
Abstract
This paper proposes a learning goal space that visualizes the distribution of the obtained solutions to support the exploration of the learning goals for a learner. Subsequently, we examine the method for assisting a learner to present the novelty of the obtained solution. We conduct a learning experiment using the creative learning task to identify various solutions. To allow analyzing how to create the subject’s own learning goals for subjects, several measurement items related to the success of the task which is not instructed to the subjects are setup. In the comparative experiment, three types of learning feedbacks provided to the subjects are compared. The first type is presenting the learning goal space with obtained solutions mapped on it. The second type is directly presenting the novelty of the obtained solutions mapped on it. The third type is presenting some value that is slightly related to the obtained solution. In the experiments, each subject continues to learn the way to find solutions creatively. Therefore, in a creative learning task, these types of learning feedbacks support the learner continuously to set the learning goals.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
The progress of information technology will lead to the replacement of approximately half of the jobs performed by humans with computers in the near future. The remaining jobs that are of technical difficulty for both artificial intelligence and computers require high creativity or social skills. This paper describes the creativity of both humans and the computer system. According to Boden [2], “creativity is the ability to come up with ideas or artifacts that are novel and valuable.” Previous research on human creativity suggests that “one process of creating ideas involves making unfamiliar combinations of familiar ideas, requiring a rich store of knowledge” (Frey, p. 26) [3]. However, it is extremely difficult for a computer to acquire the creativity of a human. This is so because it is unclear how to combine familiar concepts via unfamiliar approaches. To solve this problem, we focus on a method to utilize the higher creativity of humans compared with that of computers. We propose a mechanism based on a framework of a continuous learning support system provided for a human learner to perceive creativity based on his/her own learning. In the proposed mechanism, the support system generates an already derived learning achievement by combining the original achievement with the solution determined by the learner. Consequently, the learner can reflect his/her own learning trace in the learning goal space. Based on the learning trace, the support system makes the learner aware of the unclear learning results and sense of values. We propose three types of support methods. The first type is the visualization of the learning traces to support the discernment of creativity on learning. We design a learning goal space to visualize a learning trace [9]. It is the distribution of the learning goals attained by a learner who learns an original achievement and of the derived goals generated by the support system. This makes it easier to reflect the learning orientation by showing the position of the learning goal relative to the learning trace. The second type is a discovery support for obtaining unknown solutions by generating a derived achievement based on the negation of the shortest solution of the learner. This encourages the learner to identify his/her unclear solutions. The third type is the generation of a derived achievement by justification of the determined redundant solution. This encourages the learner to notice his/her unclear sense of values.
2 Background
This section describes the theoretical background of this research. After the research on the creativity is described, we summarize an overview of continuous learning because it is the basic framework of the creative learning process, and then we describe the creative learning skill.
2.1 The Definition of Continuous Learning
Continuous Learning is not defined clearly. Some Industrial and organizational psychologists try to conceptualize this term. Smita and Trey [8] reviews research on continuous learning. There are three levels, individual, group and organizational level. One of conceptual definitions of continuous learning is follows; “Continuous learning at the individual level is regularly changing behavior based on a deepening and broadening of one’s skills, knowledge, and worldview”. Our previous research on Continuous learning is described in detail in [11, 12].
2.2 The Research on Creativity
We consider creativity at the base of J.P. Guilford’s approach. Guilford [4] says creativity has primary characteristics, sensitivity to problems, fluency in generating ideas, flexibility and novelty of ideas, and the ability to synthesize and reorganize information [7]. Sensibility to problems is the skill to find the problem. We consider that it is the skill to comprehend the learning task. Fluency in generating ideas shows how many ideas a human create. Flexibility is the skill to create various ideas. Novelty of ideas is the skill to create unusual ideas. The ability to synthesize and reorganize information is the skill to utilize a thing for the divergent purposes. We consider it needs to focus on the interpretation of the meta-learning process. Then we describe several characteristics which are concerned in their research. As sensibility to problems in the task, the learner can comprehend the structure of the learning environment through the trial and errors. As fluency in generating ideas in the task, the learner can find many solutions since the task gives the achievement to him/her. As flexibility in the task, the learner can find the various solutions by seeing his/her learning trace in the learning goal space.
2.3 Intellectual Stimulation
Intellectual stimulation is defined as the leader’s behavior for stimulating the follower’s creativity in the field of business psychology [6]. The intellectual simulation involves such leader behaviors as questioning old assumptions, traditions, and beliefs, stimulating new perspectives and ways of doing things, and encouraging the expression of ideas and reasons [10]. These leader’s behaviors is classified as simulating for the follower’s awareness and encouraging the follower’s new endeavor [6]. We aim to implement the system with the role of intellectual stimulation for encouraging the learner to perform creatively. This paper proposes the component technology to implement two leader behaviors, simulating for the follower’s awareness and encouraging the follower’s new endeavor. The next section explains how to incorporate the component technology with the role of the intellectual stimulation into the continuous learning process for extension to the creative learning process.
2.4 The Creative Learning
The creative learning is defined as the continuous learning with discoveries of unusual solutions from achievements in the learner’s own. In their previous research [11], the human designed the achievements for a learner as the sequence of mazes. However, creative learner needs a new achievement continuously. In other words, it is necessary for the creative learner to discover the new achievements by himself/herself, but it is not easy. So we propose the interactive mechanism between a human learner and the learning support system in which the system derives the achievements from his/her found solutions with two kinds of heuristics. Once the learner found an unusual solution, the system can derive the new achievements from the unusual one.
The Creative Learning Process.
Figure 1 shows the flow of the creative learning process based on the continuous learning process.

The flow of the creative learning process
This process consists of triple cycle. Innermost cycle is called a trial. A trial is defined as a transition sequence from start state to encountering either a goal state. In this cycle, a learner repeats an action and one’s mental process including awareness until the learner results in either success or fail of the task. Second cycle is called an achievement. An achievement is defined as a unit of the main task which is the learning of a maze with the start and the invisible goal. In this cycle, when the trial ends by the encounter with a goal, the learner finds the solution of the achievement. Then, the learner reflects the trial by the reflection of viewing one’s learning traces on the learning goal space. The learning goal space has the role of simulating for the follower’s awareness as intellectual stimulation. This process is described at Section Designing the Learning Goal Space. If current trial is not accomplished, the learner restarts the trial from the start state. Outmost cycle is the creative learning cycle. When the learner accomplished current achievement, the system generates a derived achievement according to the learner’s solution, and then, the learner can challenge next new achievement. Automatically generating a derived achievement process has a role of encouraging the follower’s new endeavor as intellectual stimulation. Section Designing Automatically Generating the Derived Achievement describes this process.
The Creative Learning Skill.
The creative learning skill is defined as the learning skill to try to find more creative solutions on the given tasks or problems having optimal or entrenched solution. We propose the interactive mechanism consisting of two parts. The human part is to find a new solution from the achievement. The support system’s part is to generate a new achievement derived from the human learner’s solution by adding the sub-reward on it randomly to support the learner to find more creative solutions.
3 Designing the Creative Learning Support System
3.1 The Learning Environment by an Maze Model
As the learning environment for a human learner, we adopt a grid maze from start to goal since it is a familiar example to find the path through a trial and error process. First, we define a maze, a path in the maze, and a solution in the maze. A maze is the shape of two-dimensional maze defined by three kinds of states (start, goal and normal state) and the walls surrounding the states. In detail, it is described later as the maze model. A path consists of states and action transition sequence from the start state to the goal state. A solution is a path of the achievement of the maze.
A maze model for creative learning consists of five elements, state set, transitions and walls, action set, and rewards. Figure 2 shows the structure of a two-dimensional grid maze.

The structure of a 3 × 2 simple maze
The n x m grid maze with four neighbors consists of the n x m n number of 1 × 1 squares. It is called a simple maze surrounded by walls in a rectangle shape. Figure 2(a) shows a 3 × 2 simple maze with a start and a goal. In a grid maze, every square touches one of their edges except for a wall. Each square in a maze model is called a state. A state can be visited at once. Transitions between states in a maze model is defined whether corresponding square with four neighbors, {up, down, left, right} is connected or not connected by a wall. They are represented as the labeled directed graph as shown in Fig. 2(b). Action set is defined as a set of labels to distinguish the possible transitions of a state. In a grid maze, the learner can take four kinds of actions: up, right, down, left. Note that a trial is a transition sequence from the start state to encountering either a goal state or a wall, and the action toward a wall results in the transition to the start state to restart the trial. Transition to the goal state results in the success of the achievement, then the learner finds a solution and obtains a main reward (+1).
3.2 Designing the Creative Learning Support System
This section describes the way to automatically generate a new achievement as shown in Fig. 1. First we describe a stage and an achievement in the creative learning task. A stage is a set of achievements of the same maze shape. An achievement of the creative learning task is defined as the learning of a maze to find a path from the start state to the goal state. An achievement consists of a maze shape and generated sub-rewards if any. It is a unit of the learning which is either an original achievement which consists of only maze shape or a derived achievement which contains generated sub-rewards. Figure 3 shows the flow of generating a new achievement by the system.

The flow of generating a new achievement by the system
The inner loop in Fig. 3 shows the interactive process of generating a new achievement by the system from the solution the learner searched. The inner loop is corresponding to the flow of a creative learning cycle shown in Fig. 1. The learner follows the achievement cycle including one’s mental process until finding a solution. After a solution is found by the learner, if it is a new one, it is displayed on the learning goal space as the found learning goal for the reflection of the learner, and then the system derives the achievement by adding a sub-reward according to the type of the solution. The system resets the achievement and the learner tries it. The outer loop in Fig. 3 shows the progress of the learning stage. The outer loop is not shown in Fig. 3. The loop provides opportunity to perform an achievement without sub-rewards to the learner. It is two ways. One is when the learner decides to leave a current stage. Another is the decision of the system when the condition for the stage progress is complete. In this paper, the sequence of the rectangle-shaped maze shape of the stage is predefined.
3.3 Designing Automatically Generating the Derived Achievement
Classification of the Solutions for Creative Learning.
This section describes the classification of the solutions for creative learning. First, we mention the size of solution. Table 1 shows the classifying solutions based on the length of them.
We classify them whether it is shortest or not. Note that to make a redundant solution into the learning goal, it is necessary to introduce some optimality. Second, we introduce the optimality of a solution to define the quality of solution. This paper adopts average reward reinforcement learning framework. In it, optimal solution is defined as a solution with the maximum average reward. Note that average reward of it is the sum of the acquired rewards divided by the solution length. Therefore, the shortest solution with acquiring rewards has a tendency to be optimal.
In the field of reinforcement learning, the way to find an optimal solution has been investigated in recent years. However, it is not the end of learning on creative learning. So we focus on the learning after an optimal solution found, and also focus on redundant, i.e. non-optimal solutions to utilize them since they have not been drawn attention as learning goals. Next subsection describes how to derive the learning goal from a shortest solution and from a redundant solution.
Deriving a New Achievement by Negating a Shortest Solution.
This subsection describes the method to generate a derived achievement. When a learner identifies the shortest solution, the system adds a negative sub-reward on one of the transitions in the identified path to negate it. This roughly negation of the optimal solution derives a new achievement creatively as the remaining redundant solutions encourage the learner to be creative by avoiding the negative sub-reward to obtain new solutions. Note that the negative sub-reward is randomly placed in the path, and its value is −1.
Deriving a New Achievement by Justifying a Redundant Solution.
This subsection describes the method to generate a derived achievement based on the justification of a non-optimal solution. When a learner obtains a redundant solution, the system adds a positive sub-reward on one of the transitions in the identified path to justify it. This crude justification of the redundant solution yields a new achievement creatively because there may be better solutions with a positive sub-reward than this redundant solution. Note that the positive sub-reward is placed randomly in the path, and its value is +1.
3.4 Designing the Learning Goal Space
The learning goal space is the space in which found solutions are positioned to display. The learning goal space has the vertical axis as the solution quality and the horizontal axis as the solution cost. The solution cost is the cost for implementing the solution. The solution quality expresses how many sub-goals the leaner is able to achieve in the process of finding solution. These two axes are generalized to the learning cost and the learning quality. The learning cost partially depends on each learner. In this paper, we simplify the learning cost, and define the solution cost as independent axis instead of it. A point on the learning goal space is a set of solutions which the solution quality equals the solution cost. In Sect. 4.3, we discuss about the application of this proposed system to the other tasks. Figure 4 shows the illustrated example of the learning goal space.

The illustrated example of the learning goal space
Si is the ith solution found by the learner. The number of S expresses the order in which the learner finds them. The transition from S1 to S2 shows that the direction of learning is right, and it means the learning only increases the solution cost towards the horizontal learning goal. S3 is transited from S2 towards the vertical direction in which the solution quality only grows. S5 is transited from S3 towards the direction simultaneously to increase both the solution cost and the solution quality.
4 Experiment
The aim of the experiment is to evaluate effectiveness of three ways to show the learning record. The comparative experiment is conducted for four subjects. All subjects all university students in their twenties.
4.1 Experimental Setup
Experimental Task.
We explain the experimental task on two points of view, the subject point of view and the experimenter point of view.
First, we explain the experimental task on the subject point of view. This experimental task is a maze task with multiple paths from start to goal. The instructions about the score are three points: if the subject finds the goal, the subject obtains score +1; if the subject goes through the green rectangle, the subject obtains score +1; if the subject goes through the purple rectangle. The termination condition of the experimental task is to complete all the stages. The completing condition of the stage is not shown to the subject. During the experiment, a countdown relating to the completing condition is shown to the subject. The countdown is finished, the stage progresses to the next stage. When the subject finds the goal, the learning record by the method described later is shown.
Next, we explain the experimental task on the experimenter point of view. The score is added on the path of the solution. If the subject finds the solution having the unknown path length, the score as the positive sub-reward +1 is added. If the subject finds the solution having the known path length, the score as the negative sub-reward −1 is added. The termination condition of the experimental task is to complete five stages. The completing condition of the stage is to find the designated number of the path-length kinds. Table 2 shows the simple maze size and the initial value to complete the stage on each stage.
The Flow of the Experiment.
The flow of the experiment is as follow.
-
Step 1. The subject reads through the instruction for the experiment task.
-
Step 2. The subject starts the experiment task when he likes to start it. He is able to read the instruction for the experimental task during the experimental task.
-
Step 3. The subject takes the experimental task.
-
Step 4. The subject answers the questionnaire after the experimental task.
-
Step 5. The subject answers the hearing investigation.
Next, the flow of the experimental task is as follow.
-
Step 3-1. The subject takes either four actions, up, down, left, right, with four way controller in the stage.
-
Step 3-2. When the subject finds the path from start to goal, the learning record is shown.
-
Step 3-3. The subject makes the learning record closed.
-
Step 3-4. If the subject meets the completing condition or if the limited time is over, next is Step 3-6.
-
Step 3-5. Return Step 3-1.
-
Step 3-6. The stage progresses to the next stage. The learning record is reset. If the stage is final, the experimental task is ended.
The stage progresses to the next stage. The learning record is reset. If the stage is the final stage, the experimental task is finished. If not, return Step 3-1.
The GUI of Creative Learning Support System.
Creative learning support system consists of two windows, Maze window and Learning goal space window. Figure 5 shows Maze window before reaching the goal state, and Fig. 6 shows Maze window after reaching the goal state once.

Maze window before reaching the goal state

Maze window after reaching the goal state once (Color figure online)
As shown in Fig. 5, Maze window says Stage number, The number until completing this stage, and Time left, and has the grid area and Restart button. The grid area in Maze window shows the maze surrounded by black rectangles. Start state labeled as S in the square is visible in the maze, while goal state labeled as G is invisible. As shown in Fig. 6, goal state becomes visible after reaching the goal state once. The green rectangle expresses a positive sub-reward, and the purple rectangle expresses a negative sub-reward. The gray square is the visited state. Figure 7 shows Learning goal space window.

Learning goal space window (Color figure online)
As shown in Fig. 7, Learning goal space window shows the found solution in the grid area, the learning goal space, The number until completing this stage, Previous stage button and Current stage button. The learning goal space has two kinds of points, red and blue. A red point is the learner’s recent found solution. Blue points are the learner’s found solutions except for the learner’s recent found solution. The learner can see the previous the learning goal space with pushing Previous stage button above OK button and below the learning goal space. The learner pushes Current stage button right next to Previous stage button to come back the learning goal space of the current stage. This experiment compares the learning goal space with two methods described in next subsection.
The Compared Methods.
This experiment is conducted by three compared method. Three compared methods are as follow. The sequence of findings is a natural number showing what number the path from start to goal is found.
-
(i)
Showing the scatter chart in the learning goal space
The learning goal space is a two-dimensional space consisting of two axes, the score and step length of a found solution. Figure 8(a) shows the representation example of the learning goal space. The position of the solution found by the subject is decided by the score of the solution and the step length of the solution. The solution is plotted as a point in the learning goal space.
Fig. 8. 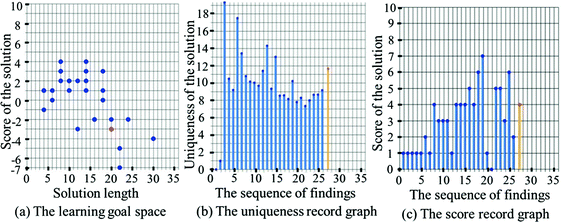
Each representation example of the compared methods
-
(ii)
Showing the uniqueness record graph in the sequence of findings
The uniqueness record is a two-dimensional space consisting of two axes, the uniqueness and the sequence of findings. Figure 8(b) shows the representation example of the uniqueness record graph. The uniqueness record shows the uniqueness of the solution in the sequence of findings with a bar graph. The uniqueness is the quantitative value expressing the novelty of the solution. The novelty of the solution is calculated as follow [5].
$$ {\text{Novelty}}\left( {{\text{s}},{\mathbb{S}}} \right) = \frac{1}{{\left| {\mathbb{S}} \right| - 1}}\sum\nolimits_{{s_{i} \in {\mathbb{S}}}}^{N - 1} {dist\left( {s_{i } ,s} \right)} $$(1)Where Novelty \( \left( {{\text{s}},{\mathbb{S}}} \right) \) is the novelty of the solution, \( {\mathbb{S}} \) is the set of the solutions, \( \left| {\mathbb{S}} \right| \) expresses the number of the solutions in \( {\mathbb{S}} \), s is the most recent found solution, \( dist\left( {s_{i} ,s} \right) \) is the Euclid distance between \( s_{i} \) and \( s \) in the learning goal space. This is why the learning goal space is not a grid space.
-
(iii)
Showing the score record graph in the sequence findings
The score record is a two-dimensional space consisting of two axes, the score and the sequence of findings. Figure 8(c) shows the representation example of the uniqueness record graph. The score record shows the scores of the solution in the sequence of findings with a bar graph.

The difference between the learning goal space and the score record graph is the number of the learning goals shown to the subjects. The axes of the learning goal space are the score of the solution and the step length of the solution. The both axes are the learning goals. On the other hand, the axes of the score record graph are the score and the sequence of findings. While the score is the learning goal, the sequence of findings is not it.
The difference between the learning goal space and the uniqueness record graph is the way to show the novelty of the solutions. In the learning goal space, the positions of the found solutions express the novelty. Showing the novelty in the learning goal space is implicit. On the other hand, in the uniqueness record graph, the quantitative values express the novelty of the solutions. Showing the novelty in the uniqueness record graph is explicit.
The difference between the score record graph and the uniqueness record graph is whether the learning goal is simple or complex. In the score record graph, the score of the solution is accumulative score acquired by the finding the sub-reward and the goal. The score is simply calculated. On the other hand, in the uniqueness record graph, the uniqueness is calculated by the Eq. (1) using the score and the step length. The uniqueness is complexly calculated.
The Instruction for the Subjects.
A brief summary of the instruction for subjects includes the following points:
-
The objective of the task is to complete all stages.
-
If you reach the goal, you obtain +1 score.
-
If you go through the green rectangle grid, you obtain +1 score.
-
If you go through the purple rectangle grid, you obtain −1 score.
-
A time limit is six minutes in each stage.
-
You must look at {the learning goal, the score record, the uniqueness}* window. *One of three compared methods is shown.
-
Step length is the number of actions from start to goal. (Only the learning goal space and the uniqueness score)
Uniqueness expresses how unique the path is.
The Measurement Items.
The major measurement items of the experiment are as follows:
-
(a)
The number of the trials
-
(b)
The number of the found solution
-
(c)
The number of the path
-
(d)
The number of the learning goal
-
(e)
Novelty on the learning goal space
-
(f)
The number of the path length kinds
Note that the number of the path length kinds (f) shows the accumulative number of the all completing conditions. In the case that the subject completes all stages, the number of the path length kinds (f) is forty-five. Novelty on the learning goal space (e) is the average novelty on the learning goal space of all stages.
4.2 Experimental Results
We analyze the quantitative effectiveness of compared methods. Table 3 shows the experimental results. Note that measurement items (a)–(e), and (f) are described in Sect. 4.1.5.
In Table 3, subject 1 performs the experimental task with looking the learning record in the learning goal space. Subject 2 performs the experimental task with looking the learning record in the uniqueness record graph. Subject 3 and subject 4 perform the experimental task with showing the learning record in the score record graph. Subject 1, subject 3 and subject 4 complete all stages without within the limited time. Subject 2 does not complete stage 5 because he is over the time limit. As shown in Table 3, subject 1 of the learning goal space obtains the most number in four measurement items, the number of the trials (a), the number of the found solutions (b), the number of the path (c) and the number of the learning goals (d) out of six. Subject 2 of the uniqueness record graph obtains the second most number in the same four measurement items out of six. Both subject 3 and subject 4 of the score record graph obtains the fewest number in the same measurement items out of six. Figure 9 shows the line chart of the experimental results in all stages. The linear approximation in the graphs shows the tendency for the collection of data that is obtained from four subjects.

The line charts of the experimental results in all stages
Figure 9 shows the line charts of the experimental results in all stages. The overview of following results, Fig. 9(a), (c) and (d) show that the slope of linear approximation is positive, and Fig. 9(b) shows the slope of linear approximation is positive. These suggest that each subject continues creative learning with progress of the stage.
Figure 9(a) shows the line chart of the rate of obtaining the learning goals. The rate of the learning goals shows the ratio of the number of the learning goals to the number of the found solutions. The lower limit is 0. The upper limit is 1. The slope of the linear approximation in Fig. 9(a) is 0.035. As shown in Fig. 9(a), the rate of obtaining the learning goals of subject 1 prominently increases. The slope of that of subject 1 is 0.11 that is bigger than that of the linear approximation. The slope of that of subject 2 is −0.03 and only negative. This suggests that the subjects other than subject 2 learn to fill the learning goal space.
Figure 9(b) shows the line chart of the rate of finding the same path in all stages. The rate of finding the same path is the ratio of the number of the same path to the number of the found solutions. The slope of the linear approximation in Fig. 9(b) is −0.022. As shown in Fig. 9(b), the rate of finding the same path of subject 1 and subject 2 decrease with progress of stage. The slope of that of subject 1 is −0.049. The slope of that of subject 2 is −0.026. They are smaller than the slope of linear approximation. The slope of that of subject 3 is 0.004 and only positive. This suggests that the subjects other than subject 2 learn the way to find solutions not to find the same path.
Figure 9(c) shows the line chart of the average score per a found solution in all stages. The slope of the linear approximation in Fig. 9(c) is 0.27. As shown in Fig. 9(c), the line chart of the average score of subject 1 is the different from the forms of the other subjects. The slope of that of subject 1 is −0.011 and only negative. This suggests that the subjects other than subject 1 learn the way to find solutions to maximize the score of a solution.
Figure 9(d) shows the average novelty per of the solutions found in each stage. The slope of linear approximation in Fig. 9(d) is 1.3. As shown in Fig. 9(d), the form of line chart of all subjects is similar. This suggests that all subjects learn the way to find solutions to maximize the novelty of a solution.
We describe the result of the questionnaire and the hearing investment after the experimental task. Table 4 shows the overview of the answers in the questionnaire and the hearing investment.
As shown in Table 4, both subject 1 of the learning goal space and subject 2 of the uniqueness record graph consciously decide the way to search solutions, and search the solutions. The both subjects keep concern about the meaning of the compared methods shown to them in the latter stages. On the other hand, two subjects of the score record graph do not have concern about the compared method in the latter stages. From these results, it is supposed that showing the learning goals and feedback of the learning results by the form having some complexity are effective to continuation of the interests of the learner. The detail about it is discussed in the next section.
4.3 Discussions
The Effect of the Learning Goal Space Which Visualizes the Novelty of a Found Solution.
To evaluate the effect of the learning goal space, we discuss whether each subject sets the heuristic learning goals or not, and the way performs the experimental task continuously toward the task accomplishment. As shown in Table 4, subject 1 to whom the novelty of the found solutions by the learning goal space was indirectly presented sets the heuristic learning goals through all stages. Subject 1’s heuristic learning goals are to make clear the position of added score and to fill the blank space in the learning goal space. First we focus on the former heuristic learning goal. As shown in Fig. 9(b), it seems that the subject 1 observes how to add the score on the found solution in both stage 1 and stage 2 by finding the same path. It seems that subject 1 takes random actions with finding the different path with the found paths in both stage 3 and stage 4. Next, we focus on the latter heuristic learning goal. As shown in Fig. 9(a), it seems that the subject 1 tries to fill the blank space in the learning goal space by taking advantage of the learning goal space. In addition, as shown in Fig. 9(c), it seems that the subject 1 is not conscious of obtaining the score. Like subject 1, subject 2 to whom the novelty of the found solutions was presented sets the heuristic learning goals through all stages. As shown in Table 4, the heuristic learning goals are to maximize the score and to maximize the uniqueness. As shown in Fig. 9(c), it seems that subject 2 try to maximize the score in former three stages. As shown in Fig. 9(d), it seems that subject 2 searches the solutions to try to maximize the uniqueness in both stage 4 and stage 5. In contrast to them, other subjects to whom the novelty of the found solutions were not presented set their learning goals differently. Subject 3 sets the heuristic learning goal in former three stages. As shown in Table 4, the heuristic learning goal is to maximize the score. As shown in Fig. 9(c), it seems that subject 3 try to maximize the score. Subject 4 does not set the heuristic learning goal. As shown in Table 4, subject 4 does not set the learning goal. Therefore, it is suggested that the subject who are presented the learning goal space (subject 1) or presented the novelty of the found solution (subject 2) keep finding the solutions according to their learning goals until the final stage in the experiment.
The Choice of the Distance Function.
We discuss whether the Euclidean distance is appropriate to the distance function between the most recent found solutions and a set of the found solutions or not. Lehman speaks of the distance function as domain-dependent measure [5]. In the fields of clustering, the appropriate definition of the distance is generally dependent on presence or absence of correlation between axes of space [1]. If the correlation is large positive or negative, the Mahalanobis distance is appropriate to the distance function. In the case of no correlation, the Euclidean distance is appropriate. In this experiment, the correlation coefficients between two axes of the learning goal space of four subjects are 0.5, 0.5, 0.3, and −0.3 (Overall correlation coefficient is 0.2). The two correlation coefficients out of four have moderate positive correlation, and the other two correlation coefficients have poor correlation. Therefore, the appropriate distance function is the Mahalanobis distance. However, the appropriate distance function is the Euclid distance in this creative learning task because it is necessary to measure the novelty of the found solution in the process incrementally generating the known solution.
Application to the Other Tasks.
In this sub-section, we discuss about the application of the proposed system to the other tasks. We show the necessary conditions for implementing the creative learning support system in the task. The necessary conditions for implementing the creative learning support system in the task are as follows.
-
(i)
quantifiable solution cost
-
(ii)
quantifiable solution quality
-
(iii)
enough solutions
-
(iv)
enough learning sub-goals
(i–ii) is about the axes of the learning goal space. They show that the axes are quantifiable. (iii) shows that it is necessary to plot enough solutions on the learning goal space for the purpose of displaying the learning trace of the learner. (iv) is for the system to generate the task by adding the sub-reward as the sub-goal.
Future Works.
There are several future works. First one is to discuss effects of each support methods of the learner’s reflection for the measurement items. Second, we will define the value of sub-reward. The value of sub-reward \( {\text{V}} \) at sub-reward \( r_{i} \) will be given by
where \( N_{u} \) is the number of the unknown solutions containing the sub-reward \( r_{i} \) and \( N_{s} \) is the number of the solutions containing the sub-reward \( r_{i} \). The reason why the equation shows the value of sub-reward is that the value of sub-reward becomes larger as increasing the number of the findable unknown solutions with the sub-goal as the cue. Third one is to modify the way to add the sub-goal. The current way for setting a sub-goal is on a random transition in the found solution. However it does not intentionally lead to the unknown solution. To realize it, we will select two kinds of transitions, one is with the maximum number of passing in the found solution, the other is the least visited transition nearby the found solution.
5 Conclusions
This paper presented the interactive method for human to creatively learn under the learning support system. We described the way to design the learning support system towards acquiring the creative skill on learning. We proposed the learning goal space which visualizes the distribution of the found solutions on it, then examined the method for supporting the learner’s exploration of the learning goals to present the novelty of a found solution. As the experimental results, each subject continues to learn the way to find solutions creatively. From discussion, on the creative learning task, it is suggested that our supporting method by presenting the novelty of a found solution directly or that of indirectly by the learning goal space support continuously to set the learner’s own learning goals. Future work is to make clear the definition of creative learning, especially the definition of “unusual solutions”.
References
Jain, A.K., Murty, M.N., Flynn, P.J.: Data clustering: a review. ACM Comput. Surv. 31(3), 264–323 (1999). https://doi.org/10.1145/331499.331504
Boden, M.A.: The Creative Mind: Myths and Mechanisms. Routledge, Abingdon (2003)
Frey, C.B., Osborne, M.A.: The future of employment: how susceptible are jobs to computerization? Oxford Martin School Working Paper, no. 7, pp. 1–72 (2013)
Guilford, J.P.: Creativity research: past, present and future. In: Frontiers of Creativity Research: Beyond the Basics, pp. 34–64. Bearly Ltd., Buffalo (1987). http://www.cpsb.com/research/articles/creativity-research/Creativity-Research-Guilford.pdf
Lehman, J.: Evolution through the search for novelty. University of Central Florida, Ph.D. Computer Science (2012)
Leung, K., Chen, T., Chen, G.: Learning goal orientation and creative performance: the differential mediating roles of challenge and enjoyment intrinsic motivations. Asia Pac. J. Manag. 31, 811–834 (2013)
Finke, R.A., Ward, T.B., Smith, S.M.: Creative Cognition: Theory, Research, and Applications. The MIT Press, Cambridge (1992)
Smita, J., Trey, M.: Facilitating continuous learning: review of research on individual learning capabilities and organizational learning environments. In: The Annual Meeting of the AECT International Convention, Louisville (2012). http://www.memphis.edu/icl/idt/clrc/clrc-smita-research.pdf
Okudo, T., Takadama, K., Yamaguchi, T.: Designing the learning goal space for human toward acquiring a creative learning skill. In: Yamamoto, S. (ed.) HIMI 2017. LNCS, vol. 10274, pp. 62–73. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-58524-6_6
Ono, Y.: The study of charisma and transformational leadership in terms of follower’s view. Bus. Rev. Kansai Univ. 58(4), 53–87 (2014). (in Japanese)
Yamaguchi, T., Takemori, K., Tamai, Y., Takadama, K.: Analyzing human’s continuous learning processes with the reflection sub task. J. Commun. Comput. 12(1), 20–27 (2015)
Yamaguchi, T., Tamai, Y., Takadama, K.: Analyzing human’s continuous learning ability with the reflection cost. In: Proceedings of 41st Annual Conference of the IEEE Industrial Electronics Society (IECON 2015), pp. 2920–2925 (2015)
Acknowledgements
This work was supported by JSPS KAKENHI (Grant-in-Aid for Scientific Research ©) Grant Number 16K00317.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Okudo, T., Yamaguchi, T., Takadama, K. (2018). Generating Learning Environments Derived from Found Solutions by Adding Sub-goals Toward the Creative Learning Support. In: Yamamoto, S., Mori, H. (eds) Human Interface and the Management of Information. Information in Applications and Services. HIMI 2018. Lecture Notes in Computer Science(), vol 10905. Springer, Cham. https://doi.org/10.1007/978-3-319-92046-7_28
Download citation
DOI: https://doi.org/10.1007/978-3-319-92046-7_28
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-92045-0
Online ISBN: 978-3-319-92046-7
eBook Packages: Computer ScienceComputer Science (R0)