
Abstract
The prevalence of open data and the expansion of published information on the web have engendered a large scale of available RDF data. When dealing with the evolution of the published datasets, users may need to access to not only the actual version of a dataset but equally the previous ones and would like to track the evolution of data over time. To this direction, single-machine RDF archiving systems and Benchmarks have been proposed but do not scale well to query large RDF archives. Distributed data management systems present a promising direction for providing scalability and parallel processing of large volume of RDF data. In this paper, we study and compare commonly used RDF archiving techniques and querying strategies with the distributed computing platform Spark. We propose a formal mapping of versioning queries defined with SPARQL into SQL SPARK. We make a series of experimentation of these queries to study the effects of RDF archives partitioning and distribution.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
The Linked Data paradigm promotes the use of the RDF model to publish structured data on the Web. As a result, several datasets have emerged incorporating a huge number of RDF triples. The Linked Open Data cloud [3], as published in 22 August 2017 illustrates the important number of published datasets and their possible interconnections (1,184 datasets having 15,993 links). LODstats, a project constantly monitoring statistics reports 2,973 RDF datasets that incorporate approximately 149 billion triples. As a consequence, an emerging interest on what we call archiving of RDF datasets [5, 9, 15] has emerged raising several challenges that need to be addressed. Moreover, the emergent need for efficient web data archiving leads to recently developed Benchmarking RDF archiving systems such as BEAR (BEnchmark of RDF ARchives) [5] and EvoGen [9]. More recently, the EU H20205 HOBBITFootnote 1 project is focusing the problem of Benchmarking Big Linked Data. A new Benchmark SPBv was developed with some preliminary experimental results [12].
Obviously, the fast increasing size of RDF datasets raises the need to treat the problem of RDF archiving as a Big data problem. Many efforts have been done to processes RDF data with distributed framework (MapReduce, Hadoop and Spark) [1]. Nevertheless, no works have been realized for managing RDF archives on top of cluster computing engine. The problem is more challenging here as distributed framework are not designed for RDF processing nor for evolution management. Distributed data management systems present a promising direction for providing scalability and parallel processing of large volume of RDF data. The development of distributed RDF system is based on the following key principles: (i) the input data is partitioned across multiple nodes such that each node is responsible of a distinct set of triples, (ii) Answering queries typically involve processing of local data at each node with data exchange among nodes. Theses two principles are closely connected as the way we answer a query depends on the way the data is partitioned. Equally, the efficiency of a partitioning strategy depends on the shape of used query. For example, subject-based hash partitioning is efficient with Star-pattern queries while its efficiency drops significantly with more complex query shapes.
Beside the subject, object and property attributes used in RDF, the partitioning of RDF archives has to take into consideration the timestamp/attribute indicating to which version it belongs. How can we partition the data in order to efficiently respond to time-traversing, single version or cross-version queries. Equally, we have to take into consideration the archiving strategy to be used [5, 11, 15]: Independent Copies, Change-Based and Temporal strategies. The first one is a naive approach since it manages each version of a dataset as an isolated one. While the use of deltas reduces space storage, the computation of full version on-the-fly may cause overhead at query time. Using a distributed framework would give advantage to the Independent Copies approach as delta-based approach may induce the computing of one or more versions on the fly.
In this paper, we use the in-memory cluster computing framework SPARK for managing and querying RDF data archive. We study and compare commonly used RDF archiving techniques and querying strategies. We propose a formal mapping of versioning queries defined with SPARQL into SQL SPARK. Evaluation was performed in cloud environment ‘Amazon Web services’ using EMR (Elastic Map reduce) as a platform. Commonly used versioning queries are implemented with detailed experimentation.
The paper is organized as follows. Section 2 presents existing approaches for the design and evaluation of RDF archiving and versioning systems. Section 3 presents our approach for managing and querying RDF dataset archives with SPARK. A mapping of SPARQL into SPARK SQL an5d a discussion of the cost of versionning RDF queries are presented in Sect. 4. Finally, an evaluation of RDF versioning queries is presented in Sect. 5.
2 Related Works
Over the last decade, the published data is continuously growing leading to the explosion of the data on the Web and the associated Linked Open Data (LOD) in various domains. This evolution naturally happens without pre-defined policy hence the need to track data changes and thus the requirement to build their own infrastructures in order to preserve and query data over time. RDF archiving systems are not only used to store and provide access to different versions, but should allow different types of queries [5, 11, 15]. We note version materialization which is a basic query where a full version is retrieved. Delta materialization which is a type of query performed on two versions to detect changes occurring at a given moment. Single and cross-version are SPARQL queries performed respectively on a single or different versions.
The emergent need for efficient web data archiving leads to recently developed Benchmarking RDF archiving systems such as BEAR (BEnchmark of RDF ARchives) [5, 6] EvoGen [9] and SPBv [12]. The authors of the BEAR system propose a theoretical formalization of an RDF archive and conceive a benchmark focusing on a set of general and abstract queries with respect to the different categories of queries as defined before. More recently, the EU H2020 HOBBIT project is focusing on the problem of Benchmarking Big Linked Data. In this context, EvoGen is proposed as a configurable and adaptive data and query load generator [9]. EvoGen extends the LUBM ontology and is configurable in terms of archiving strategies and the number of versions or changes. Recently, new Benchmark SPBv was developed with some preliminary experimental results [12]. Similar to EvoGen, SPBv proposes a configurable and adaptive data and query load generator.
Moreover, these archiving systems and Benchmarks adopt different versionning approaches: (a) Independent Copies (IC), (b) Change Based copies (CB) or Deltas and (c) Timestamp-based approaches (TB) [5, 11]. We talk about hybrid approaches when the above techniques are combined [15]. The IC approach manages each version of a dataset as an isolated one while the CB approach stores only the changes that should be kept between versions also known as delta. The advantage beyond the use of IC or CB approaches depends on the ratio of changes occurring between consecutive versions. If only few changes are kept, CB approach reduces space overhead compared to the IC one. Nevertheless, if frequent changes are made between consecutive versions, IC approach becomes more storage-efficient than CB. Equally, the computation of full version on-the-fly with CB approach may cause overhead at query time. To resolve this issue, authors in [15] propose hybrid archiving policies to take advantage of both the IC and CB approaches. In fact, a cost model is conceived to determine what to materialize at a given time: a version or a delta.
Many efforts have been done to process RDF linked data with existing Big data processing infrastructure (MapReduce, Hadoop or Spark) [10, 14]. An RDF dataset is stored in one or more files in HDFS and the input dataset is partitioned among nodes such as each node is responsible of its own set of triples [1]. Using MapReduce, for example, a SPARQL query is executed as a sequence of iterations - an iteration for each subquery. The final result is obtained by joining the results obtained in each iteration. The main challenge in developing distributed RDF systems is how to adequately partition the RDF data in a way that minimize the number of intermediate result transfers between nodes.
Hash based partitioning is considered as the foundation of parallel processing in database community and it has been applied in several RDF systems [1, 2, 10]. Subject hash partitioning has proven its efficiency with queries having only subject-subject joins (Star query pattern) [2, 10]. In fact, triple patterns having the same subject are stored in the same node and no transfer is needed between nodes [10]. Nevertheless, the efficiency of subject hash partitioning drops significantly with queries requiring object-subject/object-object joins. To overcome this problem, a cost based query model is proposed in [10] to reduce the number of transfer between nodes. CliqueSquare [7] partitions each triple pattern on the subject, predicate and object. Vertical/relational partitioning is adopted in [14]. Based on a pre-evaluation of the data, many RDF triple patterns are used to partition the data into partition tables (a partition for each triple pattern) [14]. That is, a triple query pattern can be retrieved by only accessing the partition table that bounds the query leading to a reduction of the execution time.
3 RDF Dataset Archiving on Apache Spark
In this section, we present the main features of Apache SPARK cluster computing framework. We show how we can use it for a distributed storage of RDF datasets with Independent Copies and Change-based Approaches.
3.1 Apache Spark
Apache Spark [17] is a main-memory extension of the MapReduce model for parallel computing that brings improvements through the data-sharing abstraction called Resilient Distributed Dataset (RDD) [16] and Data frames offering a subset of relational operators (project, join and filter) not supported in Hadoop.
Spark also offers two higher-level data accessing models, an API for graphs and graph-parallel computation called GraphX [8] and Spark SQL, a Spark module for processing semi-structured data. As the RDF data model is interpreted as a graph and processing SPARQL can be seen as a subgraph query pattern matching, GraphX seems to offer a natural way for querying RDF data [13]. Nevertheless, GraphX is optimized to distribute the workload of highly-parallel graph algorithms, such as PageRank, that are performed on the whole graph. However, this process is not adapted for querying RDF datasets where queries define a small subgraph pattern leading to highly unbalanced workloads [10, 13].
3.2 RDF Dataset Storage and Change Detection
SPARK SQL offers the users the possibility to extract data from heterogeneous data sources and can automatically infer their schema and data types from the language type system (e.g. Scala, Java or Python). In our approach, we use SPARK SQL for querying and managing the evolution of RDF datasets. An RDF dataset stored in HDFS or as a table in Hive or any external database system is mapped into a SPARK dataframes (equivalent to tables in a relational database) with columns corresponding respectively to the subject, property, object, named graph and eventually a tag of the corresponding version.
In order to obtain a view of a dataframe named “table”, for example, we execute the following SPARK SQL query:

Figure 1 shows a view of a SPARK dataframe containing two triples patterns and the values of their attributes in two versions \(V_1\) and \(V_2\).

Example of a dataframe with RDF dataset attributes.
When we want to materialize a given version, \(V_1\) for example, the following SPARK SQL query is used:

Another advantage beyond the use of SPARK SQL for the RDF dataset archiving is the scalability of RDF change detection issue. Many approaches implement change detection algorithms on the MapReduce framework [2]. Using SQL SPARK, we can easily detect the change between two different versions by executing a simple SQL SPARK query:

3.3 RDF Dataset Partitioning
In this section, we present the principle that we adopt for the partitioning of RDF dataset archives for efficiently executing single version and cross-versions queries (Fig. 2). Concerning version and delta materialization queries, all the data (version or delta) will be loaded and no partition is needed.
-
First of all, we load RDF datasets in a N-triple format from HDFS as input.
-
Then, a mapping is realized from RDF files into dataframes with corresponding columns: subject, object, predicate and a tag of the version.
-
We adopt a hash partitioning by RDF subject for each version.
-
The SPARK SQL engine processes and the query result is returned.

Query execution with data partition of single version and cross-version queries.
4 Querying RDF Dataset Archives with SPARK SQL
SPARK SQL [4] is a Spark module that performs relational operations via a DataFrame API offering users the advantage of relational processing, namely declarative queries and optimized storage. SPARK SQL supports relational processing both on native RDDs or on external data sources using any of the programming language supported by Spark, e.g., Java, Scala or Python [4]. SPARK SQL can automatically infer their schema and data types from the language type system. SPARK SQL is used in [10, 14] for querying large RDF datasets where a query compiler from SPARQL to SPARK SQL is provided. That is, a FILTER expression can be mapped into a condition in Spark SQL while UNION, OFFSET, LIMIT, ORDER BY and DISTINCT are mapped into their equivalent clauses in the SPARK SQL syntax. Theses mapping rules are used without considering SPARQL query shapes.
In this section, we define basic RDF archiving queries (version/delta materialization, single/cross version query) with SPARK SQL. We propose then a formal mapping of SPARQL into SPARK SQL based on SPARQL query shape patterns.
4.1 Querying RDF Dataset Archives with SPARK SQL
Using SPARK SQL, we can define RDF dataset archiving queries as follows:
-
Version materialization: \(Mat(V_i)\).
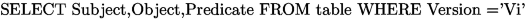
-
Delta materialization: \(Delta(V_i,V_j)\).

-
Single-version query: \([[Q]]_{V_i}\). We suppose here a simple query Q which asks for all the subject in the RDF dataset.

-
Cross-version structured query: \(Join(Q_1,V_i,Q_2,V_j)\). What we need here is a join between the two query results. We define two dataframe table\(_i\) and table\(_j\) containing respectively the version \(V_i\) and \(V_j\). The cross-version query is defined as follows:

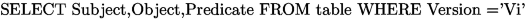



We note that, for more clarity, we have supposed in this section the use of simple single-version and cross-version queries. Nevertheless, in real world applications, complex SPARQL query are used and a mapping from SPARQL query to SPARK SQL is needed.
4.2 From SPARQL to SPARK SQL
SPARQL graph pattern can have different shapes which can influence query performance. Depending on the position of variables in the triple patterns, SPARQL query pattern may be classified into three shapes:
-
1.
Star pattern: this query pattern is commonly used in SPARQL. A star pattern has diameter (longest path in a pattern) one and is characterized by a subject-subject joins between triple patterns.
-
2.
Chain pattern: this query pattern is characterized by object-subject (or subject-object) joins. The diameter of this query corresponds to the number of triple patterns.
-
3.
Snowflake pattern: this query pattern results from the combination of many star patterns connected by short paths.

SPARQL graph pattern shapes.
When we query RDF dataset archives, we have to deal with SPARQL query shapes only in single version and cross-version queries. We propose in the following a mapping from SPARQL to SPARK SQL based on query shapes (Fig. 3):
-
Star pattern: a Star SPARQL query with n triple patterns \(P_i\) is mapped into a SPARK SQL query with n-1 joins on the subject attribute. If we consider a SPARQL query with two triple patterns \(P_1\) and \(P_2\) of the form (?x\(_1\),p\(_1\),?y\(_1\)) and (?x\(_1\),p\(_2\),?z\(_2\)), the dataframes \(df_1\) and \(df_2\) corresponding respectively to the query patterns \(P_1\) and \(P_2\) are defined with SPARK SQL as follows:

For example, given a SPARQL query pattern (?X, hasDip ?Y, ?X hasJob ?Z), we need to create two dataframes \(df_1\) and \(df_2\) as follows:

We give in the following the obtained SPARK SQL query:

-
Chain pattern: a chain SPARQL query with n triple patterns \(t_i\) is mapped into a SPARK SQL query with n-1 joins object-subject (or subject-object):

If we consider a SPARQL query with two triple patterns \(P_1\) and \(P_2\) of the form (?x\(_1\),p\(_1\),?z\(_1\)) and (?z\(_1\),p\(_2\),?t\(_2\)), the dataframes \(df_1\) and \(df_2\) corresponding respectively to the query patterns \(P_1\) and \(P_2\) are defined with SPARK SQL as follows:
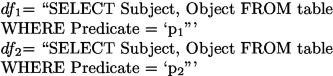
For example, given a SPARQL query with two triples (?X, hasJob ?Z, ?Z hasSpec ?Z), we need to create a dataframe for each triple:

The query result is obtained as a join between dataframes \(df_1\) and \(df_2\):
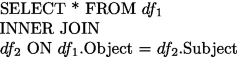
-
Snowflake pattern: the rewritten of snowflake queries follows the same principle and may need more join operations depending equally on the number of triples used in the query.




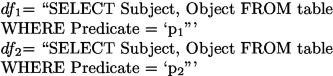

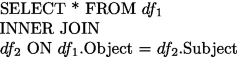
For single version query \([[Q]]_{V_i}\), we need to add a condition on the version for which we want to execute the query Q. Nevertheless, the problem becomes more complex for cross-version join query \(Join(Q_1,V_i,Q_2,V_j)\) as other join operations are needed between different versions of the dataset. Two cases may occur:
-
1.
Cross-version query \(type_1\): this type of cross-version queries concerns the case where we have one query Q on two or more different versions. For example, to follow the evolution of a given person career, we need to execute (?x,hasJob,?z) on different versions. Given a query Q and n versions, we denote \(T_1\),...,\(T_n\) the results obtained by executing Q on versions \(V_1\),...,\(V_n\) respectively. The final result is obtained by realizing the union of the \(T_i\). What we can conclude here is that the number of versions does not increase the number of joins which only depends on the shape of the query. Given a SPARQL query with a triple pattern P of the form (?x\(_1\),p,?y\(_1\)) defined on different versions \(V_1\) and \(V_2\), the SPARK SQL query is defined as follows:
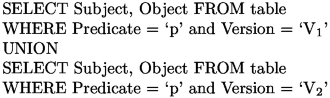
-
2.
Cross-version query \(type_2\): the second case occurs when we have two or more different queries \(Q_1\),\(Q_2\),...,\(Q_m\) on different versions. For example, we may need to know if the diploma of a person ?x has any equivalence in RDF dataset archive:
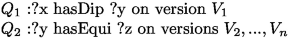
Given a SPARQL patterns \(P_1\) and \(P_2\) of the form (?x\(_1\),p\(_1\),?z\(_1\)) and (?z\(_1\),p\(_2\),?t\(_2\)) defined on different versions \(V_1\) and \(V_2\), the dataframes \(df_1\) and \(df_2\) corresponding respectively to the query patterns \(P_1\) and \(P_2\) are defined with SPARK SQL as follows:
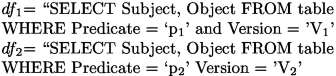
The query result is obtained as a join between dataframes \(df_1\) and \(df_2\):

Given \(df_1\),...,\(df_n\) the different dataframes obtained by executing \(Q_1\),\(Q_2\),...,\(Q_n\), respectively, on versions \(V_1\),...,\(V_n\), the final result is obtained with a combination of join and/or union operations between the \(df_i\). In the worst case we may need to compute n-1 joins:
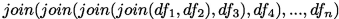
That is, for cross-version query \(type_2\), the number of joins depends on the shape of the query as well as the number of versions.
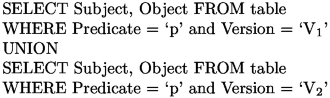
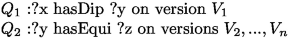
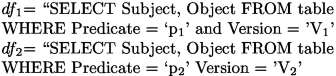

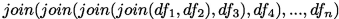
5 Experimental Evaluation
Evaluation was performed in cloud environment ‘Amazon Web services’ using EMR (Elastic Map reduce) as a platform. The data input files were saved on S3 Amazon. The experiments were done in a cluster with three nodes (one master and 2 core nodes) using m3.xlarge as an instance type. We use the BEAR dataset Benchmark which monitors more than 650 different domains across time and is composed of 58 snapshots. A description of the dataset is given in Table 1.
In the following we present the evaluationFootnote 2 of versioning queries on top of SPARK framework. The evaluation concerns four query types: version and delta materialization, single version and cross-version queries respectively.
5.1 Version and Delta Materialization
The content of the entire version (resp. Delta) is materialized. For each version, the average execution time of the queries was computed. Based on the plots shown in Fig. 4, we observe that the execution times obtained with IC strategy are approximately constant and show better results compared to the ones obtained with CB approach. In fact, versions in CB approach are not already stored and need to be computed each time we want to query a given version (resp. delta).

Version and delta materialization IC and CB approaches
5.2 Single-Version Queries
We use for this series of experimentation the Independent Copies archiving approach. We realize different experimentations with queries where the object and/or predicate is given whereas the subject corresponds to what we ask for. The analysis of the obtained plots (Fig. 5 shows that the use of subject-hash partitioning ameliorates query execution times. Nevertheless, using query with individual triple pattern does not need an important number of I/O operations. That is, the real advantage beyond the use of partitioning is not highlighted for this kind of queries.

Single version queries (Subject)
5.3 Cross-Version Queries
In this section, we focus on Cross-version queries with IC archiving approach. The first series of tests are realized with cross-version STAR query shape of the form (?X, p, ?Y) and (?X, q, ?Z). The obtained execution times are shown in Table 2. We note that the advantage beyond the use of partitioning is highlighted for this kind of queries compared to the result obtained with single triple queries. As we can see in Fig. 6, the use of subject-hash partitioning ameliorates execution times. In fact, Star query invokes triple patterns having the same subject which are loaded in the same partition.

Cross-version queries: Star and Chain query shapes
We realize a second series of tests using cross-version Chain queries with two triples patterns of the form (?X, p, ?Y) and (?Y, q, ?Z). As we can see in Table 3 the use of partitioning ameliorates execution times. Eventhough we have used queries with only two triple patterns and two versions, the execution times obtained with Chain queries are superior to the ones obtained with Star queries. In fact, for executing Chain queries, object-subject joins are needed and data transfer between nodes is necessary. That is, the performance of cross-version Chain query depends on the number of triple patterns as well as the number of versions.
6 Conclusion
In this paper, we study and compare main versioning queries and RDF archiving techniques with Spark. We propose a formal mapping of versioning queries defined with SPARQL into SQL SPARK. We make a series of experimentation of these queries to study the effects of RDF archives partitioning. Different performance tests have been realized based on: versioning approaches (Change Based or Independent Copies), the types of RDF archiving queries, the size of versions, the shape of SPARQL queries and finally the data partitioning strategy.
Experimentations are realized with IC and CB versioning approaches. The use of IC approach in distributed environment is more efficient than the use of CB one. Equally, the advantage beyond the use of subject-hash partitioning is shown with SPARQL Star queries. This is not the case of cross-version Chain queries where join between triple patterns belonging to different nodes is needed. In the future works we project to use different partitioning strategies and to define execution plan by taking into consideration, the size of a version, the number of versions and the shape of SPARQL queries.
References
Abdelaziz, I., Harbi, R., Khayyat, Z., Kalnis, P.: A survey and experimental comparison of distributed SPARQL engines for very large RDF data. In: Proceedings of the VLDB Endowment - Proceedings of the 43rd International Conference on Very Large Data Bases, Munich, Germany, vol. 10 issue 13, pp. 2049–2060 September 2017
Ahn, J., Im, D.-H., Eom, J.-H., Zong, N., Kim, H.-G.: G-Diff: a grouping algorithm for RDF change detection on MapReduce. In: Supnithi, T., Yamaguchi, T., Pan, J.Z., Wuwongse, V., Buranarach, M. (eds.) JIST 2014. LNCS, vol. 8943, pp. 230–235. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-15615-6_17
Abele, A., McCrae, J.P., Buitelaar, P., Jentzsch, A., Cyganiak, R.: Linking Open Data cloud diagram 2018 (2018). http://lod-cloud.net/. Accessed Apr 2018
Armbrust, M., Xin, R.S., Lian, C., Huai, Y., Liu, D., Bradley, J.K., Meng, X., Kaftan, T., Franklin, M.J., Ghodsi, A., Zaharia, M.: Spark SQL: relational data processing in spark. In: Proceedings of the SIGMOD International Conference on Management of Data, Melbourne, Victoria, Australia, pp. 1383–1394, 31 May–4 June 2015
Fernández, J.D., Umbrich, J., Polleres, A., Knuth, M.: Evaluating query and storage strategies for RDF archives. In: Proceedings of the 12th International Conference on Semantic Systems, pp. 41–48. ACM, New York (2016)
Fernandez, J.D., Umbrich, J., Polleres, A., Knuth, M.: Evaluating query and storage strategies for RDF archives. Semantic Web – Interoperability, Usability, Applicability (Semantic Web Journal) (2018, to appear). (accepted for publication)
Goasdoué, F., Kaoudi, Z., Manolescu, I., Quiané-Ruiz, J.A., Zampetakis, S.: CliqueSquare in action: flat plans for massively parallel RDF queries, October 2014
Graube, M., Hensel, S., Urbas, L.: R43ples: revisions for triples - an approach for version control in the semantic web. In: Proceedings of the 1st Workshop on Linked Data Quality co-located with 10th International Conference on Semantic Systems, Leipzig, Germany, 2 September 2014
Meimaris, M., Papastefanatos, G.: The EvoGen benchmark suite for evolving RDF data. In: MEPDaW Workshop, Extended Semantic Web Conference (2016)
Naacke, H., Curé, O., Amann, B.: SPARQL query processing with apache spark. CoRR (2016)
Papakonstantinou, V., Flouris, G., Fundulaki, I., Stefanidis, K., Roussakis, G.: Versioning for linked data: archiving systems and benchmarks. In: Proceedings of the Workshop on Benchmarking Linked Data, Kobe, Japan, 18 October 2016
Papakonstantinou, V., Flouris, G., Fundulaki, I., Stefanidis, K., Roussakis, Y.: SPBv: benchmarking linked data archiving systems. In: 2nd International Workshop on Benchmarking Linked Data co-located with 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, 21-22 October 2017
Schätzle, A., Przyjaciel-Zablocki, M., Berberich, T., Lausen, G.: S2X: graph-parallel querying of RDF with GraphX. In: Wang, F., Luo, G., Weng, C., Khan, A., Mitra, P., Yu, C. (eds.) Big-O(Q)/DMAH -2015. LNCS, vol. 9579, pp. 155–168. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-41576-5_12
Schätzle, A., Przyjaciel-Zablocki, M., Skilevic, S., Lausen, G.: S2RDF: RDF querying with SPARQL on spark. PVLDB 9(10), 804–815 (2016)
Stefanidis, K., Chrysakis, I., Flouris, G.: On designing archiving policies for evolving RDF datasets on the Web. In: Yu, E., Dobbie, G., Jarke, M., Purao, S. (eds.) ER 2014. LNCS, vol. 8824, pp. 43–56. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-12206-9_4
Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauly, M., Franklin, M.J., Shenker, S., Stoica, I.: Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing. In: Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation, San Jose, CA, USA, pp. 15–28, 25–27 April2012
Zaharia, M., Xin, R.S., Wendell, P., Das, T., Armbrust, M., Dave, A., Meng, X., Rosen, J., Venkataraman, S., Franklin, M.J., Ghodsi, A., Gonzalez, J., Shenker, S., Stoica, I.: Apache Spark: a unified engine for big data processing. Commun. ACM 59(11), 56–65 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Bahri, A., Laajimi, M., Ayadi, N.Y. (2018). Distributed RDF Archives Querying with Spark. In: Gangemi, A., et al. The Semantic Web: ESWC 2018 Satellite Events. ESWC 2018. Lecture Notes in Computer Science(), vol 11155. Springer, Cham. https://doi.org/10.1007/978-3-319-98192-5_59
Download citation
DOI: https://doi.org/10.1007/978-3-319-98192-5_59
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-98191-8
Online ISBN: 978-3-319-98192-5
eBook Packages: Computer ScienceComputer Science (R0)