
Abstract
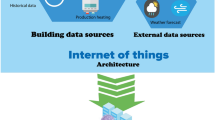
In the current era of big data, high volumes of a wide variety of data of different veracity can be easily generated or collected at a high velocity from rich sources of data include devices from the Internet of Things (IoT). Embedded in these big data are useful information and valuable knowledge. Hence, frequent pattern mining and its related research problem of association rule mining, which aim to discover implicit, previously unknown and potentially useful information and knowledge—in the form of sets of frequently co-occurring items or rules revealing relationships between these frequent sets—from these big data have drawn attention of many researchers. For instance, since introduction of the research problems of association rule mining or frequent pattern mining, numerous information system and engineering approaches have been developed. These include the development of serial algorithms, distributed and parallel algorithms, as well as MapReduce-based big data mining algorithms. These algorithms can be run in local computers, distributed and parallel environments, as well as clusters, grids and clouds. In this paper, we describe some of these algorithms and discuss how to mine frequent patterns or association rules in fogs—i.e., edges of the computing network.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Frawley, W.J., Piatetsky-Shapiro, G., Matheus, C.J.: Knowledge discovery in databases: an overview. AI Mag. 13(3), 57–70 (1992)
Agrawal, R., Imieliński, T., Swami, A.: Mining association rules between sets of items in large databases. In: Proceedings of ACM SIGMOD 1993, pp. 207–216 (1993)
Leung, C.K., Jiang, F., Cruz, E.M.D., Elango, V.S.: Association rule mining in collaborative filtering. In: Collaborative Filtering Using Data Mining and Analysis, pp. 159–179 (2017)
Agrawal, R., Srikant, R.: Fast algorithms for mining association rules in large databases. In: Proceedings of VLDB 1994, pp. 487–499 (1994)
Leung, C.K.: Frequent itemset mining with constraints. In: Encyclopedia of Database Systems, 2nd edn (2018). https://doi.org/10.1007/978-0-387-39940-9_170
Han, J., Pei, J., Yin, Y.: Mining frequent patterns without candidate generation. In: Proceedings of ACM SIGMOD 2000, pp. 1–12 (2000)
Pei, J., Han, J., Lu, H., Nishio, S., Tang, S., Yang, D.: H-mine: hyper-structure mining of frequent patterns in large databases. In: Proceedings of IEEE ICDM 2001, pp. 441–448 (2001)
Jiang, F., Leung, C.K., Zhang, H.: B-mine: frequent pattern mining and its application to knowledge discovery from social networks. In: Li, F., Shim, K., Zheng, K., Liu, G. (eds.) APWeb 2016. LNCS, vol. 9931, pp. 316–328. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-45814-4_26
Zaki, M.J.: Scalable algorithms for association mining. IEEE TKDE 12(3), 372–390 (2000)
Zaki, M.J.: Fast vertical mining using diffsets. In: Proceedings of ACM KDD 2003, pp. 326–335 (2003)
Shenoy, P., Bhalotia, J.R., Bawa, M., Shah, D.: Turbo-charging vertical mining of large databases. In: Proceedings of ACM SIGMOD 2000, pp. 22–33 (2000)
Agrawal, R., Srikant, R.: Mining sequential patterns. In: Proceedings of IEEE ICDE 1995, pp. 3–14 (1995)
Jiang, F., Leung, C.K., Sarumi, O.A., Zhang, C.Y.: Mining sequential patterns from uncertain big DNA data in the spark framework. In: Proceedings of IEEE BIBM 2016, pp. 874–881 (2016)
Chanda, A.K., Ahmed, C.F., Samiullah, M., Leung, C.K.: A new framework for mining weighted periodic patterns in time series databases. Expert Syst. Appl. 79, 207–224 (2017)
Leung, C.K., Khan, Q.I.: DSTree: a tree structure for the mining of frequent sets from data streams. In: Proceedings of IEEE ICDM 2006, pp. 928–932 (2006)
Shajib, M.B., Samiullah, M., Ahmed, C.F., Leung, C.K., Pazdor, A.G.M.: An efficient approach for mining frequent patterns over uncertain data streams. In: Proceedings of IEEE ICTAI 2016, pp. 980–984 (2016)
Ramamohanarao, K.: Contrast pattern mining and its applications. In: Proceedings of ADC 2010, pp. 5–8 (2010)
Carmichael, C.L., Hayduk, Y., Leung, C.K.: Visually contrast two collections of frequent patterns. In: Proceedings of IEEE ICDM Workshops 2011, pp. 1128–1135 (2011)
Leung, C.K.-S., Mateo, M.A.F., Brajczuk, D.A.: A tree-based approach for frequent pattern mining from uncertain data. In: Washio, T., Suzuki, E., Ting, K.M., Inokuchi, A. (eds.) PAKDD 2008. LNCS, vol. 5012, pp. 653–661. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-68125-0_61
Leung, C.K.-S.: Uncertain frequent pattern mining. In: Aggarwal, C.C., Han, J. (eds.) Frequent Pattern Mining, pp. 339–367. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-07821-2_14
Leung, C.K., MacKinnon, R.K., Jiang, F.: Finding efficiencies in frequent pattern mining from big uncertain data. World Wide Web (WWW) 20(3), 571–594 (2017)
Li, Y., Bailey, J., Kulik, L., Pei, J.: Mining probabilistic frequent spatio-temporal sequential patterns with gap constraints from uncertain databases. In: Proceedings of IEEE ICDM 2013, pp. 448–457 (2013)
Zaki, M.J.: Parallel and distributed association mining: a survey. IEEE Concurr. 7(4), 14–25 (1999)
Tanbeer, S.K., Ahmed, C.F., Jeong, B.: Parallel and distributed frequent pattern mining in large databases. In: Proceedings of IEEE HPCC 2009, pp. 407–414 (2009)
Agrawal, R., Shafer, J.C.: Parallel mining of association rules. IEEE TKDE 8(6), 962–969 (1996)
Chandru, V., Mueller, F.: Hybrid MPI/OpenMP programming on the Tilera manycore architecture. In: Proceedings of HPCS 2016, pp. 326–333 (2016)
Utrera, G., Gil, M., Martorell, X.: In search of the best MPI-OpenMP distribution for optimum Intel-MIC cluster performance. In: Proceedings of HPCS 2015, pp. 429–435 (2015)
Rosa, A., Chen, L.Y., Binder, W.: Predicting and mitigating jobs failures in big data clusters. In: Proceedings of IEEE/ACM CCGrid 2015, pp. 221–230 (2015)
Ertl, B., Stevanovic, U., Hayrapetyan, A., Wegh, B., Hardt, M.: Identity harmonization for federated HPC, grid and cloud services. In: Proceedings of HPCS 2016, pp. 621–627 (2016)
Cuzzocrea, A., Leung, C.K., Jiang, F., MacKinnon, R.K.: Complex mining from uncertain big data in distributed environments: problems, definitions and two effective and efficient algorithms. In: Big Data Management and Processing, pp. 297–332 (2017)
Leung, C.K.: Big data analysis and mining, Chap. 30. In: Encyclopedia of Information Science and Technology, 4th edn (2017)
Leung, C.K.-S., Hayduk, Y.: Mining frequent patterns from uncertain data with MapReduce for big data analytics. In: Meng, W., Feng, L., Bressan, S., Winiwarter, W., Song, W. (eds.) DASFAA 2013. LNCS, vol. 7825, pp. 440–455. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-37487-6_33
Fumarola, F., Malerba, D.: A parallel algorithm for approximate frequent itemset mining using MapReduce. In: Proceedings of HPCS 2014, pp. 335–342 (2014)
Dean, J., Ghemawat, S.: MapReduce: simplified data processing on large clusters. In: Proceedings of OSDI 2004, pp. 137–150 (2004)
Noor, S., Uddin, V.: MapReduce for multi-view object recognition. In: Proceedings of HPCS 2016, pp. 575–582 (2016)
Buyya, R., Yeo, C.S., Venugopal, S., Broberg, J., Brandic, I.: Cloud computing and emerging IT platforms: vision, hype, and reality for delivering computing as the 5th utility. FGCS 25(6), 599–616 (2009)
Han, Z., Leung, C.K.: FIMaaS: scalable frequent itemset mining-as-a-service on cloud for non-expert miners. In: Proceedings of BigDAS 2015, pp. 84–91 (2015)
Savasere, A., Omiecinski, E., Navathe, S.: An efficient algorithm for mining association rules in large databases. In: Proceedings of VLDB 1995, pp. 432–444 (1995)
Wang, K., Tang, L., Han, J., Liu, J.: Top down FP-Growth for association rule mining. In: Chen, M.-S., Yu, P.S., Liu, B. (eds.) PAKDD 2002. LNCS (LNAI), vol. 2336, pp. 334–340. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-47887-6_34
Zaiane, O.R., El-Hajj, M., Lu, P.: Fast parallel association rule mining without candidacy generation. In: Proceedings of IEEE ICDM 2001, pp. 665–668 (2001)
Yu, K.-M., Zhou, J., Hsiao, W.C.: Load balancing approach parallel algorithm for frequent pattern mining. In: Malyshkin, V. (ed.) PaCT 2007. LNCS, vol. 4671, pp. 623–631. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-73940-1_63
Chen, D., Lai, C., Hu, W., Chen, W.G., Zhang, Y., Zheng, W.: Tree partition based parallel frequent pattern mining on shared memory systems. In: Proceedings of IEEE IPDPS 2006 (2006)
Lin, M., Lee, P., Hsueh, S.: Apriori-based frequent itemset mining algorithms on MapReduce. In: Proceedings of ICUIMC 2012 (2012). Article no. 76
Rajaraman, A., Ullman, J.D.: Mining of Massive Datasets. Cambridge University Press, Cambridge (2011)
Li, H., Wang, Y., Zhang, D., Zhang, M., Chang, E.Y.: PFP: parallel FP-growth for query recommendation. In: Proceedings of ACM RecSys 2008, pp. 107–114 (2008)
Zhang, Z., Ji, G., Tang, M.: MREclat: an algorithm for parallel mining frequent itemsets. In: Proceedings of CBD 2013, pp. 177–180 (2013)
Snady, M., Emin, A., Bart, G.: Frequent itemset mining for big data. In: Proceedings of IEEE BigData 2013, pp. 111–118 (2013)
Bonomi, F., Milito, R., Natarajan, P., Zhu, J.: Fog computing: a platform for Internet of Things and analytics. In: Bessis, N., Dobre, C. (eds.) Big Data and Internet of Things: A Roadmap for Smart Environments. SCI, vol. 546, pp. 169–186. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-05029-4_7
Dastjerdi, A.V., Buyya, R.: Fog computing: helping the Internet of Things realize its potential. IEEE Comput. 49(8), 112–116 (2016)
Linthicum, D.S.: Connecting fog and cloud computing. IEEE Cloud Comput. 4(2), 18–20 (2017)
Cannataro, M., Cuzzocrea, A., Pugliese, A.: A probabilistic approach to model adaptive hypermedia systems. In: Proceedings of WebDyn 2001, pp. 12–30 (2001)
Cuzzocrea, A., Furfaro, F., Saccà, D.: Enabling OLAP in mobile environments via intelligent data cube compression techniques. J. Intell. Inf. Syst. 33(2), 95–143 (2009)
Cuzzocrea, A.: Accuracy control in compressed multidimensional data cubes for quality of answer-based OLAP tools. In: Proceedings of SSDBM 2006, pp. 301–310 (2006)
Cuzzocrea, A., Fortino, G., Rana, O.F.: Managing data and processes in cloud-enabled large-scale sensor networks: state-of-the-art and future research directions. In: Proceedings of IEEE/ACM CCGrid 2013, pp. 583–588 (2013)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Braun, P., Cuzzocrea, A., Leung, C.K., Pazdor, A.G.M., Tanbeer, S.K., Grasso, G.M. (2018). An Innovative Framework for Supporting Frequent Pattern Mining Problems in IoT Environments. In: Gervasi, O., et al. Computational Science and Its Applications – ICCSA 2018. ICCSA 2018. Lecture Notes in Computer Science(), vol 10964. Springer, Cham. https://doi.org/10.1007/978-3-319-95174-4_49
Download citation
DOI: https://doi.org/10.1007/978-3-319-95174-4_49
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-95173-7
Online ISBN: 978-3-319-95174-4
eBook Packages: Computer ScienceComputer Science (R0)