
Abstract
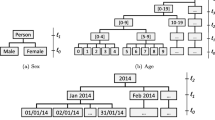
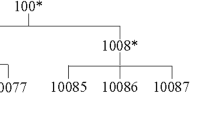
k-Anonymity is one of the most widely used techniques for protecting the privacy of the publishing datasets by making each individual not distinguished from at least k-1 other individuals. The local recoding method is an approach to achieve k-anonymization through suppression and generalization. The method generalizes the dataset at the cell level. Therefore, the local recoding could achieve the k-anonymization with only a small distortion. As the optimal k-anonymity has been proved as the NP-hard problem, the plenty of optimal algorithm local recoding has been proposed. In this research, we study the characteristics of the local recoding method. In addition, we discover the special characteristic dataset that all generalization hierarchies of each quasi-identifier are identical, called an “Identical Generalization Hierarchy” (IGH) data. We also compare the efficiency of the well-known algorithms of the local recoding method on both \(non-IGH\) and IGH data.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Aggarwal, G., Panigrahy, R., Feder, T., Thomas, D., Kenthapadi, K., Khuller, S., Zhu, A.: Achieving anonymity via clustering. ACM Trans. Algorithms 6(3), 49:1–49:19 (2010)
Bayardo, R.J., Agrawal, R.: Data privacy through optimal k-anonymization. In: Proceedings of the 21st International Conference on Data Engineering, ICDE 2005, pp. 217–228. IEEE Computer Society, Washington, DC (2005)
Byun, J.W., Kamra, A., Bertino, E., Li, N.: Efficient k-anonymization using clustering techniques. In: Proceedings of the 12th International Conference on Database Systems for Advanced Applications, DASFAA 2007, pp. 188–200. Springer, Heidelberg (2007)
Dheeru, D., Karra Taniskidou, E.: UCI machine learning repository (2017). http://archive.ics.uci.edu/ml
El Emam, K., Brown, A., AbdelMalik, P.: Evaluating predictors of geographic area population size cut-offs to manage re-identification risk. J. Am. Med. Inform. Assoc. 16(2), 256–266 (2009)
El Emam, K., Dankar, F., Issa, R., Jonker, E., Amyot, D., Cogo, E., Corriveau, J.P., Walker, M., Chowdhury, S., Vaillancourt, R., Roffey, T., Bottomley, J.: A globally optimal k-anonymity method for the de-identification of health data. J. Am. Med. Inform. Assoc. JAMIA 16, 670–82 (2009)
Goldberg, K., Roeder, T., Gupta, D., Perkins, C.: Eigentaste: a constant time collaborative filtering algorithm. Inf. Retr. 4(2), 133–151 (2001)
Harper, F.M., Konstan, J.A.: The movielens datasets: history and context. ACM Trans. Interact. Intell. Syst. 5(4), 19:1–19:19 (2015)
LeFevre, K., DeWitt, D.J., Ramakrishnan, R.: Incognito: efficient full-domain k-anonymity. In: Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, SIGMOD 2005, pp. 49–60. ACM, New York (2005)
LeFevre, K., DeWitt, D.J., Ramakrishnan, R.: Mondrian multidimensional k-anonymity. In: 22nd International Conference on Data Engineering (ICDE 2006), p. 25 (2006)
Meyerson, A., Williams, R.: On the complexity of optimal k-anonymity. In: Proceedings of the Twenty-Third ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, PODS 2004, pp. 223–228. ACM, New York (2004)
Samarati, P.: Protecting respondents identities in microdata release. IEEE Trans. Knowl. Data Eng. 13(6), 1010–1027 (2001)
Samarati, P., Sweeney, L.: Generalizing data to provide anonymity when disclosing information. In: Proceedings of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems 1998 (1998)
Sweeney, L.: Achieving k-anonymity privacy protection using generalization and suppression. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 10(5), 571–588 (2002)
Sweeney, L.: k -anonymity: a model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 10(5), 1–14 (2002)
Sweeney, L.A.: Computational disclosure control: a primer on data privacy protection. Ph.D. thesis, Massachusetts Institute of Technology, Cambridge, MA, USA (2001). AAI0803469
Wong, R.C.W., Li, J., Fu, A.W.C., Wang, K.: (\(\alpha \), k)-anonymity: an enhanced k-anonymity model for privacy preserving data publishing. In: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2006, pp. 754–759. ACM, New York (2006)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Mahanan, W., Natwichai, J., Art Chaovalitwongse, W. (2019). Characterizations of Local Recoding Method on k-Anonymity. In: Barolli, L., Kryvinska, N., Enokido, T., Takizawa, M. (eds) Advances in Network-Based Information Systems. NBiS 2018. Lecture Notes on Data Engineering and Communications Technologies, vol 22. Springer, Cham. https://doi.org/10.1007/978-3-319-98530-5_56
Download citation
DOI: https://doi.org/10.1007/978-3-319-98530-5_56
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-98529-9
Online ISBN: 978-3-319-98530-5
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)