
Abstract
Cloud computing applications are expected to guarantee the service performance which is determined by the Service Level Agreement (SLA) between cloud owner and client. While satisfying SLA, Virtual Machines (VMs) may be consolidated based on their utilization in order to balance the load or optimize energy efficiency of physical resources. Since, these physical resources are prone to system failure, any optimization approach should consider the probability of a failure on a physical resource and orchestrate the VMs over the physical plane accordingly. Otherwise, it is possible to experience unfavorable results such as numerous redundant application migrations and consolidations of VMs that may easily cause in SLA violations. In this paper, a novel approach is proposed to reduce energy consumption and number of application migration without violating SLA while considering the fault tolerance of the cloud system in the face of physical resource failures. Simulation results show that proposed model reduce energy consumption by approximately 37% and number of application migration by approximately 9%. Besides, in case of faults the increase of energy consumption is less than 11% when the proposed approach is used.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Cloud computing has many trending features such as on-demand services, virtualization and automatic scaling which leads remarkable increase in cloud usage. Data centers that host major cloud services contain enormous servers which cause tremendously high energy consumption levels [1]. Along with the increase in the number of cloud users and powerful data centers, energy consumption of cloud systems gained significant importance [2, 3] over the last decade.
Growing importance of energy efficiency in cloud systems caused recent academic studies to concentrate on energy efficiency on cloud systems as well. In this manner, virtual machine (VM) consolidation is a widely used method to promote more efficient energy consumption and utilization. On the other hand, in cloud computing, service performance is leveraged mostly with automatic scaling that may frequently led over-provisioned infrastructure and high energy consumption.
Automatic scaling can be achieved in terms of vertical scaling and horizontal scaling. In this paper, horizontal scaling is focused where VM creation and VM consolidation policies becomes important aspects of energy consumption trade-offs.
VM consolidation can be used as a means to reduce energy consumption and optimize the VM utilization in horizontal scaling process. Consolidating applications in multiple VMs into a single VM may cause high utilization and reduced fault tolerance. Fault tolerance can be achieved either using a reactive approach or a proactive approach. Reactive fault tolerance policies aim to reduce the damage of failures after the failure whereas, proactive fault tolerance policies try to predict the faults and reacts before the failure [4].
In modern cloud systems, three aspects; fault tolerance, energy efficiency and performance requirements form a trade-off. High performance and fault tolerant cloud environments require horizontal scaling, and energy efficient cloud systems need VM consolidation for preventing unnecessary energy consumption. An approach is necessary to keep fault tolerance, energy efficiency and performance requirements in an optimized balance.
In this paper, a reactive fault tolerance approach is proposed for cloud environments which try to minimize the energy consumption by using VM consolidation. There are three different cases in the study; no-consolidation, consolidation by threshold and consolidation according to fault tolerant consolidation algorithm (FTC). No-consolidation case is presented as the control experiment for the proposed approaches; when a new VM is created it will not be consolidated even if it runs no applications. In the second case, consolidation by threshold, VMs would be consolidated when their utilization is less then defined threshold value. In the last case, FTC algorithm is used to accept or reject consolidation by threshold requests using the measure defined latter in the paper.
Major contributions of this paper are:
-
1.
A novel measure to evaluate fault tolerance vulnerabilities.
-
2.
An algorithm (FTC) to orchestrate energy efficiency and fault tolerance together.
-
3.
Simulating application placement, VM consolidation and fault tolerance together to analyze trade-offs among them.
-
4.
Reduced number of application migration and energy consumption in horizontal scaling.
The rest of this paper is organized as follows. The related work in this research field is presented in Sect. 2. Then, the simulation system features and structural details are described in Sect. 3. In Sect. 4, experiment details and results are presented, finally, followed by conclusion and planned future work in the last section.
2 Related Work
VM consolidation has become a significant technique for data center energy and resource management. For consolidation of VM several methods are carried on already such as Ant Colony Optimization, K-Nearest Neighbor, Greedy Heuristics [5,6,7]. On the other hand, VM consolidation requires live migration of the applications which are hosted by the corresponding VM [8]. Besides in [9], authors analyzed CO\(_2\) emissions of the data centers by considering their energy consumption in network level. In [3], the authors are proposed a model which migrates highly utilized virtual machines to the low utilized hosts while keeping the energy efficiency of the data center by realizing firefly algorithm. However, these techniques do not consider the fault toleration of the VMs.
In the real world, cloud systems could encounter system failures by their dynamic nature [10] which must be prevented to achieve guaranteed Quality of Service (QoS). Hence, various fault tolerant cloud environment approaches are investigated. In [11], fault occurrences are more similar to Weibull Distribution (WD).
The authors proposed an active replication model to provide fault tolerance in [12]. Then, in [13], the replication approach is further enhanced by using byzantine fault tolerance gain to optimize the overall cost. However, all of these studies require user experience and knowledge for configuration and application preparation phase. Since most of the approaches utilize VM level live-migration among data centers to create fault tolerant cloud environment, the techniques represented in [14] distinguishes these approaches by using application level live-migration.
In [15], the authors emphases the gap of fault tolerant, energy efficient cloud environment approaches by using VM consolidation.
3 Simulation System Structure of the Proposed Approach
Simulation softwareFootnote 1 used in this study is developed in Java 8 and tested on PC which has Intel Core i7 7700HQ @ 2.80 GHz, 16 GB DDR4-2400, 4 GB NVidia GTX1050, on a Windows 10 64-bit environment. Typically, a simulation run takes 15 s. The application creation time and resource usage data are generated randomly by using uniform distribution. The simulation framework works for only one physical machine and all the VMs are created and consolidated on the same physical machine.

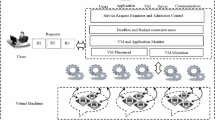
Simulation flow chart
The main structure of the simulation is shown in Fig. 1. The simulation consists of two main phases; application assignment of VM and VM consolidation on physical machine. The application placement [16] is a divergent and huge area for covering in this paper hence Round Robin algorithm is used to ease implementation of this part. So, it is same for all three test cases (no-consolidation, consolidation by threshold, consolidation by FTC). The second phase of the simulation is the main focus of enhancement.
In the first phase, basically, the simulation engine checks the simulation end period of time and continue if it has more period to work. Then generate certain number of applications according to Gaussian Distribution and search for available VM if it is able to find the VM then assign corresponding application to VM and return to the simulation counter. If it cannot find any available VM for assignment, then it will create a new VM and assign application to currently created VM.
In the second phase, after all application assignments are completed on corresponding period, simulation framework checks the VMs utilization if their utilization is less then defined threshold. Depending on that, it will consolidate VM on consolidation by threshold case. But in consolidation by FTC case it sends a consolidation request to FTC algorithm and the algorithm determines the request is accepted or rejected. On no consolidation test case this step will be skipped because in that scenario there is no consolidation checks.
3.1 Fault Tolerant Consolidation Algorithm
The FTC Algorithm works on every period of simulation lifetime. As shown in Algorithm 1, it checks every VMs running on the physical machine and compare their utilization with the defined threshold value.

After the threshold control on line 3, findByPolicy function works to find guaranteed VM according to its policy value which can be defined as minimum utilized, median utilized or maximum utilized. The effects of these policies are also demonstrated on the Sect. 4. In line 5, isMigratable function checks all VMs except VM which has less utilization than threshold and is selected by previous line to guarantee all applications of the selected VM could be migrated to the rest of VMs.
In consolidate function of the algorithm, the applications which are hosted by the VM should be migrated to other VMs before consolidation process of the VM. However, live-migration of applications causes overhead on resources consumption of the VMs which may easily result in higher energy consumption by 10% [17]. Therefore, the key factor of the consolidation is to reduce number of application migration to reduce energy consumption and it is not significant to migration application to which VM.
In general, the main purpose of the algorithm is to prevent new VM creation when a failure occurrence on any of the VMs. Therefore, it determines consolidation request approval by checking the other VMs are capable of to manage all its applications. If they are capable then the algorithm will accept the consolidation request and VM will be consolidated. Otherwise, the request will be rejected and consolidation would not be happened.
Energy consumption of VM\(_i\) is calculated in Eq. 1.
where variable k represents idle energy consumption, a denotes for application and m is the total number of applications hosted by VM\(_i\). cpu and memory functions return the memory and CPU consumption of a\(_j\). The equation sums the idle energy consumption and all utilized resources (CPU and Memory in case of suggested model) which is used by applications.
In Eq. 2, total energy consumption is calculated by using VM energy consumption and application migration’ energy overhead.
where variable s(p) represents the number of the application migration among the VMs on period p.
4 Simulation Results
In the simulation, energy consumption and number of the application migrations are compared for three different cases (no-consolidation, consolidation by threshold and FTC) which are mentioned in Sect. 1.

Application generation distribution
Number of generated applications are shown in Fig. 2. To test model on a fluctuating application generated environment several Gaussian Distributions are overlapped independently from fault occurrence distribution.
In the first experiment, energy consumption on various threshold values are checked for all cases. The threshold values are defined as utilization percentage of the VM and shown in Table 1. In the other experiments, number of application migrations and energy consumption changes on simulation time are analyzed by using a constant 50% threshold value.
Defined simulation variables are shown in Table 1. For resources types CPU and Memory are used and application resources consumption are selected from uniform distribution on the interval of 0.1 and 0.3. The variables are defined according to Google Cluster Data [18, 19]. The VM capacities defined as 20 core CPU and normalized 20 units of memory. Faults occurrences are gathered from Weibull Distribution and it happens 10 times in a simulation lifetime. The simulation runs for 1000 period to collect results.

Energy consumption comparison for different threshold values
In Fig. 3, total energy consumption of the simulation lifetime has calculated by using Eq. 2 for different threshold values. In No-consolidation case, model do not consolidate any VM and if it is necessary it creates new one so energy consumption values are higher than other two case. In normal conditions, the threshold value changes would not affect no-consolidation energy consumption but in this simulation model, faulty VM is selected randomly so it can be increase when occurred on VMs with high utilization or vice-versa. In Consolidation case, keeping the threshold value low gives the advantage of reduced energy consumption. Hence, consolidation of VMs with high utilization causes costly application migrations because of having more number of applications also fault occurrences affect Consolidation case worse than the other cases. The FTC model is not affected from threshold value changes by the advantage of its rejection capability. But its slightly more robust on higher threshold values. Instead of consolidating low threshold VMs by considering fault possibility, consolidation of VMs with high threshold results the better energy efficiency. In results, the FTC approach has reduced energy consumption by 30% to 50%.

Threshold value is selected as 50%
In Fig. 4, number of application migration and energy consumption of whole system are compared for all three test cases. the FTC algorithm has the minimum number of application migration and also 50% less energy consumption according to consolidation by threshold case. When an error occurred in all cases, applications are migrated from faulty VM to other VMs which causes to increase of energy consumption on fault occurrence times of the simulation. The FTC model degrades impacts of fault occurrence and prevents the unnecessary application migrations for fault tolerance so it keeps energy consumption more stabilized.

Max, Min, Median FTC Algorithm policies on 50% threshold value
In Fig. 5, three different guaranteed VM finder policies are compared; maximum, minimum and median utilized as mentioned in Sect. 3. The results show that if it is selected as minimum it will converge to the consolidation case, otherwise it is selected as two times maximum it will converge to the no-consolidation case. The best results are found when the maximum utilized VM is selected and other VMs are checked by hosting the maximum utilized VM applications.
5 Conclusion and Future Works
In this paper, a novel approach is proposed to satisfy fault tolerance and energy efficiency together. Hence, two different experiment are created to prove FTC model and its advantages. Energy consumption and number of application migration results are compared under various threshold values. The experiments show that with the FTC approach the energy consumption ca be reduced by 30% to 50% and number of application migrations can be reduced by %10 in a faulty cloud environment. The proposed approach also reduces the impact of faults on VMs.
In the future, the proposed approach is planned to be validated using different real-world data sets. An additional contribution to proposed approach can be to adapt machine learning techniques in order to perform time series analysis and smart prediction of future fluctuations on VM resource demands.
References
Ghribi, C., Hadji, M., Zeghlache, D.: Energy efficient VM scheduling for cloud data centers: exact allocation and migration algorithms. In: 2013 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing, pp. 671–678, May 2013. https://doi.org/10.1109/CCGrid.2013.89
Rodero, I., et al.: Energy-efficient thermal-aware autonomic management of virtualized HPC cloud infrastructure. J. Grid Comput. 10(3), 447–473 (2012). https://doi.org/10.1007/s10723-012-9219-2. ISSN 1572–9184
Kansal, N.J., Chana, I.: Energy-aware virtual machine migration for cloud computing - a firey optimization approach. J. Grid Comput. 14(2), 327–345 (2016). https://doi.org/10.1007/s10723-016-9364-0. ISSN 1572–9184
Bala, A., Chana, I.: Fault tolerance-challenges, techniques and implementation in cloud computing. 9, January 2012
Farahnakian, F., et al.: Using Ant colony system to consolidate VMs for green cloud computing. IEEE Trans. Serv. Comput. 8(2), 187–198 (2015). https://doi.org/10.1109/TSC.2014.2382555. ISSN 1939–1374
Farahnakian, F., et al.: Utilization prediction aware VM consolidation approach for green cloud computing. In: 2015 IEEE 8th International Conference on Cloud Computing, pp. 381–388, June 2015. https://doi.org/10.1109/CLOUD.2015.58
Ferdaus, M.H., Murshed, M., Calheiros, R.N., Buyya, R.: Virtual machine consolidation in cloud data centers using ACO metaheuristic. In: Silva, F., Dutra, I., Santos Costa, V. (eds.) Euro-Par 2014. LNCS, vol. 8632, pp. 306–317. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-09873-9_26
Ferdaus, M.H., et al.: Multi-objective, Decentralized Dynamic Virtual Machine Consolidation using ACO Metaheuristic in Computing Clouds. In: CoRR abs/1706.06646 (2017). arXiv: 1706.06646
Cavdar, D., Alagoz, F.: A survey of research on greening data centers. In: 2012 IEEE Global Communications Conference (GLOBECOM), pp. 3237–3242, December 2012. https://doi.org/10.1109/GLOCOM.2012.6503613
Amin, Z., Singh, H., Sethi, N.: Review on Fault tolerance techniques in cloud computing. Int. J. Comput. Appl. 116(18), 11–17 (2015)
Liu, J., et al.: A Weibull distribution accrual failure detector for cloud computing. PLOS ONE 12(3), 1–16 (2017). https://doi.org/10.1371/journal.pone.0173666
Santos, G.T., Lung, L.C., Montez, C.: FTWeb: a fault tolerant infrastructure for web services. In: Ninth IEEE International EDOC Enterprise Computing Conference (EDOC 2005), pp. 95–105, September 2005. https://doi.org/10.1109/EDOC.2005.15
Wood, T., et al.: ZZ and the art of practical BFT execution. In: Proceedings of the Sixth Conference on Computer Systems, EuroSys 2011, pp. 123–138. ACM, Salzburg (2011). https://doi.org/10.1145/1966445.1966457
Cully, B., et al.: Remus: high availability via asynchronous virtual machine replication. In: Proceedings of the 5th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2008, pp. 161–174. USENIX Association, San Francisco (2008). http://dl.acm.org/citation.cfm?id=1387589.1387601
More, N.S., Ingle, R.B.: Challenges in green computing for energy saving techniques. In: 2017 International Conference on Emerging Trends Innovation in ICT (ICEI), pp. 73–76, February 2017. https://doi.org/10.1109/ETIICT.2017.7977013
Seçinti, C., Ovatman, T.: On optimizing resource allocation and application placement costs in cloud systems. In: Proceedings of the 4th International Conference on Cloud Computing and Services Science, CLOSER 2014, pp. 535–542. SCITEPRESS - Science and Technology Publications, LDA, Barcelona, (2014). https://doi.org/10.5220/0004849605350542. ISBN: 978-989-758-019-2
Voorsluys, W., Broberg, J., Venugopal, S., Buyya, R.: Cost of virtual machine live migration in clouds: a performance evaluation. In: Jaatun, M.G., Zhao, G., Rong, C. (eds.) CloudCom 2009. LNCS, vol. 5931, pp. 254–265. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-10665-1_23
Reiss, C., Wilkes, J., Hellerstein, J.L.: Google cluster-usage traces: format + schema. Technical report, Google Inc., Mountain View, November 2011. Version 2.1. https://github.com/google/cluster-data. Accessed 17 Nov 2014
Wilkes, J.: More Google cluster data. Google research blog. http://googleresearch.blogspot.com/2011/11/more-google-cluster-data.html, November 2011
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Secinti, C., Ovatman, T. (2018). Fault Tolerant VM Consolidation for Energy-Efficient Cloud Environments. In: Luo, M., Zhang, LJ. (eds) Cloud Computing – CLOUD 2018. CLOUD 2018. Lecture Notes in Computer Science(), vol 10967. Springer, Cham. https://doi.org/10.1007/978-3-319-94295-7_22
Download citation
DOI: https://doi.org/10.1007/978-3-319-94295-7_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-94294-0
Online ISBN: 978-3-319-94295-7
eBook Packages: Computer ScienceComputer Science (R0)