
Abstract
We introduce RiffleScrambler: a new family of directed acyclic graphs and a corresponding data-independent memory hard function with password independent memory access. We prove its memory hardness in the random oracle model.
RiffleScrambler is similar to Catena – updates of hashes are determined by a graph (bit-reversal or double-butterfly graph in Catena). The advantage of the RiffleScrambler over Catena is that the underlying graphs are not predefined but are generated per salt, as in Balloon Hashing. Such an approach leads to higher immunity against practical parallel attacks. RiffleScrambler offers better efficiency than Balloon Hashing since the in-degree of the underlying graph is equal to 3 (and is much smaller than in Ballon Hashing). At the same time, because the underlying graph is an instance of a Superconcentrator, our construction achieves the same time-memory trade-offs.
Authors were supported by Polish National Science Centre contract number DEC-2013/10/E/ST1/00359.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In early days of computers’ era passwords were stored in plaintext in the form of pairs (user, password). Back in 1960s it was observed, that it is not secure. It took around a decade to incorporate a more secure way of storing users’ passwords – via a DES-based function crypt, as \((user, f_k(password))\) for a secret key k or as (user, f(password)) for a one-way function. The first approach (with encrypting passwords) allowed admins to learn a user password while both methods enabled to find two users with the same password. To mitigate that problem, a random salt was added and in most systems, passwords are stored as (user, f(password, salt), salt) for a one-way function f. This way, two identical passwords will with high probability be stored as two different strings (since the salt should be chosen uniformly at random).
Then another issue appeared: an adversary, having a database of hashed passwords, can try many dictionary-based passwords or a more targeted attack [21]. The ideal password should be random, but users tend to select passwords with low entropy instead. Recently, a probabilistic model of the distribution of choosing passwords, based on Zipf’s law was proposed [20]. That is why one requires password-storing function to be “slow” enough to compute for an attacker and “fast” enough to compute for the authenticating server.
To slow-down external attackers two additional enhancements were proposed. Pepper is similar to salt, its value is sampled from uniform distribution and passwords are stored as (user, f(password, salt, pepper), salt) but the value of pepper is not stored – evaluation (and guessing) of a password is slowed down by the factor equal to the size of the space from which pepper is chosen. Garlic is also used to slow down the process of verifying a password – it tells how many times f is called, a password is stored as \((user, f^{garlic}(password, salt, pepper), salt, garlic)\). Using pepper and garlic has one bottleneck – it slows down at the same rate both an attack and the legitimate server. Moreover this approach does not guarantee required advantage over an adversary who can evaluate a function simultaneously using ASICs (Application Specific Integrated Circuit) or clusters of GPUs. The reason is that the cost of evaluation of hash functions like SHA-1, SHA-2 on an ASIC is even several thousands times smaller than on a CPU. For instance Antminer S9 has claimed performance of 14 TH/s [2] (double SHA256) versus about 30 GH/s for the best currently available GPU cards (GeForce GTX 1080TI, Radeon RX Vega 56) and up to 1 GH/s for CPUs. Percival [17] noted that memory cost is more comparable across various platforms than computation time. He suggested a memory-hard functions (MHF) and introduced scrypt [17]. So the right approach in designing a password-storing function is not only to make a function slow, but to make it use relatively large amounts of memory.
One can think about an MHF as a procedure of evaluating a function F which uses some ordering of memory calls. Such a function can be described as a DAG (Directed Acyclic Graph) \(G = G_F\). Vertex v represents some internal value, and if evaluating this value requires values at \(v_{i_1},\ldots ,v_{i_M}\), then \(v_{i_1},\ldots ,v_{i_M}\) are parents of v in G. For example, calculating a function \( F = H^N(x) = H(\ldots H(H(x))\ldots )\) (H computed N times – like PBKDF2 – Password Based Key Derivation Function 2 [13] where \(N = 1024\)) can be represented by a graph \(G=(V,E)\) with vertices \(\{v_0,v_1,\ldots , v_{N-1}, v_N\}\) and edges \(E=\{(v_i,v_{i+1}), i=0,\ldots ,N-1\}\) (i.e., a path). Initially, the value at vertex \(v_0\) is x, computations yield in value F(x) at vertex \(v_{N}\).
We can categorize MHFs into two groups: data dependent MHFs (dMHF) and data independent MHFs (iMHF). Roughly speaking, for iMHFs the order of computations (graph \(G_F\)) does not depend on a password (but it can still depend on a salt), whereas the ordering of calculations in dMHFs depends on data (i.e., a password). Because dMHFs may be susceptible to various side-channel attacks (via e.g., timing attacks, memory access pattern) the main focus is on designing iMHFs.
Sequential vs Parallel Attacks. Security of memory-hard functions can be analyzed in two models: sequential one and parallel one. In the sequential model, an adversary tries to invert a function by performing computation on a single-core machine while in the parallel model an adversary may use many processors to achieve its goal. The security of a given memory-hard function comes from the properties of the underlying graphs, e.g., if an underlying graph is a Superconcentrator (see Definition 3) then a function is memory-hard in the sequential model while if the underlying graph is depth-robust then the function is memory-hard in the parallel model.
1.1 Related Work
To compare various constructions, besides iMHF and dMHF distinction, one considers the complexity of evaluation of a given function. The formal definitions of sequential/parallel complexity are stated in Sect. 2 (and are formalized as a pebble-game), here we provide the intuitive motivation behind these definitions. The sequential complexity \(\varPi _{st}^{}(G)\) of a directed acyclic graph G is the time it takes to label (pebble/evaluate) the graph times the maximal number of memory cells the best sequential algorithm needs to evaluate (pebble) the graph. In the similar fashion one defines cumulative complexity of parallel pebbling \(\varPi _{cc}^{||}(G)\) of G, here this is the sum of the number of used memory cells during labeling (pebbling) the graph by the best parallel algorithm. For detailed discussion on the pebbling game see e.g. [9, 11, 14, 16].
For a graph that corresponds to evaluating PBKDF2 above values are equal to \(\varPi _{st}(PBKDF2) = n\) and \(\varPi _{cc}^{||}(PBKDF2) = n\) while if a function is memory hard \(\varPi _{st}(PBKDF2) = \varOmega (n^2)\).
The Password Hashing Competition [1] was announced in 2013 in the quest of a standard function in the area. Argon2i [10] was the winner, while Catena [15], Lyra2 [19], yescript [3] and Makwa [18] were given a special recognition.
Let \(\textsf {DFG}_n^\lambda \) be the Catena Dragonfly Graph, \(\textsf {BFG}_n^\lambda \) be the Catena Butterfly Graph (see [8, 15]) and \(\textsf {BHG}_\sigma ^\lambda \) be the graph corresponding to evaluating Balloon Hashing [11].
Concerning sequential attacks for \(\textsf {DFG}_N^\lambda \) and \(\textsf {BHG}_\sigma ^\lambda \) we have:
Lemma 1
Any adversary using \(S \le N/20\) memory cells requires T placements such that
for \(\textsf {DFG}_N^\lambda \).
Lemma 2
Any adversary using \(S \le N/64\) memory cells, for in-degree \(\delta = 7\) and \(\lambda \) rounds requires
placements for \(\textsf {BHG}_\sigma ^\lambda \).
Concerning parallel attacks for \(\textsf {BFG}^\lambda _n\), \(\textsf {DFG}^n_\lambda \) and \(\textsf {BHG}_\sigma ^\lambda \) we have the following
Theorem 1
(Theorem 7 in [8]).
-
If \(\lambda ,n \in \mathbb {N}^+\) such that \(n=2^g(\lambda (2g-1)+1)\) for some \(g\in \mathbb {N}^+\) then
$$\varPi _{cc}^{||}(\textsf {BFG}_n^\lambda )=\varOmega \left( {n^{1.5}\over g\sqrt{g\lambda }}\right) $$ -
If \(\lambda ,n \in \mathbb {N}^+\) such that \(k=n/(\lambda +1)\) is a power of 2 then
$$\varPi _{cc}^{||}(\textsf {DFG}_n^\lambda )=\varOmega \left( {n^{1.5}\over \sqrt{\lambda }}\right) $$ -
If \(\tau , \sigma \in \mathbb {N}^+\) such that \(n=\sigma \cdot \tau \) then with high probability
$$\varPi _{cc}^{||}(\textsf {BHG}_\tau ^\sigma )=\varOmega \left( {n^{1.5}\over \sqrt{\tau }}\right) $$
Alwen and Blocki [6] show that it is possible (in parallel setting) that an attacker may save space for any iMHF (e.g., Argon2i, Balloon, Catena, etc.) so the \(\varPi _{cc}^{||}\) is not \(\varOmega (n^2)\) but \(\varOmega (n^2/{\log n})\). The attack is applicable only when the instance of an MHF requires large amount of memory (e.g., >1 GB) while in practice, MHFs would be run so the memory consumption is of the order of just several megabytes (e.g., 16 MB). In order to mount such an attack, a special-purpose hardware must be built (with lots of shared memory and many cores). While Alwen, Blocki and Pietrzak [8] improve these attacks even further, it was still unclear if this type of attack is of practical concern. But recently Alwen and Blocki [7] improved these attacks even more and presented implementation which e.g., successfully ran against the latest version of Argon (Argon2i-B).
1.2 Our Contribution
In this paper (details given in Sect. 3) we introduce \(\textsf {RiffleScrambler}\)– a new family of directed acyclic graphs and a corresponding data-independent memory hard function with password independent memory access. We prove its memory hardness in the random oracle model.
For a password x, a salt s and security parameters (integers) \(g, \lambda \):
-
1.
a permutation \(\rho = \rho _{g}(s)\) of \(N = 2^g\) elements is generated using (time reversal of) Riffle Shuffle (see Algorithm 1) and
-
2.
a computation graph \(\mathsf {RSG}_{\lambda }^N = G_{\lambda , g, s} = G_{\lambda , g}(\rho )\) is generated.
Evaluation of \(\textsf {RiffleScrambler}\) (a function on \(2\lambda \) stacked \(\mathsf {RSG}^N\) graphs) with \(S = N = 2^g\) memory cells takes the number of steps proportional to \(T \approx 3 \lambda N\) (the max-indegree of the graph is equal to 3).
Our result on time-memory trade-off concerning sequential attacks is following.
Lemma 3
Any adversary using \(S \le N/20\) memory cells requires T placements such that
for the \(\mathsf {RSG}_{\lambda }^N\).
The above lemma means that (in the sequential model) any adversary who uses S memory cells for which \(S \le N/20\) would spend at least T steps evaluating the function and \(T \ge N \left( \frac{\lambda N}{64 S}\right) ^{\lambda }\) (the punishment for decreasing available memory cells is severe). The result for sequential model gives the same level as for Catena (see Lemma 1) while it is much better than for BallonHashing (see Lemma 2). The main advantage of \(\textsf {RiffleScrambler}\) (compared to Catena) is that each salt corresponds (with high probability) to a different computation graph, and there are \(N! = 2^g!\) of them (while Catena uses one, e.g., bit-reversal based graph). Moreover it is easy to modify \(\textsf {RiffleScrambler}\) so the number of possible computation graphs is equal to \(N!^{2 \lambda } = (2^g!)^{2 \lambda }\) (we can use different – also salt dependent – permutations in each stack).
On the other hand \(\textsf {RiffleScrambler}\) guarantees better immunity against parallel attacks than Catena’s computation graph. Our result concerning parallel attacks is following.
Lemma 4
For positive integers \(\lambda , g\) let \(n = 2^g(2 \lambda g + 1)\) for some \(g \in \mathbb {N}^{+}\). Then
The \(\textsf {RiffleScrambler}\) is a password storing method that is immune to cache-timing attacks since memory access pattern is password-independent.
2 Preliminaries
For a directed acyclic graph (DAG) \(G = (V, E)\) of \(n = |V|\) nodes, we say that the indegree is \(\delta = \max _{v \in V} indeg(v)\) if \(\delta \) is the smallest number such that for any \(v \in V\) the number of incoming edges is not larger than \(\delta \). Parents of a node \(v \in V\) is the set \(\textsf {parents}_G(v) = \{u \in V: (u, v) \in E\}\).
We say that \(u \in V\) is a source node if it has no parents (has indegree 0) and we say that \(u \in V\) is a sink node if it is not a parent for any other node (it has 0 outdegree). We denote the set of all sinks of G by \(\textsf {sinks}(G) = \{v \in V: outdegree(v) = 0\}\).
The directed path \(p = (v_1, \ldots , v_t)\) is of length t in G if \((\forall i) v_i \in V\), \((v_i, v_{i+1}) \in E\), we denote it by \(\textsf {length}(p) = t\). The depth \(d = \textsf {depth}(G)\) of a graph G is the length of the longest directed path in G.
2.1 Pebbling and Complexity
One of the methods for analyzing iMHFs is to use so called pebbling game. We will follow [8] with the notation (see also therein for more references on pebbling games).
Definition 1
(Parallel/Sequential Graph Pebbling). Let \(G = (V, E)\) be a DAG and let \(T \subset V\) be a target set of nodes to be pebbled. A pebbling configuration (of G) is a subset \(P_i \subset V\). A legal parallel pebbling of T is a sequence \(P = (P_0, \ldots , P_t)\) of pebbling configurations of G, where \(P_0 = \emptyset \) and which satisfies conditions 1 and 2 below. A sequential pebbling additionally must satisfy condition 3.
-
1.
At some step every target node is pebbled (though not necessarily simultaneously).
$$ \forall x \in T \quad \exists z \le t \quad : \quad x \in P_z. $$ -
2.
Pebbles are added only when their predecessors already have a pebble at the end of the previous step.
$$ \forall i \in [t] \quad : \quad x \in (P_i \setminus P_{i-1}) \Rightarrow \textsf {parents}(x) \subset P_{i-1}. $$ -
3.
At most one pebble is placed per step.
$$ \forall i \in [t] : |P_i \setminus P_{i-1}| \le 1. $$
We denote with \(\mathcal {P}_{G, T}\) and \(\mathcal {P}_{G, T}^{||}\) the set of all legal sequential and parallel pebblings of G with target set T, respectively.
Note that \(\mathcal {P}_{G, T} \subset \mathcal {P}_{G, T}^{||}\). The most interesting case is when \(T = \textsf {sinks}(G)\), with such a T we write \(\mathcal {P}_G\) and \(\mathcal {P}_G^{||}\).
Definition 2
(Time/Space/Cumulative Pebbling Complexity). The time, space, space-time and cumulative complexity of a pebbling \(P = \{P_0, \ldots , P_t\} \in \mathcal {P}_G^{||}\) are defined as:
For \(\alpha \in \{s, t, st, cc\}\) and a target set \(T \subset V\), the sequential and parallel pebbling complexities of G are defined as
When \(T = \textsf {sinks}(G)\) we write \(\varPi _{\alpha }(G)\) and \(\varPi _{\alpha }^{||}(G)\).
2.2 Tools for Sequential Attacks
Definition 3
(N-Superconcentrator). A directed acyclic graph \({G}= \left\langle V, E \right\rangle \) with a set of vertices V and a set of edges E, a bounded indegree, N inputs, and N outputs is called \(~{\textsf {N-Superconcentrator}}\) if for every k such that \(1 \le k \le N\) and for every pair of subsets \(V_1 \subset V\) of k inputs and \(V_2 \subset V\) of k outputs, there are k vertex-disjoint paths connecting the vertices in \(V_1\) to the vertices in \(V_2\).
By stacking \(\lambda \) (an integer) N-Superconcentrators we obtain a graph called \((N,\lambda )\)-Superconcentrator.
Definition 4
(\((N, \lambda )\)-Superconcentrator). Let \({G}_i, i=0,\ldots , \lambda -1\) be N-Superconcentrators. Let \({G}\) be the graph created by joining the outputs of \({G}_i\) to the corresponding inputs of \({G}_{i+1}, i=0,\ldots ,\lambda -2\). Graph \({G}\) is called \((N, \lambda )\)-Superconcentrator.
Theorem 2
(Lower bound for a \((N, \lambda )\)-Superconcentrator [16]). Pebbling a \((N, \lambda )\)-Superconcentrator using \(S \le N/20\) pebbles requires T placements such that
2.3 Tools for Parallel Attacks
We build upon the results from [8], hence we shall recall the definitions used therein.
Definition 5
(Depth-Robustness [8]). For \(n \in \mathcal {N}\) and \(e, d \in [n]\) a DAG \(G = (V, E)\) is (e, d)-depth-robust if
For (e, d)-depth-robust graph we have
Theorem 3
(Theorem 4 [8]). Let G be an (e, d)-depth-robust DAG. Then we have \(\varPi _{cc}^{||}(G) > ed\).
We can obtain better bounds on \(\varPi _{cc}^{||}(G)\) having more assumptions on the structure of G.
Definition 6
(Dependencies [8]). Let \(G=(V,E)\) be a DAG and \(L\subseteq V\). We say that L has a \((z,g)-\)dependency if there exist nodes-disjoint paths \(p_1,\ldots ,p_z\) of length at least g each ending in L.
Definition 7
(Dispersed Graph [8]). Let \(g\ge k\) be positive integers. A DAG G is called \((g,k)-\)dispersed if there exists ordering of its nodes such that the following holds. Let [k] denote last k nodes in the ordering of G and let \(L_j=[jg,(j+1)g-1]\) be the \(j^{th}\) subinterval. Then \(\forall j\in [\lfloor k/g \rfloor ]\) the interval \(L_j\) has a \((g,g)-\)dependency. More generally, let \(\varepsilon \in (0,1]\). If each interval \(L_j\) only has an \((\varepsilon g,g)-\)dependency, then G is called \((\varepsilon , g,k)\)-dispersed.
Definition 8
(Stacked Dispersed Graphs [8]). A DAG \(G\in \mathbb {D}_{\varepsilon ,g}^{\lambda ,k}\) if there exist \(\lambda \in \mathbb {N}^+\) disjoint subsets of nodes \(\{L_i\subseteq V\}\), each of size k, with the following two properties:
-
1.
For each \(L_i\) there is a path running through all nodes of \(L_i\).
-
2.
Fix any topological ordering of nodes of G. For each \(i\in [\lambda ]\) let \(G_i\) be the sub-graph of G containing all nodes of G up to the last node of \(L_i\). Then \(G_i\) is an \((\varepsilon , g, k)\)–dispersed graph.
For stacked dispersed graphs we have
Theorem 4
(Theorem 4 in [8]). Let G be a DAG such that \( G \in \mathcal {D}_{\varepsilon , g}^{\lambda , k} \). Then we have
3 \(\textsf {RiffleScrambler}\)
The \(\textsf {RiffleScrambler}\) function uses the following parameters:
-
s is a salt which is used to generate a graph \({G}\),
-
g - garlic, \({G}= \left\langle V, E \right\rangle \), i.e., \(V = V_0 \cup \ldots \cup V_{2 \lambda g}\), \(|V_i| = 2^g\),
-
\(\lambda \) - is the number of layers of the graph \({G}\).
Let HW(x) denote the Hamming weight of a binary string x (i.e., the number of ones in x), and \(\bar{x}\) denotes a coordinate-wise complement of x (thus \(HW(\bar{x})\) denotes number of zeros in x).
Definition 9
Let \(B = (b_0 \ldots b_{n-1})\in \{0,1\}^n\) (a binary word of length n). We define a rank \(r_{B}(i)\) of a bit i in B as
Definition 10
(Riffle-Permutation). Let \(B = (b_0 \ldots b_{n-1})\) be a binary word of length n. A permutation \(\pi \) induced by B is defined as
for all \(0\le i \le n-1\).
Example 1
Let \(B = 11100100\), then \(r_B(0) = 0\), \(r_B(1) = 1\), \(r_B(2) = 2\), \(r_B(3) = 0\), \(r_B(4) = 1\), \(r_B(5) = 3\), \(r_B(6) = 2\), \(r_B(7) = 3\). The Riffle-Permutation induced by B is equal to \( \pi _B = \left( \begin{array}{c c c c c c c c} 0 &{} 1 &{} 2 &{} 3 &{} 4 &{} 5 &{} 6 &{} 7\\ 4 &{} 5 &{} 6 &{} 0 &{} 1 &{} 7 &{} 2 &{} 3\\ \end{array}\right) \). For graphical illustration of this example see Fig. 1.

A graph of Riffle-Permutation induced by \(B = 11100100\).
Definition 11
(N-Single-Layer-Riffle-Graph). Let \(\mathcal {V} = \mathcal {V}^0 \cup \mathcal {V}^1\) where \(\mathcal {V}^i = \{v_{0}^i, \ldots , v_{N-1}^i\}\) and let B be an N-bit word. Let \(\pi _B\) be a Riffle-Permutation induced by B. We define N-Single-Layer-Riffle-Graph (for even N) via the set of edges E:
-
1 edge: \(v_{N-1}^0 \rightarrow v_{0}^1\),
-
N edges: \(v_i^0 \rightarrow v_{\pi _B(i)}^1\) for \(i = 0, \ldots , N-1\),
-
N edges: \(v_i^0 \rightarrow v_{\pi _{\bar{B}}(i) }^1\) for \(i = 0, \ldots , N-1\).
Example 2
Continuing with B and \(\pi _B\) from Example 1, the 8-Single-Layer-Riffle-Graph is presented in Fig. 2.

An 8-Single-Layer-Riffle-Graph (with horizontal edges and edge \((v^0_7,v^1_0)\) skipped) for \(B = 11100100\). Permutation \(\pi _B\) is depicted with solid lines, whereas \(\pi _{\bar{B}}\) is presented with dashed lines.
Algorithm 3 is responsible for generating an N-Double-Riffle-Graph which is defined in the following way. From now on, we assume that \(N=2^g\).
Definition 12
(N-Double-Riffle-Graph). Let V denote the set of vertices and E be the set of edges of \({G}= (V, E)\). Let \(B_0, \ldots , B_{g-1}\) be g binary words of the length \(2^g\) each. Then N-Double-Riffle-Graph is obtained by stacking 2g Single-Layer-Riffle-Graphs resulting in a graph consisting of \((2g+1)2^g\) vertices
-
\( \{v_0^0, \ldots , v_{2^g-1}^0\} \cup \ldots \cup \{v_0^{2g}, \ldots , v_{2^g-1}^{2g}\}, \)
and edges:
-
\((2g+1) 2^g\) edges: \(v_{i-1}^j \rightarrow v_i^j\) for \(i \in \{1, \ldots , 2^g-1\}\) and \(j \in \{0, 1, \ldots , 2^g\}\),
-
2g edges: \(v_{2^g-1}^j \rightarrow v_{0}^{j+1}\) for \(j \in \{0, \ldots , 2g-1\}\),
-
\(g 2^g\) edges: \(v_i^{j-1} \rightarrow v_{\pi _{B_j}(i)}^j\) for \(i \in \{ 0, \ldots , 2^g-1\}\), \(j \in \{ 1, \ldots , g\}\),
-
\(g 2^g\) edges: \(v_i^{j-1} \rightarrow v_{ \pi _{\bar{B_j}}(i) }^j \) for \(i \in \{ 0, \ldots , 2^g-1\}\), \(j \in \{ 1, \ldots , g\}\),
and the following edges for the lower g layers – which are symmetric with respect to the level g (and where we use inverse of permutations induced by \(B_j ,j\in \{0,\ldots ,g-1\}\)):
-
\(g 2^g\) edges: \(v_{\pi ^{-1}_{B_j}(i)}^{2g-j} \rightarrow v_i^{2g-j+1} \rightarrow \) for \(i \in \{ 0, \ldots , 2^g-1\}\), \(j \in \{ 1, \ldots , g\)},
-
\(g 2^g\) edges: \(v_{ i }^{2g-j} \rightarrow v_{\pi ^{-1}_{B_j}(i) }^{2g-j+1} \) for \(i \in \{ 0, \ldots , 2^g-1\}\), \(j \in \{ 1, \ldots , g\}\).
Definition 13
(\((N, \lambda )\)-Double-Riffle-Graph). Let \({G}_i, i=0,\ldots , \lambda -1\) be N-Double-Riffle-Graphs. The \((N, \lambda )\)-Double-Riffle-Graph is a graph obtained by stacking \(\lambda \) times N-Double-Riffle-Graphs together by joining outputs of \({G}_i\) to the corresponding inputs of \({G}_{i+1}, i=0,\ldots ,\lambda -2\).
One of the ingredients of our main procedure is a construction of \((N,\lambda )\)-Double-Riffle-Graph using specific binary words \(B_0,\ldots , B_{g-1}\). To continue, we have to introduce “trajectory tracing”. For given \(\sigma \) – a permutation of \(\{0,\ldots ,2^g-1\}\) – let \(\mathbf {B}\) be a binary matrix of size \(2^g\times g\), whose j-th row is a binary representation of \(\sigma (j), j=0,\ldots ,2^g-1\). Denote by \(B_i\) the i-th column of \(\mathbf {B}\), i.e., \(\mathbf {B}=(B_0,\ldots , B_{2^g-1})\). We call this matrix a binary representation of \(\sigma \). Then we create a binary matrix \(\mathfrak {B}=(\mathfrak {B}_0,\ldots ,\mathfrak {B}_{2^g-1})\) (also of size \(2^g\times g\)) in the following way. We set \(\mathfrak {B}_0=B_0\). For \(i=1,\ldots , 2^g-1\) we set \(\mathfrak {B}_i=\pi _{\mathfrak {B}_{i-1}^T}(B_i)\). The procedure \(\textsf {TraceTrajectories}\) is given in Algorithm 2.
Roughly speaking, the procedure \({\textsf {RiffleScrambler}}(x, s, g, \lambda )\) works in the following way.
-
For given salt s it calculates a pseudorandom permutation \(\sigma \) (using inverse Riffle Shuffle), let \(\mathbf {B}\) be its binary representation.
-
It calculates \(\mathfrak {B}=\) TraceTrajectories \( (\mathbf {B})\).
-
It creates an instance of N-Double-Riffle-Graph (\(2g+1\) rows of \(2^g\) vertices) using \(\mathfrak {B}^T_0,\ldots , \mathfrak {B}^T_{g-1}\) as binary words.
-
It evaluates x on the graph, calculates values at nodes on last row, i.e., \(v_0^{2g+1},\ldots , v^{2^g-1}_{2g+1}\).
-
Last row is rewritten to first one, i.e., \(v^0_i=v^{2g+1}_i, i=0,\ldots 2^g-1\), and whole evaluation is repeated \(\lambda \) times.
-
Finally, the value at \(v^{2g}_{2^g-1}\) is returned.
The main procedure \({\textsf {RiffleScrambler}}(x, s, g, \lambda )\) for storing a password x using salt s and memory-hardness parameters \(g,\lambda \) is given in Algorithm 4.
Example 3
An example of (8, 1)-Double-Riffle-Graph which was obtained from a permutation \( \sigma = \left( \begin{array}{c c c c c c c c} 0 &{} 1 &{} 2 &{} 3 &{} 4 &{} 5 &{} 6 &{} 7\\ 5 &{} 4 &{} 6 &{} 3 &{} 2 &{} 7 &{} 0 &{} 1\\ \end{array}\right) \). Its binary representation is the following:
We obtain trajectories of the elements and we can derive words/permutations for each layer of the graph:
-
\(\mathfrak {B}_0=B_0 = (11100100)^T\) (used in the previous examples) – obtained by concatenating first digits of elements, we have \( \pi _{B_0} = \left( \begin{array}{c c c c c c c c} 0 &{} 1 &{} 2 &{} 3 &{} 4 &{} 5 &{} 6 &{} 7\\ 4 &{} 5 &{} 6 &{} 0 &{} 1 &{} 7 &{} 2 &{} 3\\ \end{array}\right) \).
-
\(\mathfrak {B}_1=\pi _{\mathfrak {B}_0^T}(B_1)=\pi _{\mathfrak {B}_0^T}(11100100)= (11000011)^T\), thus \( \pi _{\mathfrak {B}_1} = \left( \begin{array}{c c c c c c c c} 0 &{} 1 &{} 2 &{} 3 &{} 4 &{} 5 &{} 6 &{} 7\\ 4 &{} 5 &{} 0 &{} 1 &{} 2 &{} 3 &{} 6 &{} 7\\ \end{array}\right) \).
-
\(\mathfrak {B}_2=\pi _{\mathfrak {B}_1^T}(B_2)=\pi _{\mathfrak {B}_1^T}(10010101)=(01011001)^T\), thus \(\pi _{B_2} = \left( \begin{array}{c c c c c c c c} 0 &{} 1 &{} 2 &{} 3 &{} 4 &{} 5 &{} 6 &{} 7\\ 0 &{} 4 &{} 5 &{} 1 &{} 6 &{} 2 &{} 3 &{} 7\\ \end{array}\right) \).
-
Finally,
$$\mathfrak {B}=(\mathfrak {B}_0, \mathfrak {B}_1, \mathfrak {B}_2), \quad \mathfrak {B}^T= \left( \begin{array}{cccccccccccccccc} 1&{} 1&{} 1&{} 0&{} 0&{} 1&{} 0&{} 0 \\ 1&{} 1&{} 0&{} 0&{} 0&{} 0&{} 1&{} 1 \\ 0&{} 1&{} 0&{} 1&{} 1&{} 0&{} 0&{} 1\\ \end{array} \right) . $$
The resulting graph is given in Fig. 3.

Instance of (8,1)-Double-Riffle-Graph the graph
3.1 Pseudocodes




4 Proofs
4.1 Proof of Lemma 3
In this Section we present the security proof of our scheme in the sequential model of adversary. Recall that \(N=2^g\). To prove Lemma 3 it is enough to prove the following theorem (since then the assertion follows from Theorem 2).
Theorem 5
Let \(\rho = (\rho _0, \ldots , \rho _{2^g-1}\)) be a permutation of \(N=2^g\) elements, let \(\mathbf {B}\) be its binary representation and let \(\mathfrak {B}= (\mathfrak {B}_0,\ldots ,\mathfrak {B}_{g-1})=\) TraceTrajectories \( (\mathbf {B} )\). Let \({G}\) be an N-Double-Riffle-Graph using \(\mathfrak {B}\). Then \({G}\) is an N-Superconcentrator.
Before we proceed to the main part of the proof, we shall introduce some auxiliary lemmas showing some useful properties of the N-Double-Riffle-Graph.
Lemma 5
Let \(\rho \) be a permutation of \(N = 2^g\) elements, \(\rho = (\rho _0, \ldots , \rho _{2^g-1})\) and let \(\mathbf {B}\) be its binary representation. Let \(\mathfrak {B}=\) TraceTrajectories \( (\mathbf {B})\). Let \(\bar{{G}}\) be the subgraph of N-Double-Riffle-Graph \({G}\) constructed using \(\mathfrak {B}\), consisting of \(g+1\) layers and only of directed edges corresponding to the trajectories defined by \(\rho \). Then the index of the endpoint of the directed path from \(j\mathrm {th}\) input vertex \(v_{j}^{0}\) of \(\bar{{G}}\) is uniquely given by the reversal of the bit sequence \(\mathfrak {B}_j^T\). The input vertex \(v_{j}^{0}\) corresponds to the output vertex \(v_{k}^{g}\), where \(k = \mathfrak {B}_j(2^g-1) \ldots \mathfrak {B}_j(1) \mathfrak {B}_j(0)\).
The above lemma is very closely related to the interpretation of time-reversed Riffle Shuffle process and it follows from a simple inductive argument. Let us focus on the last layer of \(\bar{{G}}\), i.e., the sets of vertices \(V_{g-1} = \{v_0^{g-1}, \ldots , v_{2^{g}-1}^{g-1}\}\), \(V_{g} = \{v_0^{g}, \ldots , v_{2^{g}-1}^{g}\}\) and the edges between them. Let us observe that from the construction of Riffle-Graph, the vertices from \(V_{g}\) with indices whose binary representation starts with 1 are connected with the vertices from \(V_{g-1}\) having the last bit of their trajectories equal to 1 (the same applies to 0). Applying this kind of argument iteratively to the preceding layers will lead to the claim.
Let us observe that choosing two different permutations \(\rho _1\) and \(\rho _2\) of \(2^{g}\) elements will determine two different sets of trajectories, each of them leading to different configurations of output vertices in \(\bar{{G}}\) connected to respective inputs from \(V_{0} = \{v_0^{0}, \ldots , v_{2^{g}-1}^{0}\}\). Thus, as a simple consequence of Lemma 5 we obtain the following corollary.
Corollary 1
There is one-to-one correspondence between the set \(\mathbb {S}_2^{g}\) of permutations of \(2^g\) elements determining the trajectories of input vertices in N-Double-Riffle-Graph and the positions of endpoint vertices from \(V_{g}\) connected with consecutive input vertices from \(V_{0}\) in the graph \(\bar{{G}}\) defined in Lemma 5.
In order to provide a pebbling-based argument on memory hardness of the \(\textsf {RiffleScrambler}\), we need the result on the structure of N-Double-Riffle-Graph given by the following Lemma 6, which is somewhat similar to that of Lemma 4 from [12].
Lemma 6
Let \({G}\) be an N-Double-Riffle-Graph with \(2^{g}\) input vertices. Then there is no such pairs of trajectories that if in some layer \(1 \le i \le g\) the vertices \(v_{k}^{i-1}\) and \(v_{l}^{i-1}\) on that trajectories are connected with some \(v_{k'}^{i}\) and \(v_{l'}^{i}\) (i.e., they form a size-1 switch) on the corresponding trajectories, there is no \(0< j < i\) such that the predecessors (on a given trajectory) of \(v_{k}^{i-1}\) and \(v_{l}^{i-1}\) are connected with predecessors of \(v_{k'}^{i}\) and \(v_{l'}^{i}\).
Proof
Assume towards contradiction that such two trajectories exist and denote by v and w the input vertices on that trajectories. For the sake of simplicity we will denote all the vertices on that trajectories by \(v^{i}\) and \(w^{i}\), respectively, where i denotes the row of \(\mathcal {G}\). Let j and k be the rows such that \(v^j, v^{j+1}, w^{j}, w^{j+1}\) and \(v^k, v^{k+1}, w^{k}, w^{k+1}\) are connected forming two size-1 switches. Without loss of generality, let \(j < k\). Define the trajectories of v and w as
-
\(P_v = b_0^v b_1^v \ldots b_{j-1}^{v} b b_{j+1}^{v} \ldots b_{k-1}^{v} b' b_{k+1}^{v} \ldots b_{g}^{v}\) and
-
\(P_w = b_0^w b_1^w \ldots b_{j-1}^{w} \bar{b} b_{j+1}^{w} \ldots b_{k-1}^{w} \bar{b'} b_{k+1}^{w} \ldots b_{g}^{w}\).
Consider another two trajectories, namely
-
\(P_v^{*} = b_0^v b_1^v \ldots b_{j-1}^{v} \bar{b} b_{j+1}^{w} \ldots b_{k-1}^{w} \bar{b'} b_{k+1}^{v} \ldots b_{g}^{v}\) and
-
\(P_w^{*} = b_0^w b_1^w \ldots b_{j-1}^{w} b b_{j+1}^{v} \ldots b_{k-1}^{v} b' b_{k+1}^{w} \ldots b_{g}^{w}\).
Clearly, \(P_v \ne P_v^{*}\) and \(P_w \ne P_w^{*}\). Moreover, one can easily see that \(P_v\) and \(P_v^{*}\) move \(v^0\) to \(v^g\), \(P_w\) and \(P_w^{*}\) move \(w^0\) to \(w^g\). Since other trajectories are not affected when replacing \(P_u\) with \(P_u^{*}\) for \(u \in \{v,w\}\), such replacement does not change the order of vertices in \(g^\mathrm {th}\) row. If \(P_v\) and \(P_w\) differ only on positions j and k, then \(P_v = P_w^{*}\) and \(P_w = P_v^{*}\), what leads to two different sets of trajectories resulting in the same correspondence between vertices from rows 0 and g. This contradicts Corollary 1. Otherwise, there exist another two trajectories \(P_x = P_v^{*}\) and \(P_y = P_w^{*}\). However, in such situation, from Lemma 5 it follows that \(x^{0}\) and \(v^{0}\) should be moved to the same vertex \(x^{g} = v^{g}\), but this is not the case (similar holds for y and w). Thus, the resulting contradiction finishes the proof.
Being equipped with the lemmas introduced above, we can now proceed with the proof of Theorem 5.
Proof
(of Theorem 5). We need to show that for every \(k: 1 \le k \le G\) and for every pair of subsets \(V_{in} \subseteq \{v_0^0, \ldots , v_{2^g-1}^0\}\) and \(V_{out} \subseteq \{v_0^{2g}, \ldots , v_{2^g-1}^{2g}\}\), where \(|V_{in}| = |V_{out}| = k\) there are k vertex-disjoint paths connecting vertices in \(V_{in}\) to the vertices in \(V_{out}\).
The reasoning proceeds in a similar vein to the proofs of Theorems 1 and 2 from [12]. Below we present an outline of the main idea of the proof.
Let us notice that it is enough to show that for any \(V_{in}\) of size k there exists k vertex-disjoint paths that connect vertices of \(V_{in}\) to the vertices of \(V_{middle} \subseteq \{v_0^{g}, \ldots , v_{2^g-1}^{g}\}\) with vertices of \(V_{middle}\) forming a line, i.e., either:
-
\(V_{middle} = \{v_i^g, v_{i+1}^g, \ldots , v_{i+k-1}^g\}\) for some i,
-
or \(V_{middle} = \{v_0^g, \ldots , v_{i-1}^g\} \cup \{v_{2^g-k+i}^g, \ldots , v_{2^g-1}^g\}\).
If the above is shown, we obtain the claim by finding vertex-disjoint paths between \(V_{in}\) and \(V_{middle}\) and then from \(V_{middle}\) to \(V_{out}\) from the symmetry of G-Double-Riffle-Graph.
Fix \(1 \le k \le G\) and let \(V_{in}\) and \(V_{out}\) be some given size-k subsets of input and output vertices, respectively, as defined above. From Lemma 6 it follows that if some two vertices x and y are connected in \(i^\mathrm {th}\) round forming a size-1 switch then they will never be connected again until round g. Thus, the paths from x and y can move according to different bits in that round, hence being distinguished (they will share no common vertex). Having this in mind, we can construct the nodes-disjoint paths from \(V_{in}\) to \(V_{middle}\) in the following way. Starting in vertices from \(V_{in}\), the paths will move through the first \(t = \left\lceil \log k \right\rceil \) rounds according to all distinct t-bits trajectories. Then, after round t, we will choose some fixed \(g-t\)-sequence \(\tau \) common for all k paths and let them follow according \(\tau \). Lemma 5 implies that the k paths resulting from the construction described above after g steps will eventually end up in some subset \(V_{middle}\) of k vertices forming a line, whereas Lemma 6 ensures that the paths are vertex-disjoint.
5 Summary
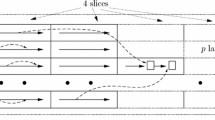
We presented a new memory hard function which can be used as a secure password-storing scheme. \(\textsf {RiffleScrambler}\) achieves better time-memory trade-offs than Argon2i and Balloon Hashing when the buffer size n grows and the number of rounds r is fixed (and the same as Catena-DBG) (Fig. 4).

Comparison of the efficiency and security of BalloonHashing (\(BHG_3\) is BalloonHashing with \(\delta = 3\) and \(BHG_7\) is BHG graph for \(\delta = 7\)), Argon2i, Catena (with Butterfly graph) and \(\textsf {RiffleScrambler}\) (RSG).
On the other hand, in the case of massively-parallel adversaries the situation of Catena is much worse than \(\textsf {RiffleScrambler}\). In Catena, only double-butterfly graph (Catena-DBG) offered a time-memory trade-off which depends on the number of layers of the graph. Unfortunately, Catena-DBG is just a single graph instance, so in theory an adversary may try to build a parallel hardware to achieve better trade-off. In the case of \(\textsf {RiffleScrambler}\) the time-memory trade-off is the same as for the Catena-DBG but for \(\textsf {RiffleScrambler}\), a different salt corresponds (with high probability) to the computation on a different (one from N!) graph. So an adversary cannot build just a single device for cracking all passwords (as in the case of Catena).
References
Password Hashing Competition. https://password-hashing.net/
The Antminer S9 Bitcoin Miner - Bitmain. https://shop.bitmain.com/ antminer_s9_asic_bitcoin_miner.htm
yescrypt - a Password Hashing Competition submission. Technical report (2014). https://password-hashing.net/submissions/specs/yescrypt- v2.pdf
Aldous, D., Diaconis, P.: Shuffling cards and stopping times. Am. Math. Mon. 93(5), 333–348 (1986). http://www.jstor.org/stable/2323590
Aldous, D., Diaconis, P.: Strong uniform times and finite random walks. Adv. Appl. Math. 97, 69–97 (1987)
Alwen, J., Blocki, J.: Efficiently computing data-independent memory-hard functions. In: Robshaw, M., Katz, J. (eds.) CRYPTO 2016. LNCS, vol. 9815, pp. 241–271. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-53008-5_9
Alwen, J., Blocki, J.: Towards practical attacks on Argon2i and balloon hashing. In: 2017 IEEE European Symposium on Security and Privacy (EuroS&P), pp. 142–157. IEEE, April 2017. http://ieeexplore.ieee.org/document/7961977/
Alwen, J., Blocki, J., Pietrzak, K.: Depth-robust graphs and their cumulative memory complexity. In: Coron, J.-S., Nielsen, J.B. (eds.) EUROCRYPT 2017. LNCS, vol. 10212, pp. 3–32. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-56617-7_1
Alwen, J., Serbinenko, V.: High parallel complexity graphs and memory-hard functions. In: Proceedings of the Forty-Seventh Annual ACM on Symposium on Theory of Computing - STOC 2015, pp. 595–603. ACM Press, New York (2015). http://dl.acm.org/citation.cfm?doid=2746539.2746622
Biryukov, A., Dinu, D., Khovratovich, D.: Argon2: new generation of memory-hard functions for password hashing and other applications. In: 2016 IEEE European Symposium on Security and Privacy (EuroS&P), pp. 292–302. IEEE, March 2016. http://ieeexplore.ieee.org/document/7467361/
Boneh, D., Corrigan-Gibbs, H., Schechter, S.: Balloon hashing: a memory-hard function providing provable protection against sequential attacks. In: Cheon, J.H., Takagi, T. (eds.) ASIACRYPT 2016. LNCS, vol. 10031, pp. 220–248. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-53887-6_8
Bradley, W.F.: Superconcentration on a pair of butterflies, January 2017. http://arxiv.org/abs/1401.7263
Burt, K.: PKCS #5: password-based cryptography specification version 2.0. Technical report (2000). https://tools.ietf.org/html/rfc2898
Forler, C., Lucks, S., Wenzel, J.: Catena: a memory-consuming password-scrambling framework. citeseerx.ist.psu.edu/viewdoc/download?https://doi.org/10.1.1.437.9101&rep=rep1&type=pdf
Forler, C., Lucks, S., Wenzel, J.: The Catena Password-Scrambling Framework (2015). https://password-hashing.net/submissions/specs/Catena- v5.pdf
Lengauer, T., Tarjan, R.E.: Asymptotically tight bounds on time-space trade-offs in a pebble game. Journal of the ACM 29(4), 1087–1130 (1982). http://portal.acm.org/citation.cfm?doid=322344.322354
Percival, C.: Stronger Key Derivation Via Sequential Memory-hard Functions. https://www.bsdcan.org/2009/schedule/attachments/ 87_scrypt.pdf
Pornin, T.: The MAKWA password hashing function specifications v1.1 (2015). http://www.bolet.org/makwa/makwa-spec-20150422.pdf
Simplicio, M.A., Almeida, L.C., Andrade, E.R., Dos Santos, P.C.F., Barreto, P.S.L.M.: Lyra2: password hashing scheme with improved security against time-memory trade-offs. https://eprint.iacr.org/2015/136.pdf
Wang, D., Cheng, H., Wang, P., Huang, X., Jian, G.: Zipf’s law in passwords. IEEE Trans. Inf. Forensics Secur. 12(11), 2776–2791 (2017). http://ieeexplore.ieee.org/document/7961213/
Wang, D., Zhang, Z., Wang, P., Yan, J., Huang, X.: Targeted online password guessing. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security - CCS 2016, pp. 1242–1254. ACM Press, New York (2016). http://dl.acm.org/citation.cfm?doid=2976749.2978339
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
A Markov Chains, Mixing Times, Strong Stationary Times
Consider an ergodic Markov chain \(\mathbf {X}=\{X_k, k\ge 0\}\) on a finite state space \(\mathbb {E}\) with stationary distribution \(\pi \). Ergodicity implies that \(d_{TV}(\mathcal {L}(X_k),\pi )\rightarrow 0\) (total variation distance) as \(k\rightarrow \infty \), where \(\mathcal {L}(X_k)\) is the distribution of the chain at step k. Define
often called total variation mixing time.
Perfect Simulation and Strong Stationary Times. Perfect simulation refers to the art of converting an algorithm for running a Markov chain into an algorithm which returns an unbiased sample from its stationary distribution. Coupling from the past (CFTP) is one of the most known ones. However, it is not applicable to our models. Another method is based on strong stationary times (SSTs), a method whose prime application is studying the rate of convergence (of a chain to its stationary distribution).
Definition 14
A stopping time is a random variable \(T\in \mathbb {N}\) such that the event \(\{T=k\}\) depends only on \(X_0,\ldots ,X_k\). A stopping time T is a strong stationary time (SST) if
Due to [5],we have
Remark 1
An SST T can be non-randomized, i.e., an event \(\{T=k\}\) depends only on on the path \(X_0,\ldots , X_k\) and does not use any extra randomness (which is the case for randomized SST). For non-randomized SST performing perfect simulation is relatively easy: simply run the chain \(X_k\) until event T occurs and stop. Then \(X_T\) has distribution \(\pi \).
Obtaining a Random Permutation: SST for Riffle Shuffle. In our applications we will need a random permutation of N elements. We can think of these elements as of cards, and of a chain on permutations as of card shuffling. Consider the following shuffling scheme (one step of a corresponding Markov chain):
For each card in the deck, flip a coin and label the back of the card with 0 (if Heads occurred) or with 1 (if Tails occurred). Take all the cards labeled 1 out of the deck and put them on the top keeping their relative ordering.
This is the inverse Riffle Shuffle. The following rule is an SST for this shuffling (due to Aldous and Diaconis [4]):
Keep track of assigned bits (storing a sequence of assigned bits for each card). Stop when all the sequences are different.
Once stopped, we have a permutation obtained from exactly uniform distribution (which is the stationary distribution of this chain). On average, this takes \(2 \log _2 N\) steps. What we considered was an idealized model, in a sense that if we use some shuffling scheme in cryptography, we do not have an infinite sequence of random numbers. In reality we must obtain them in a deterministic way, e.g., from a private key or a salt (depending on applications). In our constructions, it depends on some salt s and some hash function H. The Algorithm 1 called \(\textsf {RiffleShuffle}_H(n, s)\) takes as input a salt s, a hash function H and the number of elements n. It performs inverse Riffle Shuffle (with randomness obtained from salt s and hash function H) until above SST event occurs. Thus, its output is a random permutation of \(\{1,\ldots ,n\}\) (in the random-oracle model).
B Parallel Attacks
In this section we formulate lemmas which are used to prove Lemma 4.
These lemmas follow directly the proof of parallel security of Catena presented in [8]. The proof technique is exactly the same as in [8] since \(\mathsf {RSG}_{\lambda }^k\) is a Superconcentrator. The only difference comes from the fact that each stack of Catena (Butterfly) is built out of \(2g-1\) layers while \(\mathsf {RSG}_{\lambda }^k\) is built from 2g layers. First, let us collect some observations on \(\mathsf {RSG}_{\lambda }^k\).
Lemma 7
Let \(\lambda , n \in \mathbb {N}^{+}\) such that \(n = n' (2 c \lambda +1)\) where \(n' = 2^c\) for some \(c \in \mathcal {N}^{+}\). Then the Riffle Shuffle graph \(\mathsf {RSG}_{\lambda }^k\) consists of a stack \(\lambda \) sub-graphs such that the following holds.
-
1.
The graph \(\mathsf {RSG}_{\lambda }^k\) has n nodes in total.
-
2.
The graph \(\mathsf {RSG}_{\lambda }^k\) is built as a stack of \(\lambda \) sub-graphs \(\{G_i\}_{i \in [\lambda ]}\) each of which is a Superconcentrator. In the unique topological ordering of \(\mathsf {RSG}_{\lambda }^k\) denote the first and final \(n'\) nodes of each \(G_i\) as \(L_{i,0}\) and \(L_{i,1}\) respectively. Then there is a path running through all nodes in each \(L_{i,1}\).
-
3.
Moreover, for any \(i \in [\lambda ]\) and subsets \(S \subset L_{i,0}\) and \(T \subset L_{i,1}\) with \(|S| = |T| = h \le n'\) there exist h nodes-disjoint paths \(p_1, \ldots , p_h\) of length 2c from S to T.
Using Lemma 7 and following the proof of Lemma 6 in [8] we obtain the following lemma.
Lemma 8
Let \(\lambda , n \in \mathbb {N}^{+}\) be such that \(n = n' (2 \lambda c + 1)\) with \(n' = 2^c\) for some \(c \in \mathcal {N}^{+}\). Then it holds that \(\mathsf {RSG}_{\lambda }^k\in \mathcal {D}_{1, g}^{\lambda , n'}\) for \(g = \lceil \sqrt{n'}\rceil \).
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Gotfryd, K., Lorek, P., Zagórski, F. (2018). RiffleScrambler – A Memory-Hard Password Storing Function. In: Lopez, J., Zhou, J., Soriano, M. (eds) Computer Security. ESORICS 2018. Lecture Notes in Computer Science(), vol 11099. Springer, Cham. https://doi.org/10.1007/978-3-319-98989-1_16
Download citation
DOI: https://doi.org/10.1007/978-3-319-98989-1_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-98988-4
Online ISBN: 978-3-319-98989-1
eBook Packages: Computer ScienceComputer Science (R0)