
Abstract
In essence, Open Data (OD) is the information available in a machine-readable format and without restrictions on the permissions for using or distributing it. Open Data may include textual artifacts, or non-textual, such as images, maps, scientific formulas, and other. The data can be publicized and maintained by different entities, both public and private. The data are often federated, meaning that various data sources are aggregated in data sets at a single “online” location. Despite its power to distribute free knowledge, OD initiatives face some important challenges related to its growth. In this paper, we consider one of them, namely, the business and technical concerns of OD clients that would make them able to utilize Open Data in their enterprise information systems and thus benefit in terms of improvements of their service and products in continuous and sustainable ways. Formally, we describe these concerns by means of high-level requirements and guidelines for development and run-time monitoring of IT-supported business capabilities, which should be able to consume Open Data, as well as able to adjust when the data updates based on a situational change. We illustrated our theoretical proposal by applying it on the service concerning regional roads maintenance in Latvia.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Deriving from diverse sources and immensely growing, digital data is emerging as the essential resource to organizations, enabling them to by enlarging their body of knowledge advance in highly demanding business situations and markets.
Unfortunately, not many of existing digital data are available to organizations to use them. A large proportion belongs to proprietary data owned by specific entities and thus permitted only for their use. Some examples are internally generated documents by the means of data mining and analytics that contain company’s private business information or the information related to its competitive position. Public data is available to the public, but typically, it is not machine-readable, and sometimes obtainable only through explicit requests they may take days to weeks to get responses. Some examples are health-related data, housing data, Wikipedia, labor statistics, and other.
Open Data (OD) is the data available in a machine-readable format, without restrictions on the permissions for using or distributing the information that it contains [1]. Open Data initiatives can be differently organized, starting from providing data at the national (country) level, and further below, to the regional and city levels. Data are often federated, meaning that various sources of data are aggregated to data sets at a single location. Individual sectors may also have their own data with a specific thematic focus, such as transport, utilities, geospatial data and other. Even public and open data may thematically overlap, the main difference is that the latter are provided through well-defined application program interface (API). Around 100 sources of open datasets are available from US states, cities and counties, and over 200 sources are registered from other countries and regions in the world [2].
To have value and impact, Open Data needs to be used. Therefore, the main requirement is making the data available by creating and maintaining OD sources. As with any initiative, this is a remarkable effort requiring resources and technical skills. However, Open Data has a huge potential to, by being refined, transformed and aggregated, provide significant benefits in terms of: transparency of information; public service improvement; innovation and economic value by using the data to improve current, or build new products and services; efficiency by reducing acquisition costs, redundancy and overhead; and interoperability of systems and intermix of data sets.
For successful OD initiatives, it is therefore an essential aspect to make them needed to organizations to facilitate for these entities to, using the data, improve their products and services, and which will in turn lead to even higher demand to Open Data, creating thus a self-sustained growing-need cycle.
Today’s organizations operate in highly competitive and dynamically changing situational environments. Having a continuous access to relevant, accurate and usable data is therefore highly important for organizations, but in turn, it leads also to the requirements to improve their business capabilities to be able to benefit from new and often changed and updated data [3].
One methodological approach for dealing with dynamic business capabilities implemented by the means of information systems is Capability Driven Development, CDD [4]. It is a methodology developed to support continuous delivery of business capabilities by being able to capture and take advantage of changes in business context. The success of a business and IS infrastructure following CDD, is therefore highly tight to the ability for continuously and entirely fetching the relevant surrounding business context and where Open Data plays a highly significant role as a transparent, structured, accurate, and machine-readable information source.
The goal of this paper is to, taking the OD client perspective, discuss and exemplify overall design and run-time requirements for provisioning and using Open Data by means of dynamic business capabilities.
The rest of the paper is organized as follows. Section 2 outlines a background to the Open Data initiative and to the Capability Driven Development approach. Section 3 presents the requirements for use of Open Data by IT-supported business capabilities and their application specifically in a CDD-enabled client environment. Section 4 illustrates the proposal on a real business case concerning regional roads maintenance. A discussion and concluding remarks are given in Sect. 5.
2 Background
2.1 About Open Data
Open Data is data that can be freely used, re-used and redistributed by anyone. In this way, knowledge is becoming open and free to access, use, modify, and share it. According to [5], there are two dimensions of data openness:
-
The data must be legally open, meaning they must be placed in the public domain or under liberal terms of use with minimal restrictions.
-
The data must be technically open, meaning they must be published in electronic formats that are machine readable and non-proprietary, so that anyone can access and use the data using common, freely available software tools. Data must also be publicly available and accessible on a server, without password or firewall restrictions.
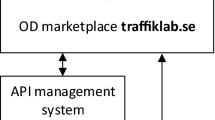
To make Open Data easier to find, most initiatives create and manage Open Data catalogs. The core technology model of the data catalog is shown in Fig. 1:

A technology model of an Open Data catalog [6]
The data catalog is a list of datasets available in an Open Data initiative. Its essential services include searching, metadata, visualization, and access to the datasets themselves through well-defined API services. An online platform is used to provide a front-end for users to access all resources available under an Open Data initiative. Aside from the data catalog, the platform includes the description of API services, online forum for questions, technical support and feedback, background materials and other. Some more advanced alternatives of the model presented in Fig. 1 comprise: (a) separation of the File Server to use a Cloud infrastructure and (b) decentralization of the data catalog to the contributing data participants (such as ministries, for example).
2.2 Capability-Driven Approach
From the business perspective, a capability describes what the business does that creates value for customers [8]. It represents a design from a result-based perspective including various dimensions including organization’s values, goals, processes, people, and resources. In brief, the emergence of the use of the capability notion seems having the following motivations:
-
In the context of business planning, capability is becoming recognized as a fundamental component to describe what a core business does and, in particular, as an ability for delivering value, beneath the business strategy [7];
-
Capability supports configurability of operations on a higher level than services and process, and according to changes in operational business context [4, 8].
The Capability Driven Development (CDD) approach [4] has developed an integrated methodology for context-aware business and IT solutions. It consists of a meta-model and guidelines for the way of working. The areas of modeling as part of CDD are Enterprise Modeling (EM), context modeling, variability modeling, adjustment algorithms and patterns for capturing best practices. The meta-model is implemented in a technical environment to enable the support for the methodology by consisting of the following key components presented in Fig. 2:

Components of the CDD environment.
Capability Design Tool (CDT) is a graphical modeling tool for supporting the design of capability elements. Capability Navigation Application (CNA) is an application that makes use of the models (capability designs) created in the CDT to monitor the capability context by receiving the values of measurable property (MP in Fig. 2) and handle run-time capability adjustments. Capability Context Platform (CCP) is a component for distributing context data to the CNA. Capability Delivery Application (CDA) represents the business applications that are used to support the capability delivery. This can be a custom-made system, or a configured standard system such as SAP ERP. The CNA communicates, or configures the CDA to adjust for changing data contexts during capability design and delivery. Monitoring of defined KPIs facilitate capability refinement and pattern updating.
3 Results
Many organizations are still reluctant to use Open Data due to a lack of information on how to find the data, as well as because some data are not available in a fully machine-readable form, not up-to-date, or not offering rich or efficient API [11]. On the other side, organizations should know which data they need for fulfilling their business goals, as well as they should have IS capable to connect to Open Data and download it whenever the data is changed. In Table 1 below, we have summarized the requirements for managing Open Data from the provider and the client perspectives:
As a brief illustration of the outlined requirements, we consider the Swedish OD catalog containing real estate data “Booli bostads” [9]. Booli provides the data on the apartments for sale, in a given area, such as: all apartments/houses for sale in a particular city, all real estates for sale near a geographic coordinate, including prices. Using the RESTful service technology, the API gives an opportunity to access real estates data and thus integrate with third-party applications. The data provided include the number of offered real estates, the number of offered real estates in an area, prices, and other.
Depending on their goals, different clients can use the Booli OD differently. For real-estate brokers, one important use needs accurate data on the number of offered estates on a location of interest (context), and whenever that number drops below a certain value, the broker may activate activities (capability) to increase again that number. As another example, if the prices on the market are too high, the broker may activate “advertising” capability to increase the number of apartments for sale. Finally, the Booli OD may be used by the broker to easy create periodical company analytics/reports to make future business plans/strategy.
Application in CDD Design and Run-Time
First capabilities need to be designed. This can be carried out according to the capability design method component presented in [10] consisting of steps such as goal and KPI modeling, context modeling, capability adjustment modeling, as well as, if needed pattern modeling. This process is primarily supported by the capability design tool (CDT, see Fig. 2), but also the context platform is involved in terms of providing available context elements that are related to the capability. With respect to the use of Open Data a particular task that needs to be supported is finding relevant open data that can be linked as measurable properties on the basis of which context element calculations can be defined to specify context elements. Table 2 summarizes the main activities of capability design based on Open Data.
At the run-time, the status of business context and related KPIs are continuously monitored. When a KPI decreases below a desired value, utilization of capabilities is adjusted by invocation of other capabilities from the repository. Table 3 summarizes open-data related capability run-time activities:
4 Example Case - Regional Road Maintenance Company
To illustrate the principles of Open Data use in capability management we have developed a demo case for a regional Road Maintenance Company (RMC) company operating in Latvia. The main capability of RMC is that of providing proactive road maintenance. The capability is delivered in winter season and it primarily consists of deicing services such as snow plowing as well as removal of ice and frost. These services are to be carried out in varying weather conditions, which, for the purpose of this case, are considered as the business context. The top goal for the RMC business service provided is refined into three sub-goals, namely (1.1) to prevent road icing, (1.2) to minimize road maintenance costs, and (1.3) minimize times for transporting maintenance vehicles (Fig. 3).
Road conditions as well as the actual weather data and forecasts are seen as the context elements relevant to the adjustments of the proactive road maintenance capability. In this respect, the following open data providers have been identified:
-
Latvian State Roads (LSR) – a Latvian government agency which owns weather stations that have been installed along the major Latvian roads,
-
Estonian Road Administration (ERA) – an Estonian government agency that owns weather stations in Estonia,
-
Twitter – a social network containing user feedback that is relevant for the use case.
Fig. 3. 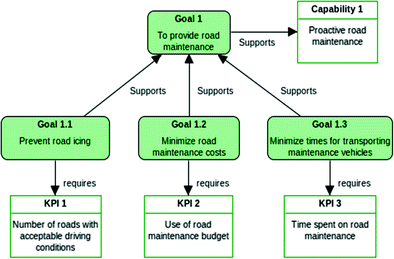
A fragment of Goals Model of RMC showing goals related to the proactive road maintenance capability

Both the LSR and the ERA provides access to their open data upon contacting them via email. In order to access a live feed of tweets a developer needs to register an application on dev.twitter.com. The data in LSR and ERA information systems is provided as HTML content. In order to extract the required information, the developer has to implement a bot that opens the web site and extracts the needed information from the Document Object Model (e.g. using a website tasting framework like CasperJS).
Twitter provides a structured tweet object that contains the potentially useful information about the author of the tweet, its content and location properties. The LSR and the ERA provide current road conditions and prediction for the next hours. It has been discovered that the prediction is slightly different in both data sources; also, there are some road or weather-related data that are made available only by one data provider (see LSR data in Fig. 4 and ERA prediction in Fig. 5).

LSR road temperature prediction.

ERA road temperature prediction.
Twitter API can be searched for the tweets containing geolocation information and keywords indicating hazardous driving conditions. The model containing context and adjustment is given in Fig. 6.

Adjustment and context model
A total of 8 measurable properties are used in a Driving conditions calculation (Context: Calculation 1) for calculating the value of the Driving conditions (Context: Element 1). Factor weights, which are formalized as an Adjustment constant, are used to specify the importance of each measurable property. Factor weights can be altered during run-time by change the corresponding Adjustment constant in the CNA. The value of the Driving conditions context element is used for triggering the Perform road maintenance Adjustment that notifies the operator that road maintenance operations should be performed.
Demo case of the RMC is summarized in Fig. 7. Driving conditions related data from ERA and LSR is retrieved by custom data broker and is then sent to the CCP. The data from Twitter is retrieved by the CCP itself since Twitter has well defined API and data models. All data is integrated by the CCP and then sent to the CNA. Upon receiving new measurable property values from CCP, CNA recalculates the value of the corresponding context element, which triggers execution of the Perform road maintenance Adjustment. The CDA of the RMC has an API that Adjustment utilizes to notify the operator that a road maintenance operation must be performed on a certain road due to a high risk of icing.

Summary of the demo case
If during the run-time it has been discovered that a certain data provider or road-condition factor has greater impact on the actual road conditions, factor weights can be altered without re-deploying or restarting the capability in CNA. KPI values received from the CDA can also indicate a necessity to adjust a value of the Adjustment constant. If new Measurable properties or new data providers are identified design level changes in CDT and re-deployment of the capability are required. Adding new measurable properties still wouldn’t require any changes in the Adjustment itself since context is interpreted using the Context Calculation – Driving conditions calculation.
5 Discussion, Conclusions and Future Work
In this paper we have analyzed how organizations could improve their business capabilities by taking advantage of Open Data initiatives. We have defined and further exemplified design and run-time requirements and guidelines for provisioning using Open Data by means of dynamic business capabilities. The proposal is specifically concerning Capability Driven Development (CDD) enabled clients, because the CDD methodology aimed to support continuous delivery of business capabilities by being able to capture business context – in this case data, as well as to take advantage of changes in business context, i.e. data.
The motivation behind this study lies in the fact that the success of today’s organizations highly rely to their ability for gathering different data from their surroundings, and where the requirements for data accuracy, amount and the pace of processing are constantly increasing. Yet, despite its evident ability for distributing free information, an essential aspect for successful OD initiatives is to make them even more available to business organizations by fulfilling the requirements emphasized in Sect. 3. As well the IS solutions of the organizations need to be empowered with the ability to interoperate with OD sources and API as presented with the capability design and run-time guidelines. This in-turn will lead to a self-sustained growing-need cycle for Open Data. We illustrated our theoretical proposal by applying it on the service concerning regional roads maintenance in Latvia, which acts and adjust the maintenance tasks according Open Data and its real-time updates.
For the near future work, we plan to elaborate the functionality of a Data Broker, which, as illustrated in Fig. 7 could be used by business organizations to provide all the tasks needed to make raw/original Open Data using a set of transformations and API adapters compliant with the internal data of the organizations.
References
Handbook on Open Data. http://opendatahandbook.org/guide/en/what-is-open-data/. Accessed 12 Mar 2018
Data.gov. https://www.data.gov/open-gov/. Accessed 12 Mar 2018
Zeleti, F.A., Ojo, A.: Capability matrix for open data. In: Camarinha-Matos, L.M., Afsarmanesh, H. (eds.) PRO-VE 2014. IAICT, vol. 434, pp. 498–509. Springer, Heidelberg (2014). https://doi.org/10.1007/978-3-662-44745-1_50
Bērziša, S., et al.: Capability driven development: an approach to designing digital enterprises. Bus. Inf. Syst. Eng. (BISE) 57(1) (2015). https://doi.org/10.1007/s12599-014-0362-0
The World Bank. Data, Open Data Essentials. http://opendatatoolkit.worldbank.org/en/essentials.html. Accessed 12 Mar 2018
The World Bank. Data, Technology Options. http://opendatatoolkit.worldbank.org/en/technology.html. Accessed 03 Mar 2018
Ulrich, W., Rosen, M.: The business capability map: building a foundation for business/IT Alignment. Cutter Consortium for Business and Enterprise Architecture. http://www.cutter.com/content-and-analysis/resource-centers/enterprise-architecture/sample-our-research/ea110504.html. Accessed 28 Feb 2017
Zdravkovic, J., Stirna, J., Grabis, J.: A comparative analysis of using the capability notion for congruent business- and information systems engineering. Complex Syst. Inf. Model. Q. CSIMQ (10), 1–20 (2017). https://doi.org/10.7250/csimq.2017-10.01
OPENDATA.se. http://www.opendata.se/2010/05/booli-api.html. Accessed 12 Mar 2018
Grabis, J., Henkel, M., Jokste, L., Kampars, J., Koç, H., Sandkuhl, K., Stamer, D., Stirna, J., Valverde F., Zdravkovic, J.: Deliverable 5.3: the final version of capability driven development methodology. FP7 Project 611351 CaaS – Capability as a Service in digital enterprises, Stockholm University, p. 266 (2016) https://doi.org/10.13140/RG.2.2.35862.34889
Open Data Barometer. Global Report. https://opendatabarometer.org/4thedition/report/. Accessed 13 Mar 2018
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Zdravkovic, J., Kampars, J., Stirna, J. (2018). Using Open Data to Support Organizational Capabilities in Dynamic Business Contexts. In: Matulevičius, R., Dijkman, R. (eds) Advanced Information Systems Engineering Workshops. CAiSE 2018. Lecture Notes in Business Information Processing, vol 316. Springer, Cham. https://doi.org/10.1007/978-3-319-92898-2_3
Download citation
DOI: https://doi.org/10.1007/978-3-319-92898-2_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-92897-5
Online ISBN: 978-3-319-92898-2
eBook Packages: Computer ScienceComputer Science (R0)