid-State Circuits 46(1), 184–193 (2011)
Acun, B., Miller, P., Kale, L.V.: Variation among processors under Turbo Boost in HPC systems. In: Proceedings of the 2016 International Conference on Supercomputing, ICS 2016, pp. 6:1–6:12. ACM, New York (2016)
Kelly, S.M., Brightwell, R.: Software architecture of the light weight kernel, Catamount. In: Cray User Group, pp. 16–19 (2005)
Riesen, R., Brightwell, R., Bridges, P.G., Hudson, T., Maccabe, A.B., Widener, P.M., Ferreira, K.: Designing and implementing lightweight kernels for capability computing. Concurr. Comput. Pract. Exp. 21(6), 793–817 (2009)
Riesen, R., Maccabe, A.B., Gerofi, B., Lombard, D.N., Lange, J.J., Pedretti, K., Ferreira, K., Lang, M., Keppel, P., Wisniewski, R.W., Brightwell, R., Inglett, T., Park, Y., Ishikawa, Y.: What is a lightweight kernel? In: Proceedings of the 5th International Workshop on Runtime and Operating Systems for Supercomputers. ROSS. ACM, New York (2015)
Fixed Time Quantum and Fixed Work Quantum Tests. https://asc.llnl.gov/sequoia/benchmarks. Accessed Dec 2017
Kramer, W.T.C., Ryan, C.: Performance variability of highly parallel architectures. In: Sloot, P.M.A., Abramson, D., Bogdanov, A.V., Gorbachev, Y.E., Dongarra, J.J., Zomaya, A.Y. (eds.) ICCS 2003. LNCS, vol. 2659, pp. 560–569. Springer, Heidelberg (2003). https://doi.org/10.1007/3-540-44863-2_55
Bhatele, A., Mohror, K., Langer, S., Isaacs, K.: There goes the neighborhood: performance degradation due to nearby jobs. In: Proceedings of the 25th Annual IEEE/ACM International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2013 (2013)
Rountree, B., Lowenthal, D., de Supinski, B., Schulz, M., Freeh, V., Bletsch, T.: Adagio: making DVS practical for complex HPC applications. In: Proceedings of the 23rd ACM International Conference on Supercomputing, ICS 2009 (2009)
Venkatesh, A., Vishnu, A., Hamidouche, K., Tallent, N., Panda, D., Kerbyson, D., Hoisie, A.: A case for application-oblivious energy-efficient MPI runtime. In: Proceedings of the 27th Annual IEEE/ACM International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2015 (2015)
Ganguly, D., Lange, J.: The effect of asymmetric performance on asynchronous task based runtimes. In: Proceedings of the 7th International Workshop on Runtime and Operating Systems for Supercomputers, ROSS 2017 (2017)
Borkar, S., Karnik, T., Narendra, S., Tschanz, J., Keshavarzi, A., De, V.: Parameter variations and impact on circuits and microarchitecture. In: Proceedings of the 40th Annual Design Automation Conference, DAC 2003, pp. 338–342. ACM, New York (2003)
Oral, S., Wang, F., Dillow, D.A., Miller, R., Shipman, G.M., Maxwell, D., Henseler, D., Becklehimer, J., Larkin, J.: Reducing application runtime variability on Jaguar XT5. In: Proceedings of CUG 2010 (2010)
Pritchard, H., Roweth, D., Henseler, D., Cassella, P.: Leveraging the Cray Linux Environment core specialization feature to realize MPI asynchronous progress on Cray XE systems. In: Proceedings of Cray User Group. CUG (2012)
Yoshii, K., Iskra, K., Naik, H., Beckmanm, P., Broekema, P.C.: Characterizing the performance of big memory on Blue Gene Linux. In: Proceedings of the 2009 International Conference on Parallel Processing Workshops. ICPPW, pp. 65–72. IEEE Computer Society (2009)
Wisniewski, R.W., Inglett, T., Keppel, P., Murty, R., Riesen, R.: mOS: an architecture for extreme-scale operating systems. In: Proceedings of the 4th International Workshop on Runtime and Operating Systems for Supercomputers. ROSS. ACM, New York (2014)
Ouyang, J., Kocoloski, B., Lange, J.R., Pedretti, K.: Achieving performance isolation with lightweight co-kernels. In: Proceedings of the 24th International Symposium on High-Performance Parallel and Distributed Computing, HPDC 2015, pp. 149–160. ACM, New York (2015)
Lackorzynski, A., Weinhold, C., Härtig, H.: Decoupled: low-effort noise-free execution on commodity systems. In: Proceedings of the 6th International Workshop on Runtime and Operating Systems for Supercomputers, ROSS 2016, pp. 2:1–2:8. ACM, New York (2016)
Top500 supercomputer sites. https://www.top500.org/
Jarus, M., Varrette, S., Oleksiak, A., Bouvry, P.: Performance evaluation and energy efficiency of high-density HPC platforms based on Intel, AMD and ARM processors. In: Pierson, J.-M., Da Costa, G., Dittmann, L. (eds.) EE-LSDS 2013. LNCS, vol. 8046, pp. 182–200. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-40517-4_16
Rajovic, N., Rico, A., Puzovic, N., Adeniyi-Jones, C., Ramirez, A.: Tibidabo: making the case for an ARM-based HPC system. Future Gener. Comput. Syst. 36(Supplement C), 322–334 (2014)
Rajovic, N., Carpenter, P., Gelado, I., Puzovic, N., Ramirez, A., Valero, M.: Supercomputing with commodity CPUs: are mobile SoCs ready for HPC? In: Proceedings of the 2013 ACM/IEEE Conference on Supercomputing. SC (2013)
Miyazaki, H., Kusano, Y., Shinjou, N., Shoji, F., Yokokawa, M., Watanabe, T.: Overview of the K computer system. Scitech 48(3), 255–265 (2012)
Intel: Intel Xeon Processor E5–1600/E5-2600/E5-4600 v2 Product Families (2014). https://www.intel.com/content/www/us/en/processors/xeon/xeon-e5-1600-2600-vol-2-datasheet.html
Sodani, A.: Knights landing (KNL): 2nd generation Intel Xeon Phi processor. In: 2015 IEEE Hot Chips 27 Symposium (HCS), pp. 1–24, August 2015
Yoshida, T., Hondou, M., Tabata, T., Kan, R., Kiyota, N., Kojima, H., Hosoe, K., Okano, H.: Sparc64 XIfx: Fujitsu’s next-generation processor for high-performance computing. IEEE Micro 35(2), 6–14 (2015)
Cavium: ThunderX_CP Family of Workload Optimized Compute Processors (2014)
IBM: Design of the IBM Blue Gene/Q Compute chip. IBM J. Res. Dev. 57(1/2), 1:1–1:13 (2013)
Kocoloski, B., Lange, J.: HPMMAP: lighweight memory management for commodity operating systems. In: Proceedings of 28th IEEE International Parallel and Distributed Processing Symposium, IPDPS 2014 (2014)
Widener, P., Levy, S., Ferreira, K., Hoefler, T.: On noise and the performance benefit of nonblocking collectives. Int. J. High Perform. Comput. Appl. 30(1), 121–133 (2016)
Shimosawa, T., Gerofi, B., Takagi, M., Nakamura, G., Shirasawa, T., Saeki, Y., Shimizu, M., Hori, A., Ishikawa, Y.: Interface for heterogeneous kernels: a framework to enable hybrid OS designs targeting high performance computing on manycore architectures. In: 21th International Conference on High Performance Computing. HiPC, December 2014
FFMK Website. https://ffmk.tudos.org
Acknowledgments
Part of this work has been funded by MEXT’s program for the Development and Improvement of Next Generation Ultra High-Speed Computer System, under its Subsidies for Operating the Specific Advanced Large Research Facilities. The research and work presented in this paper has also been supported in part by the German priority program 1648 “Software for Exascale Computing” via the research project FFMK [43]. We acknowledge Kamil Iskra and William Scullin from Argone National Laboratories for their help with the BG/Q experiments. We would also like to thank our shepherd Saday Sadayappan for the useful feedbacks.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Weisbach, H., Gerofi, B., Kocoloski, B., Härtig, H., Ishikawa, Y. (2018). Hardware Performance Variation: A Comparative Study Using Lightweight Kernels. In: Yokota, R., Weiland, M., Keyes, D., Trinitis, C. (eds) High Performance Computing. ISC High Performance 2018. Lecture Notes in Computer Science(), vol 10876. Springer, Cham. https://doi.org/10.1007/978-3-319-92040-5_13
Download citation
DOI: https://doi.org/10.1007/978-3-319-92040-5_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-92039-9
Online ISBN: 978-3-319-92040-5
eBook Packages: Computer ScienceComputer Science (R0)