
Abstract
Deep Packet Inspection (DPI) is a basic monitoring step for intrusion detection and prevention, where the sequences of packed packets are to be unpacked according to the layered network structure. DPI is performed against overwhelming network packet streams. By nature, network packet data is big data of real-time streaming. The DPI big data analysis, however are extremely expensive, likely to generate false positives, and less adaptive to previously unknown attacks. This paper presents a novel machine learning approach to multithreaded analysis for network traffic streams. The contribution of this paper includes (1) real-time packet data analysis, (2) learning the likelihood of trusted and untrusted packet sequences, and (3) improvement of adaptive detection against previous unknown intrusive attacks.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
- Network traffic packet streams
- Multithreading data analysis
- Intrusion detection and prevention
- Genetic algorithmic fitness
1 Introduction
Deep Packet Inspection (DPI) is a basic monitoring step in intrusion detection systems (IDSs), where the sequences of packed packets are to be unpacked according to the layered network structure. For example, IDSs aim at unpacking network packets for the IP or port number (which was packed at the network layer [1]) of source and destination computers to identify potential threats. They also unpack the transport layer protocols, such as TCP, UDP, TLS, HTTP, etc. to identify the session connection of malicious attacks. At the application layer, part of session data pieces (e.g., login and password credentials) are posed to access an application. In addition to the network structure data, payload contents may be fed into an application as needed. Both header data about network structures and payload contents will then be analyzed for the verification all the way up in the application layer [2,3,4].
DPI has been increasingly employed and visualized in IDSs. One of the widely used software packages is Wireshark [5]. Although Wireshark provides the filtering expression, it does not provide any additional analytic capabilities for massive real-time streaming data process. Automatic network packet filtering processes are embedded in routers and firewalls, which are either hardware devices or software packages. They determine whether network packets are accepted to proceed or deny. IP’s are used to specify the block rules, and block rules are determined based on country code [6]. Once known, the state of active connections may or may not be stored to be used by a next step of DPI processes. We call them stateful inspection or stateless inspection depending on availability of the connection states. In stateful or stateless packet traffic inspection, denial or permission lead to non-negligible false-positives and false-negatives. Consider the following motivating examples:
Motivating Example 1 (Real-time vulnerability detection of packet streams).
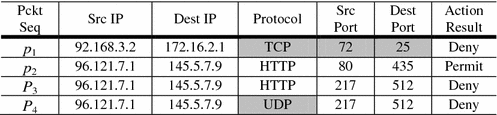
Fast incoming network packets are unpacked to identify their IP’s. Network packets are unpacked at once for all network (session, transportation and network) layers, and the decision is made based on a rule set. Figure 1 illustrates this.
-
Although denial of an IP can be made way before unpacking port numbers or session protocols, network equipment unpacks network packets for all layers of header data first, then followed by decision rules that are executed against unpacked header data. Note that the cells contain the data that can be captured by typical software packages, e.g., Wireshark [5], and IDSs determine the decision, which appears in the last column of the table below. The packet header data in the cells shaded are the data that does not need to be captured since the data in the cells with no shade are known to be enough for decision making. Consider the following packet sequences, which are all incoming.


Network packet analysis, consisting of (1) packet unpacking, and (2) access control. Note that all packet header data are unpacked at once and never to be referenced by applications.
Suppose that the rule set is defined in a firewall system: All packets requesting for HTTP protocol are permitted except the TCP request from 92.168.3.2.
Rule no | Direction | Src IP | Dest IP | Protocol | Src port | Dest port | Decision |
|---|---|---|---|---|---|---|---|
1 | In | 92.168.3.2 | 172.16.2.1 | Any | Any | Any | Deny |
2 | In | 96.121.7.1 | Any | UDP | Any | Any | Deny |
3 | In | Any | Any | HTTP | Any | 435 | Permit |
According to the ruleset above (particularly Rule No 1), p1 (or Packet Sequence 1) does not need to unpack session protocols and ports (highlighted) since Src IP is prohibited. p4 does not need to unpack the port (highlighted) since IPs and protocols are known to be vulnerable due to Rule No 1. p2 and p3 needs to unpack for all header data to permit due to unless otherwise its vulnerability cannot be detected. p2 is permitted according to Rule No 3, while p3 is denied according to Rule No 4. It is desired that if a vulnerability of packet is known, unpacking should stop.
Motivating Example 2 (Once attacked, more often unrecoverable).
In this new technological era, once an infrastructure is attacked, its damage will be disastrous and its impacts will become paramount, and may be irrecoverable. Packets should be denied in advance if its vulnerability is highly likely. An early decision over real-time network packet streams is very hard, but it is undoubtedly an imperative task.
-
Consider a packet, which is allowed to move into the systems all the way to an application system, such as a database storage through a web server. As illustrated in p2 and p5, they are continuous attempts: p2 was permitted by network equipment, but p5 was denied when the packet is to intrude into a database as a database administrator (DBA). Consider the following table, which illustrates packet sequences.

This table can be simplified as follows. I, T, P, S and R denote IP, Port, Protocol, Session data into a host server and session Role to an application software, respectively. Subscripts s, d denote source and destination, respectively. If subscript numbers are the same, they denote the same value. For example, I1s and I1d are the same IP: one for source and the other for destination.
$$ \begin{aligned} & P_{1}:I_{{1{\text{s}}}} ,I_{{1{\text{d}}}} \\ & p_{2}:I_{{2{\text{s}}}} ,I_{{2{\text{s}}}} ,T_{{1{\text{s}}}} ,T_{{2{\text{d}}}} ,P_{1} \\ & p_{3}:I_{{2{\text{s}}}} ,I_{{2{\text{s}}}} ,T_{{3{\text{s}}}} ,T_{{4{\text{d}}}} ,P_{1} \\ & p_{4}:I_{{2{\text{s}}}} ,I_{{2{\text{s}}}} ,T_{{3{\text{s}}}} ,T_{{4{\text{d}}}} \\ & p_{5}:I_{{2{\text{s}}}} ,I_{{2{\text{s}}}} ,T_{{1{\text{s}}}} ,T_{{2{\text{d}}}} ,P_{1} ,S_{1} ,R_{1} \\ \end{aligned} $$(1)If it is learned that p5 is vulnerable and likely eventually be denied, a high tech solution will be able to deny p2 in advance. This is illustrated in Fig. 1. No header data states of packets are propagated from network equipment to webservers and all the way to the backend storage, although the data states are useful to access control and authorization at backend servers.

To overcome the difficult task and to improve network monitoring systems as illustrated in the motivating examples, this paper proposes the following approaches:
-
Multithreading Packet Analysis. As illustrated in Motivating Example 1, real-time packet streams are unpacked for each packet header data at each network layer [1]. We employ a multithreading packet analysis process to triage packet header data locally at a corresponding network layer and so some of packet header data is processed locally, reducing the time consumed for analysis/deep-learning time to the next threads.
-
Genetic Algorithmic Best-Fitting. As illustrated in Motivating Example 2, we employ a genetic algorithmic approach to select the best fit to suspicious network packets, to provide the fitness score for the highest likelihood of prospective attacks. In addition to the best or the worst fits to known packet sequences, this paper takes into consideration the mutant packets which occur very rarely but non-negligibly [7].
The proposed packet analysis is illustrated in Fig. 2. Authorization requests are able to share the header data states of packets, and session contexts available from servers. Stateful DPI over multithreading architecture is proposed. The contribution of this paper includes (1) improving analysis time of the big data from network traffic packet streams; (2) reducing false positives in fast and massive network packet processing; and (3) early detection of vulnerabilities.

Proposed packet analysis over multithreading and access control using states from packet header data. Note that multithreads perform to reduce bottlenecks
The remainder of this paper is organized as follows: Sect. 2 describes background knowledge on (1) unpacking network traffic packets, and (2) genetic algorithms. Section 3 describes how multithreading architecture to speed up the intrusion detection process from the big data of network packet streaming. Section 4 describes a genetic algorithmic approach to identify a malicious sequence pattern of network packet streams. Section 5 describes our preliminary experiment results. Section 6 concludes our research work.
2 Background and Related Work
Network packets are analyzed by hardware, e.g., network equipment such as routers, firewall or switches, or by software. Both hardware and software network analyzers capture and log network traffic that passes over wired network or wireless network. Since network packets are fast streaming, the network analyzers unpack the packet streams to identify header data, and apply a filtering rule set to make a quick decision of either permit or denials of their access requests. The process of packet capturing and packet unpacking can be reasonably fast but not enough to deal with big packet streams, typical IDSs apply a ruleset to the header data. The ruleset is preset and its execution is against the entire header data of each packet.
Network packets can be monitored in GUI [5] or their vulnerabilities are exploited by command-line expression [8]. An extension of basic monitoring systems for network packets is a deep packet inspection (DPI). Since DIP is very expensive and its processing time is unacceptably slow, using a classification algorithm an improvement of DIP processing time is proposed. Network packets are classified to characterize the network traffic and to improve its analysis [3]. The use of regular expressions is another approach [2].
Its efforts are extended to a few other areas: DPI techniques are extended to a specific protocol such as HTTP and HTTPS over transport layer security (TLS) [4]. Session data particularly session IDs, which can be acquired in TLS, are kept to improve the revisited sessions [10], e.g., web services over TLS and universal secured socket layer (SSL). DPI techniques are also extended to take a few other issues into consideration. Privacy is a concern while DPI is performed. Since DPI is used to detect attacks and potential security breaches, a limited connection environment is proposed to preserve privacy during DPI [9]. However, this approach does not improve the quality of early detection of packet vulnerabilities.
To improve the detection accuracy of potential attacks or threats, and to identify unforeseen vulnerabilities in advance, machine learning and data mining techniques have been discussed. Scalable Programmable Packet Processing Platform (SP4) has been proposed and demonstrated to filter out unwanted traffic and detect DDoS attacks by using Support Vector Machine algorithm [11].
There are two major techniques in deep machine learning: Artificial neural network (ANN), and genetic algorithm. Genetic algorithm (GA) is an algorithm, introduced by John Holland at University of Michigan in 1970s, that mimics some of the processes observed in biological evolution and provides the steps to compute the biological evolutionary processes [12]. GA simulates the survival of the fittest among objects (or things or solutions) over the course of generation to generation evolutions. Similar to the evolution in the chromosome of DNA, we have (1) to define objects (or solutions) to represent the problems to solve. Those solutions are then (2) populated, from which a few solutions are (3) selected. Selection is made based on a fitness function, depending on application domains, which indicates the champions may produce offspring with better fitness. Only those objects (or solutions) most successful in each selection will produce more offspring. Meanwhile, (4) GA operations can be applied as shown in Fig. 3.

General architecture of genetic algorithms
GA applies two major operations: mutation [13] and crossover [14]. These GA operators are applied to population of objects (or solutions) or their offspring. Similar to biological evolution process, the mutation or crossover operators take place randomly. When a mutation occurs, it occurs only in a small portion of an object (or solutions). For example, a sequence of DNA in unicellular bacteria may have 0.003 mutations per generation. The mutation rate depends on specious. Similarly, in DPI, the behavior of network attacks may change radically (say x days of attempt).
GA mutations can be a change/modification, an insertion of deletion that takes place at a smaller portion of a solution or an object. It is recommended that the rate of GA crossover is higher than the one for GA mutation. According to the recommendation [15, 16], the crossover rate is about 100 times the mutation rate. It is very likely that if there is active intrusion attacks on a particular IP and port, and if we see the sequence of a combination of attack tools, there are frequent crossover intrusion by starting with one tool and crossing over with attack tools.
Note that in Fig. 3, the data resource can be online real-time network intrusion data including historical data, which is downloaded by Python script in our experimentation. Constraints can be positive or negative impacts from internal and external sources. For example, mal-forecasted IP vulnerabilities, which is related with country, may have a negative impact. As such, constraints may be enforced to trigger a mutation.
Artificial neural network technique is applied to vulnerability test by constructing an attack tree [11]. Genetic algorithm has been applied to cryptanalysis [22]. Parameters, fitness functions and evolution processes for genetic algorithm are discussed to filter the traffic data and to reduce the complexity of intrusion detection [23, 24]. However, the GA approaches surveyed above do not satisfactorily forecast potential vulnerabilities from packet metadata and their stateful analysis.
3 Multithreading Analysis of Network Packet Streams
Multithreading is a mechanism of executing multiple threads of a process simultaneously. This mechanism is very useful to save the processing time when overwhelming amount of operations need to be performed together. It would be beneficial if overwhelming streaming data need to be processed at real time, especially if the streaming data processing time would create a major delay or a bottleneck for real-time processing.
Network traffic is streaming and bursty. DPI is needed over all levels of network layers from a network layer to an application layer for stateful analysis. There would be a bottleneck or an obstacle between unpacking network traffic streams and identifying attacks or analyzing packet payload (which may be very large or take longer to decrypt). For example, consider our college research network router, where the average data rate of incoming traffic and the average data rate for outgoing traffic are respectively 5 Mb/s and 7 Mb/s (as stored months or years, it is extremely a big data). The average total traffic is 12 Mb/s, and the average packet size is 150 bytes (in the range of 50 bytes and 400 bytes) and therefore there will be 80000 packets/s. The average time of a packet unpacking fully (fully for all levels: frame header data to port and payload header data) is 0.1 ms (on Intel 2.4 GHz CPUs), and the one for access control performed in Oracle Virtual Private Database (VPD on Intel 2.4 GHz CPUs) is 2 s. We call the former (1) unpacking bottleneck, and the latter (2) stateful DPI bottleneck. In this capacity, only 10000 packets can be unpacked per second, which means full unpacketing of packets is impossible, and even worse if TLS packets need to be decrypted. In this regards, inspections in most cases simply apply a rule set once as illustrated in Fig. 1.
However, Fig. 2 proposed in this paper shows that a multithreaded architecture will be able to reduce the bottleneck: multithreaded unpacking processes reduce the unpacking bottleneck by creating multiple queues, while multithreaded authentications reduce the stateful DPI bottleneck [25].
In overwhelmed network packet stream analysis, a multithreaded architecture is proposed to improve the big data process for unpacking network traffic at real-time. This paper proposes the following:
-
Dynamic creation or removal of threads. Each CPU has a maximum capacity that can perform threads. The processing time of threads should not exceed or less a threshold λ than the CPU capacity. A detailed algorithm is provided in Fig. 4.
Fig. 4. 
Algorithm 1: Dynamic multithreading for unpacking network traffics
-
Early decision of permit or deny for incoming packets. Part of early decision can be made by unpacking partial bytes of packets, which shows in the algorithm below, lines (9) and (12). Additional and more intelligent early decision will be addressed in the following section.
-
Propagation (or share) of the header data state of packets. This is shown in line (11), (14) and (16) in the algorithm below.
-
Propagation (or share) of session context (login, role, etc.). This will be discussed in the next section.

Figure 5 illustrates the states of stacks of each CUP in the proposed multithreaded packet streams. Note that the global heaps in the algorithm above contain the states of packet header data for the network and transport layers, and the states of session contexts from the session and application layers. This figure and the algorithm shows how multithreading enables the big data of network traffic streams to be processed efficiently in network infrastructures. Lines (11), (14) and (16) show a part of global heap management in our multithreading for stateful packet analysis.

Header data unpacked in network and transport layers, and state data extracted in session and application layers for multithreading
4 Using Genetic Algorithms to Learning Vulnerabilities
The goal of employing genetic algorithm (GA) is to generate both an optimal set of trusted packet sequences and those not trusted: (1) Packet sequences are learned to be trusted and therefore those packets are quickly determined to be permitted, while (2) those that will be untrusted are thus denied in advance. An ideal contribution of our GA approach is to forecast any vulnerability T3, T5 and T7 at T2. Similarly, GA results at T4 enable to skip or reduce the processes T5 and T7, and so on.
This section therefore takes the sequences of packets into consideration. A packet sequence PS can be defined over packets, pi, as follows:
For example back in Motivating Example 2, those five sequences can constitute a packet sequence, PS = p1, p2, p3, p4, p5. The order in a packet sequence is very important in many cases. For example, a few control packets such as SYN and ACK packet come before TCP or UDP packet, and then FIN packet at last. However, it is not necessary that all packets in PS are related among themselves. For analysis purpose, PS can be simply a sequence of packets in a unit time period.
In what follows in this section, the fitness table and GA operations are characterized over network traffic packets.
4.1 Fitness Table
The parameters for the fitness functions are in three dimensions, (1) Geo-temporal factors, (2) port-relevant factors, and (3) user-relevant factors. The fitness table must represent the trustworthiness of network packets. Since it is well known that the trustworthiness of source IP’s is determined dominantly by country [6]. The trustworthiness of source or destination ports is determined in part by its convention. For example, port numbers are designated to specific applications and protocols according to the network sorcery [26]. Any port access that does not follow the network sorcery are likely to attack. The trustworthiness of users is determined in part by their privileges. For example, accesses with the role of a super user are likely to attack if the other factors are met.

These three dimensional factors determine the fitness table, which is illustrated in Fig. 6. In the cube, each cell indicates a value (between −1 and +1) for three factors, one from each factor dimension, which is denoted by
where g, t and u respectively denotes geo-temporal factors, port-relevant factors, and user-relevant factors.

Fitness cube of vulnerability factors
So, for given packet sequence P, which is constituted over n packets, the fitness function proposed in this paper is:
where \( \omega \) denotes the weight for a cell value, \( 0 < = \omega \le 1 \). Hence, \( - 1 < = F\left( P \right) < = 1 \).
4.2 GA Operations
As illustrated in Fig. 3, for any given pair of packet series, PSi and PSj, which contain respectively n and m packets, the following three operations are performed. Crossover and Selection operations are performed a lot more frequently than Mutation operation. Mutation operations take place at a rate of one to five percent of the frequency of selection or crossover operations.
One of the goals for using GA approaches is to learn the dichotomy of packet sequences. An example of packet sequence dichotomy is shown in Fig. 7(c). Three packet sequences, each sequence consists of 10 packet frames. The initial fitness of those packet sequences is closer to 0, which means they are neither fitness 1, i.e., trusted, nor −1, i.e., untrusted. As combination of GA operators is iterated multiple times, the fitness of each is converged to either 1 or −1. Some sequences can be converged early, depending of the values on the fitness cube.

Dichotomy of packet sequences by genetic algorithm
5 Experimental Results
To evaluate performance of multithreading, packets are received from 4 different interfaces, including packets from a wifi router, on Intel 7i of 3.6 GHz 8 CPU core desktop. The total size of real-time network traffic packet streams for overall 10 h was 10 TB.
Of the experiments for several different features, Fig. 7(a) shows the throughput of packet processing in percentage. The throughput of packet processing is defined as
Three cases are considered: (1) the case with no threading – simply called a single thread; (2) the case of using two threads such as a thread for unpacking and a thread for authentication at backend. (3) the case of multithreading: If additional CPUs are allocated for multithreading, due to overwhelming packet delays, some packets are simply permitted or denied by the first matched rule. This may lead to false negatives and false positives. The figure shows that multithreaded packet analysis outperforms.
Figure 7(b) shows the success rate based on false positive in percentage. It shows how much of packets are finally denied at the backend database server although the packets are passed up to that point of packet traversal. Unfortunately, false negatives are filtered out before they reach the webserver or the backend database server. The success rate is defined as follows:
One of the purposes of using multithreading is to reduce false positives in packet inspection. Recall Fig. 2. This figure counts the false positives at the threads, T3, T5 and T7 of Fig. 2. The figure shows that there are more false positives at backend servers. Part of the reasons found at the backend is because the authentication at a database server takes the session contexts together with network header data.
Figure 7(c) shows that the training of genetic algorithms can identify the trusted packet sequences from the untrusted packet sequences. This experiment was performed on maximum 8 children of cross-over operations, with mutation of 0.1% of other operations.
This figure shows that the genetic algorithm trains the packet sequences well and therefore their fitness can quickly determine to either positive one or negative one. The positive one and negative one indicate respectively trusted and untrusted packet sequences.
6 Contribution
This paper proposed a multithreading architecture that can handle the big data of network traffic packet streams and it also analyze the network packet streams at real-time. The multithreaded network packet analysis propagates the network header data to the global heap area, and shares them at each level of analysis thread. The data available at the global heap area can then be used for backend database access, and together control traffic with the session contexts that can be captured at the webserver.
This paper shows that the real-time big data has been efficiently handled by multithreaded analysis. A fitness of network traffic packet streams is well defined to apply to a genetic algorithm to forecast both trusted and untrusted packet sequences.
The contribution of this paper includes (1) improving analysis time of the big data from network traffic packet streams; (2) reducing false positives in fast and massive network packet processing; and (3) early decision of vulnerabilities.
The future work will be an optimization of load-balancing over multithreads. This paper assigns loads randomly to multithreads. That means that a job in a queue may be delayed much longer if the CPU is held by a job previously assigned. Knowing the data about the jobs loaded in queues, job assignments will be able to improve.
References
Cesare, S., Xiang, Y.: Classification of malware using structured control flow. In: Proceedings of 8th Australasian Symposium on Parallel and Distributed Computing, vol. 107 (2010)
Kumar, S., Dhamapurikar, S., Yu, F., Crowley, P., Tumer, J.: Algorithms to accelerate multiple regular expressions matching for deep packet inspection. In: The ACM SIGCOMM Computer Communication Review, vol. 36, no. 4 (2006)
Cascarano, N., Ciminiera, L., Risso, F.: Improving cost and accuracy of DPI traffic classifiers. In: Proceedings of ACM Symposium on Applied Computing, Switzerland (2010)
Miura, R., Takano, Y., Miwa, S., Inoue, T.: GINTATE: scalable and extensible deep packet inspection system for encrypted network traffic. In: Proceedings of ACM Conference on SoICT, Viet Nam (2017)
Wireshark. http://www.wireshark.org. Accessed 15 Feb 2018
How to block traffic by country in the CSF firewall. https://www.liquidweb.com/kb/how-to-block-traffic-by-country-in-the-csf-firewall/. Accessed 15 Feb 2018
Caruccio, L., Deufemia, V., Polese, G.: Evolutionary mining of relaxed dependencies from big data collections. In: Proceedings of the 7th International Conference on Web Intelligence, Mining and Semantics (2017)
https://www.metasploit.com/. Accessed 22 Feb 2018
Fan, J., Guan, C., Ren, K., Cui, Y., Qiao, C.: SPABox: safeguarding privacy during deep packet inspection at a MiddleBox. IEEE/ACM Trans. Netw. 25, 3753–3766 (2017)
Lin, Z.: TLS session resumption: full-speed and secure. https://blog.cloudflare.com/tls-session-resumption-full-speed-and-secure/. Accessed 9 Mar (2018)
Gill, H., Lin, D., Sarna, L., Mead, R., Lee, K., Loo, B.: SP4: scalable programmable packet processing platform. In: ACM SIGCOMM Computer Communication Review, October 2012
Goldberg, D.: Genetic Algorithms in Search, Optimization, and Machine Learning. Addison-Wesley, Boston (1989)
Nareddy, S., Westover, E., Hillesland, K., Kim, W.: Genome dynamics in coevolved genomes: database management system for tracing mutations. In: Proceedings of the 5th ACM Conference on Bioinformatics, Computational Biology and Health Informatics, pp. 633–634 (2014)
Bogard, J.: A probabilistic functional crossover operator for genetic programming. In: Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation, pp. 925–931 (2010)
Stanhope, S.A., Daida, J.M.: Optimal mutation and crossover rates for a genetic algorithm operating in a dynamic environment. In: Porto, V.W., Saravanan, N., Waagen, D., Eiben, A.E. (eds.) EP 1998. LNCS, vol. 1447, pp. 693–702. Springer, Heidelberg (1998). https://doi.org/10.1007/BFb0040820
http://www.obitko.com/tutorials/genetic-algorithms/recommendations.php. Accessed 28 Jan 2016
LeFevre, J., Sankaranarayanan, J., Hacigumus, H., Tatemura, J., Polyzotis, N.: Towards a workload for evolutionary analytics. In: Proceedings of the 2nd Workshop on Data Analytics in the Cloud (2013)
Fan, W., Geerts, F., Cao, Y., Deng, T., Lu, P.: Querying big data by accessing small data. In: ACM Symposium of Principles of Database Systems, pp. 173–184 (2015)
http://eoddata.com/default.aspx. Accessed 29 Jan 2016
The R project for statistical computing. https://www.r-project.org/. Accessed 29 Jan 2016
Tumoyan, E., Kavchuk, D.: The method of optimizing the automatic vulnerability validation. In: Proceedings of the 5th International Conference on Security of Information and Networks (2012)
Bergmann, K., Scheidler, R., Jacob, C.: Cryptanalysis using genetic algorithms. In: Proceedings of the 10th Annual Conference on Genetic and Evolutionary Computation, July 2008
Hoque, M., Mukit, M., Bikas, M.: An implementation of intrusion detection system using genetic algorithm. Int. J. Netw. Secur. Appl. 4 (2012)
Hashemi, M., Muda, Z., Yassin, W.: Improving intrusion detection using genetic algorithm. Inf. Technol. J. 12, 2167–2173 (2013)
Khan, A., Gleich, D., Pothen, A., Halappanavar, M.: A multithreaded algorithm for network alignment via approximate matching. In: Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (2012)
RFC Sourcebook, TCP/UDP ports. http://www.networksorcery.com. Accessed 1 Mar 2018
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Yoon, J., DeBiase, M. (2018). Real-Time Analysis of Big Network Packet Streams by Learning the Likelihood of Trusted Sequences. In: Chin, F., Chen, C., Khan, L., Lee, K., Zhang, LJ. (eds) Big Data – BigData 2018. BIGDATA 2018. Lecture Notes in Computer Science(), vol 10968. Springer, Cham. https://doi.org/10.1007/978-3-319-94301-5_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-94301-5_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-94300-8
Online ISBN: 978-3-319-94301-5
eBook Packages: Computer ScienceComputer Science (R0)