
Abstract
Complex applications orchestrate multiple components and services, which are independently managed by different teams (e.g., DevOps squads). As a consequence, various services may happen to be updated, reconfigured or redeployed concurrently, possibly yielding unexpected/undesired management effects. In this paper, we show how the true concurrent management of multi-component applications can be suitably modelled, analysed and automated, also in presence of faults.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



1 Introduction
The efficient exploitation of cloud computing peculiarities depends on the degree of management automation of the applications shipped to cloud platforms [20]. As cloud applications typically integrate various heterogeneous components, the problem of automating the management of multi-component applications is currently one of the major concerns in enterprise IT [21].
To automate the management of a multi-component application, the concurrent deployment, configuration, enactment and termination of its components must be properly coordinated. Even if this may be done by different independent teams (e.g., DevOps squads), it must be done by considering all dependencies occurring among the components of an application. As the number of components grows, and the need to reconfigure them becomes more frequent, application management becomes more time-consuming and error-prone [5].
The components forming a multi-component application, as well as the dependencies occurring among such components, can be conveniently represented by means of topology graphs [3]. A component is represented as a node in a topology graph, while a dependency between two components can be represented by an arc interconnecting the corresponding two nodes. More precisely, each node models an application component by indicating the operations to manage it, its requirements, and the capabilities it offers to satisfy the requirements of other nodes. Each oriented arc models the dependency of a component on another, by connecting a requirement of the former to a capability of the latter.
Management protocols [6, 7] enable the modelling and analysis of the management of multi-component applications, faults included. Each node is equipped with its own management protocol, i.e., a finite state machine whose transitions and states are associated with conditions on the requirements and capabilities of such node. Conditions on transitions indicate which requirements must be satisfied to perform a management operation. Conditions on states define state consistency, by indicating which requirements of a node must be satisfied in a state, as well as which capabilities the node is actually providing in such state. Management protocols also allow indicating how a node reacts to faults, which occur whenever the condition of consistency of a state is violated. The management behaviour of a multi-component application can then be derived by composing the management protocols of its nodes (according to the interconnections defined in its topology). The obtained behaviour can be exploited to automate various useful analyses, from checking whether a management plan is valid, to automatically determining management plans allowing to recover applications that are stuck because of mishandled faults or because of components behaving differently than expected.
Management protocols (as per [6, 7]) rely on an interleaving semantics. Transitions are considered as atomic, and consistency is only checked on states. This means that management protocols do not support the analysis of the true concurrent execution of management operations. Consider for instance the concurrent reconfiguration of two components, with one component requiring a capability of the other to successfully complete its reconfiguration. The latter may however stop providing the desired capability during the execution of its reconfiguration operation, even if such capability is provided right before and after executing such operation. While this may result in one of the two reconfiguration operations failing, an interleaving semantics (checking consistency only on states) would not be able to detect such failure.
In other words, faults can happen both after and during the concurrent execution of management operations [9]. In this paper, we extend management protocols to permit indicating how nodes react to faults happening while transiting from one state to another. We then show how to derive the management behaviour of a multi-component application by considering the true concurrent execution of the management operations of its components, and how this enables the analysis and automation of their concurrent management.
The rest of this paper is organised as follows. Section 2 illustrates an example motivating the need for extending management protocols to support true concurrency. The extension is then presented in Sect. 3, and Sect. 4 shows how to use it to analyse the true concurrent management behaviour of applications. Sections 5 and 6 discuss related work and draw some concluding remarks, respectively.
2 Motivating Example
Consider the web application in Fig. 1. The frontend of the application is implemented in JavaScript, it is hosted on a node container, and it exploits a backend component to provide its functionalities. The backend component is instead implemented in Java, it is hosted on a maven container, and it manages the application data stored by a mongo container.

Topology of the application in our motivating example. The topology is depicted according to the TOSCA graphical notation [18].

Three management plans for reconfiguring backend and frontend, depicted by following the BPMN graphical notation [19].
Figure 1 explicitly represents the requirements and capabilities of the components of the considered application, the management operations they offer, as well as all inter-component dependencies. The latter are represented as relationships connecting each requirement of each node with the capability satisfying such requirement (e.g., the requirements host and conn of frontend are connected with the homonym capabilities of node and backend, respectively).
Suppose now that we wish to orchestrate the re-configuration of the frontend and backend of our application, by developing a dedicated management plan to be executed when the application is up and running. It is easy to see that one may end up in producing invalid management plans. For instance, while Fig. 2 illustrates three seemingly valid plans, only (b) and (c) are valid. Plan (a) is not valid because the concurrent execution of the operations config of frontend and backend may cause a failure in frontend. frontend indeed requires the endpoint offered by backend to successfully complete its config operation. However, backend stops providing its endpoint during the execution of its config operation. This means that the concurrent execution of both operations may result in a failure of frontend, which may not successfully complete its config operation.
The above issue is not recognised even if application components are equipped with the management protocols in [6, 7] to describe their management behaviour. Management protocols currently support an analysis of the management of applications based on an interleaving semantics, which prescribes to analyse plan (a) by considering all its sequential traces (differently interleaving concurrently performed operations). As such traces correspond to the valid management plans (b) and (c), we would end up in considering also plan (a) as valid.
We however know that (a) is not valid, because of the fault that can occur during the true concurrent execution of the operations to configure frontend and backend. Such fault is due to a node stopping to provide its capabilities, while another node is actually relying on such capabilities during the execution of one of its management operations. Management protocols must hence be extended by allowing to indicate how nodes react to the occurrence of a fault while executing a management operation, as this would enable the modelling and analysis of the true concurrent management of multi-component applications.
3 Modelling True Concurrent Management Protocols
Multi-component applications are typically represented by indicating the states, requirements, capabilities and management operations of the nodes composing their topology [3]. Management protocols allow specifying the management behaviour of the nodes composing an application, by indicating the behaviour of the management operations of a node, their relations with its states, requirements and capabilities, and how a node reacts to a failure in a state.
We hereby present an extension of management protocols, geared towards enabling the analysis of a true concurrent management of the components of an application. Intuitively speaking, the essence of the extension is to consider the execution of management operations as transient states, instead of as atomic transitions. The extension indeed allows to indicate which capabilities are concretely maintained during a transition, which requirements are needed to continue to perform a transition, and how a node reacts when a failure happens while executing a transition.
Management protocols allow specifying the management behaviour of a node N (modelling an application component), by indicating (i) whether/how each management operation of N depends on other management operations of N, (ii) whether/how it depends on operations of the nodes that provide capabilities satisfying the requirements of N, and (iii) how N reacts when a fault occurs.
Dependencies of type (i) are described by relating the management operations of N with its states. A transition relation  indeed describes the order of execution of the operations of N, by indicating whether a given management operation can be executed in a state of N, and which state is reached if its execution is successfully completed.
indeed describes the order of execution of the operations of N, by indicating whether a given management operation can be executed in a state of N, and which state is reached if its execution is successfully completed.
Dependencies of type (ii) are instead described by associating (possibly empty) sets of requirements with both states and transitions. The requirements associated with a state/transition of N must continue to be satisfied in order for N to continue to work properly (i.e., to continue to reside in a state/to successfully complete the execution of a management transition). As a requirement is satisfied when the corresponding capability is provided, the requirements associated with states and transitions actually indicate which capabilities must continue to be provided in order for N to continue to work properly. The description of a node N is then completed by associating its states and transitions with (possibly empty) sets of capabilities that indicate the capabilities that are actually provided by N while residing in a state and while executing a transition.
Finally, faults occur when N is in a state/transition assuming some requirements to be satisfied, and one or more of the capabilities satisfying such requirement stop being provided by the corresponding nodes. To describe (iii), i.e., how N reacts to faults, a transition relation \(\varphi _N\) models the explicit fault handling of N, by indicating the state it reaches when a fault occurs while it is residing in a state or executing a transition.
Definition 1 (Management protocols)
Let \(N = \langle S_N, R_N, C_N,\)  be a node, where \(S_N\), \(R_N\), \(C_N\), and \(O_N\) are the finite sets of its states, requirements, capabilities, and management operations.
be a node, where \(S_N\), \(R_N\), \(C_N\), and \(O_N\) are the finite sets of its states, requirements, capabilities, and management operations.  is a finite state machine defining the management protocol of N, where:
is a finite state machine defining the management protocol of N, where:
-
\(\overline{s}_N \in S_N\) is the initial state,
-
 models the transition relation,
models the transition relation, -
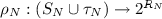 indicates which requirements must hold in each state \(s \in S_N\) and during each transition
indicates which requirements must hold in each state \(s \in S_N\) and during each transition  ,
, -
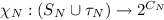 indicates which capabilities of N are offered in each state \(s \in S_N\) and during each transition
indicates which capabilities of N are offered in each state \(s \in S_N\) and during each transition 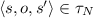 , and
, and -
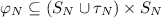 models the fault handling for a node.
models the fault handling for a node.
 models the transition relation,
models the transition relation,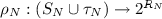 indicates which requirements must hold in each state
indicates which requirements must hold in each state  ,
,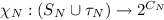 indicates which capabilities of N are offered in each state
indicates which capabilities of N are offered in each state 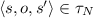 , and
, and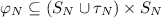 models the fault handling for a node.
models the fault handling for a node.
Management protocols of (a) frontend, (b) backend, (c) node and maven, and (d) mongo. White circles represent states, solid arrows and black circles represent management transitions, and dashed arrows represent fault handling transitions. Labels in bold indicate names of states/operations, while R and C indicate the sets of requirements and capabilities associated with states and transitions.
Example
The management protocols of the components of the application in our motivating example are illustrated in Fig. 3.
Consider the management protocol (b), which describes the management behaviour of backend. The states of backend are unavailable (initial), available, running and damaged. No requirements and capabilities are associated with states unavailable, available and damaged, which means that backend does not require nor provide anything in such states. The same does not hold for the running state, which is the only state where backend concretely provides its conn capability, and where backend assumes its host requirement to continue to be satisfied. If host is faulted while backend is running, backend goes back to its available state.
The transitions of the management protocol of backend indicate that all its operations need the host requirement to be satisfied during their execution, and that they do not feature any capability while being executed. If host is faulted while executing start or stop, backend enters in its state available. If host is instead faulted while executing install, uninstall or config, backend gets damaged. \(\square \)
It is worth noting that (as per Definition 1) management protocols allow to introduce some inconsistencies and non-determinism while being defined. To inhibit concerns due to such a kind of inconsistencies/non-determinism, we assume management protocols to enjoy some basic properties, i.e., we assume them to be well-formed, deterministic, race-free and completeFootnote 1.
4 Analysing True Concurrent Application Management
In this section, we illustrate how the true concurrent management behaviour of a multi-component application can be determined by composing the protocols of its nodes according to the application topology (Sect. 4.1). We also describe how to exploit such management to analyse and automate the concurrent management of multi-component applications, faults included (Sect. 4.2).
4.1 True Concurrent Management Behaviour of Applications
Consider a multi-component application \(A = \langle T, b\rangle \), where T is the finite set of nodes in the application topology, and where the (total) binding function
describes the connection among the nodes in T, by associating each requirement of each node with the capability that satisfies such requirementFootnote 2.
The true concurrent management behaviour of A is defined by a labelled transition systems over configurations that denote the states of the nodes in T. We first define the notion of global state for a multi-component application, which denotes the current situation of each node N forming an application, where each N is either residing in one of its states or executing a management operation.
Definition 2 (Global state)
Let \(A = \langle T, b\rangle \) be a multi-component application, and let  be the tuple corresponding to a node \(N \in T\), with
be the tuple corresponding to a node \(N \in T\), with  . A global state G of A is defined as:
. A global state G of A is defined as:

Remark 1
The right hand condition in Definition 2 ensures that a global state G contains exactly one state/transition for each node in T. This is because a node cannot be in two different situations at the same time, i.e., it cannot be in two different states, nor it can simultaneously execute two different operations, nor it can be both residing in a state and simultaneously executing an operation. \(\square \)
We also define a function \(F\) to denote the set of pending faults in a global state \(G\). The latter is the set of requirements that are assumed in \(G\) even if the corresponding capabilities are not provided.
Notation. Let \(G\) be a global state of a multi-component application \(A = \langle T, b\rangle \). We denote with \(\rho (G)\) the set of requirements assumed to hold by the nodes in T when A is in \(G\), and with \(\chi (G)\) the set of capabilities provided by such nodes in \(G\). Formally:
-
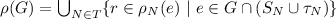 , and
, and -
 .
.
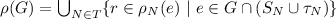 , and
, and .
.Definition 3 (Pending faults)
Let \(A = \langle T, b \rangle \) be a multi-component application, and let \(G\) be a global state of A. The set of pending faults in \(G\), denoted by \(F(G)\), is defined as:
\(F(G) = \{ r \in \rho (G) ~|~ b(r) \not \in \chi (G) \}\).
The management behaviour of a multi-component application \(A = \langle T, b\rangle \) can then be defined as a labelled transition system, whose configurations are the global states of A. The transition system is characterised by three inference rules, namely \( op _{ start }\) and \( op _{ end }\) for operation execution and \( fault \) for fault propagation. Rule \( op _{ start }\) models the start of the execution of a management operation o on a node \(N \in T\), which can happen only when there are no pending faults and all the requirements needed by N to perform o are satisfied (by the capabilities provided by other nodes in T). Rule \( op _{ end }\) instead models the successful completion of the execution of a management operation, also happening when there are no pending faults. Finally, rule \( fault \) models the execution of fault handling transitions to handle pending faults.
Definition 4 (True concurrent management behaviour)
Let \(A = \langle T, b\rangle \) be a multi-component application, and let \(\langle S_N, R_N, C_N,\)  be the tuple corresponding to a node \(N \in T\), with
be the tuple corresponding to a node \(N \in T\), with  . The true concurrent management behaviour of A is modelled by a labelled transition system whose configurations are the global states of A, and whose transition relation is defined by the following inference rules:
. The true concurrent management behaviour of A is modelled by a labelled transition system whose configurations are the global states of A, and whose transition relation is defined by the following inference rules:

Rules \( op _{ start }\) and \( op _{ end }\) indicate how to update the global state of an application A when a node N starts executing a transition  and when such transition terminates, respectively. Both rules can be applied in a global state \(G\) only if there are no pending faults (i.e., \(F(G) = \varnothing \)). Rule \( op _{ start }\) updates the global state by changing current state of N from s to the transient state corresponding to \(\langle s, o, s' \rangle \) (i.e., \(G' = (G- \{s\}) \cup \{\langle s, o, s' \rangle \}\)). Rule \( op _{ end }\) instead updates the global state by changing current state of N from the transient state corresponding to \(\langle s, o, s' \rangle \) to \(s'\) (i.e., \(G' = (G- \{\langle s, o, s' \rangle \}) \cup \{s'\}\)). Both updates may also result in triggering novel faults to be handled (if \(F(G') \ne \varnothing \)).
and when such transition terminates, respectively. Both rules can be applied in a global state \(G\) only if there are no pending faults (i.e., \(F(G) = \varnothing \)). Rule \( op _{ start }\) updates the global state by changing current state of N from s to the transient state corresponding to \(\langle s, o, s' \rangle \) (i.e., \(G' = (G- \{s\}) \cup \{\langle s, o, s' \rangle \}\)). Rule \( op _{ end }\) instead updates the global state by changing current state of N from the transient state corresponding to \(\langle s, o, s' \rangle \) to \(s'\) (i.e., \(G' = (G- \{\langle s, o, s' \rangle \}) \cup \{s'\}\)). Both updates may also result in triggering novel faults to be handled (if \(F(G') \ne \varnothing \)).
The fault rule instead models fault propagation, by indicating how to update the global state of an application A when executing a fault handling transition \(\langle e, s' \rangle \) of a node N. Such transition can be performed only if the following conditions hold:
-
\(\rho _N(e) \cap F(G) \ne \varnothing \), which means that some of the requirements assumed by N in e are faulted,
-
\(\rho _N(s') \subseteq (\rho _N(e) - F(G))\), which ensures that \(\langle e, s' \rangle \) handles all faults pending in \(G\) and affecting N, and
-
\(\not \exists \langle e, s'' \rangle \in \varphi _N. \ \rho (s') \subsetneq \rho (s'') \wedge \rho (s'') \subseteq \rho (e) - F(G)\), which ensures that, among all executable fault handling transitions, \(\langle e, s' \rangle \) is the transition whose target state \(s'\) assumes the biggest set of requirementsFootnote 3.
4.2 Analysing True Concurrent Management Plans
The modelling of the management behaviour of a multi-component application A (Sect. 4.1) sets the foundation for analysing its true concurrent management. To concretely perform such analysis, we introduce a “simple profile” of the labelled transition system modelling the management behaviour of A. The objective of the simple profile is to observe only the start and termination of management operations, by hiding all transitions corresponding to fault reaction/propagation, and by considering operations as terminated if they completed with success or if their execution has faulted.
Definition 5 (Simple profile of management behaviour)
Let \(A = \langle T, b\rangle \) be a multi-component application, and let \(\langle S_N, R_N, C_N,\)  be the tuple corresponding to a node \(N \in T\), with
be the tuple corresponding to a node \(N \in T\), with  . The simple profile of the true concurrent management behaviour of A is modelled by a labelled transition system whose configurations are global states of A, and whose transition relation is defined by the following inference rules:
. The simple profile of the true concurrent management behaviour of A is modelled by a labelled transition system whose configurations are global states of A, and whose transition relation is defined by the following inference rules:

Rules \( op _{ init }\) and \( op _{ success }\) model the start and successful completion of a management operation o, respectively. Rules \( op _{ fault }\) and \( absorption \) differentiate the observation of faults. Rule \( op _{ fault }\) allows to observe faults on management operations, to consider the execution of such operations as terminated. Rule \( absorption \) instead hides all fault handling transitions executed to react to the faults on states due to the execution of an action \(\alpha \) (corresponding to the start \({\bullet }o\) or termination \(o{\bullet }\) of a management operation o).
The simple profile of the management behaviour of a multi-component application A enables the analysis of plans orchestrating its management. A management plan \(P_A\) defines a partial ordering on the management operations of the nodes in A (i.e., it indicates which operations must be completed before starting the execution of another operation). The partial ordering can be visualised as a DAG, whose nodes model the start/termination of an operation, and where each arc indicates that the action corresponding to its source node must be executed before that corresponding to its target node. The DAG also models the obvious fact that \({\bullet }o\) always occurs before \(o{\bullet }\), for each operation o in the plan.
Example
Consider the management plan in Fig. 2(a). Such plan indicates that stop frontend must be completed before executing config frontend and config backend, which can then be executed concurrently, and which must both be completed before starting the execution of start frontend. The corresponding partial ordering is displayed as a DAG in Fig. 4. \(\square \)

DAG defined by the management plan in Fig. 2(a).
The validity of a management plan \(P_A\) can be defined in terms of all possible sequencing of \({\bullet }o\) and \(o{\bullet }\) (for each operation o in \(P_A\)), which respects the ordering constraints defined in \(P_A\), as well as that \({\bullet }o\) must obviously always occur before \(o{\bullet }\). Such sequences correspond to the topological sorts of the DAG modelling the partial order defined by \(P_A\).
Definition 6 (Valid plan)
Let \(A = \langle T, b\rangle \) be a multi-component application. The sequence \(\alpha _1\alpha _2...\alpha _n\) (with \(\alpha _i \in \{ {\bullet }o, o{\bullet } \ | \ o \in O_N, N \in T \}\)) is a valid management sequence in a global state \(G_0\) of A iff

A management plan \(P_A\) is valid in \(G_0\) iff all its sequential tracesFootnote 4 are valid management sequences in \(G_0\).
Example
Consider again the management plans in our motivating scenario (Fig. 2). While one can readily check that the sequential plans (b) and (c) are valid, the same does not hold for plan (a).
The sequential traces of plan (a) correspond to all possible topological sorts of the DAG in Fig. 4. One of such traces is hence the following:

If executed when all components of the application in our motivating scenario are up and running, the above trace corresponds to the evolution of global states in Fig. 5. From the figure we can observe that the execution of  causes a failure in the node frontend. The handling of such failure results in frontend getting to its installed state, where it cannot perform
causes a failure in the node frontend. The handling of such failure results in frontend getting to its installed state, where it cannot perform  (i.e., it cannot start executing the operation start —Fig. 3(a)). This means that the considered sequential trace is not valid, hence the management plan in Fig. 2(a) is not valid either. \(\square \)
(i.e., it cannot start executing the operation start —Fig. 3(a)). This means that the considered sequential trace is not valid, hence the management plan in Fig. 2(a) is not valid either. \(\square \)

Evolution of the application in our motivating example, corresponding to the execution of a sequential trace of the management plan in Fig. 2 (a) when the application is up and running. Global states and pending faults are represented as tables associating node names with their actual state, and with their faulted requirements, respectively. Transitions are displayed as labelled arrows, and each update due to the execution of a transition is highlighted in grey in the target global state.
It is worth noting that the notion of validity for management plans (Definition 6) is the natural adaptation of the corresponding notion in [7] to consider the true concurrent execution of management operations. A similar approach can be used to naturally adapt all analyses presented in [7], from checking whether management plans are deterministic or fault-free, to automatically planning the management of applications (e.g., to recover applications that are stuck because a fault was not handled properly, or because misbehaving components)Footnote 5.
5 Related Work
The problem of automating the management of multi-component applications is one of the major concerns in enterprise IT [21]. This is also witnessed by the proliferation of so-called “configuration management systems”, such as Chef (https://www.chef.io) or Puppet (https://puppet.com). Such systems provide domain-specific languages to model the desired configuration for an application, and they employ a client-server model to ensure that such configuration is met. However, the lack of a machine-readable representation of how to effectively manage cloud application components inhibits the possibility of performing automated analyses on their configurations and dependencies.
A first solution for modelling the deployment of multi-component applications was the Aeolus component model [11]. Aeolus [11] shares our idea of describing the management behaviour of the components of an application through finite-state machines, whose states are associated with conditions describing what is offered and required in a state. The management behaviour of an application can then be derived by composing those of its components. Aeolus however differs from our approach as it focuses on automating the deployment and configuration of a multi-component application. Management protocols instead focus on allowing to model and analyse the true concurrent management of a multi-component application, including how its components react to failures, as well as how to recover a multi-component application after one or more of its components were faulted.
Engage [14] takes as input a partial installation specification, and it is capable of determining a full installation plan, which coordinates the deployment and configuration of the components of an application across multiple machines. Engage however differs from our approach since it focuses on determining a fault-free deployment of applications. We instead focus on the true concurrent management of applications, by also allowing to explicitly model faults, analysing their effects, and reacting to them to restore a desired application state.
[12] proposes a fault-resilient solution for deploying and reconfiguring multi-component applications. [12] models a multi-component application as a set of interconnected VMs, each provided with a module managing its lifecycle. An orchestrator then coordinates the deployment and reconfiguration of an application, by interacting with the configurators of the virtual machines of its components. [12] is related to our approach as it focuses managing multi-component applications by taking into account failures and by specifying the management of each component separately. It however differs from our approach since it only considers environmental faults, while we also deal with application-specific faults. Similar considerations apply to the approach proposed in [13].
Other approaches worth mentioning are those related to the rigorous engineering of fault tolerant systems. [4, 22] provide facilities for fault-localisation in complex applications, to support re-designing such applications by avoiding the occurrence of identified faults. [16] illustrates a solution for designing applications by first considering fault-free applications, and by then iteratively refining their design by identifying and handling the faults that may occur. [4, 16, 22] however differ from our approach as their aim is to obtain applications that “never fail”, because potential faults have already been identified and handled. Our approach is instead more recovery-oriented [8], as we consider applications where faults can (and probably will) occur, in order to enable the design of applications that can be recovered.
Similar arguments apply to [2, 15, 17]. They however share with our approach the basic ideas of indicating which faults can affect components, of specifying how components react to faults, and of composing obtained models according to the dependencies occurring among the components of an application (i.e., according to the application topology).
In summary, to the best of our knowledge, ours is the first approach allowing to analyse and automate the management of multi-component applications, by considering that faults can occur during their concrete management. It does so by allowing to customise the management behaviour of each component of an application (including the specification of how it will react to the occurrence of a fault), and by considering the true concurrent management of the components forming an application.
It is finally worth noting that our work was inspired by [10], which illustrates how to provide CCS with a true concurrent semantics. The baseline idea in [10] is to define a partial ordering among the sequential parts of CCS agents, and to exploit such ordering to infer a true concurrent semantics of CCS agents (where concurrency is represented as the absence of ordering). This is closely related to what we did to provide management protocols with a true concurrent semantics, even if we consider additional constraints given by the conditions on requirements and capabilities associated with the states and transitions of management protocols.
It is also worth noting that we also investigated the possibility of employing composition-oriented automata (like interface automata [1]) to model the valid management of an application as the language accepted by the automaton obtained by composing the automata modelling the management protocols of its components. The main drawbacks of such an approach are the size of the obtained automaton (which in general grows exponentially with the number of application components), and the need of recomputing the automaton whenever the management protocol of a component is modified or whenever a new component is added to an application.
6 Conclusions
We presented a solution for modelling, analysing and automating the true concurrent management of multi-component applications. More precisely, we have extended management protocols [7] to permit indicating how application components react to faults occurring while they are executing management operations. We have also shown how to derive the management behaviour of a multi-component application by considering the true concurrent execution of the management operations of its components, and how this enables the analysis and automation of its concurrent management.
The presented extension is a fundamental milestone towards the exploitation of management protocols for a fully asynchronous, distributed coordination of the management of multi-component applications. As components can now evolve asynchronously (with one component executing a management operation while another component is executing another operation), the management of multi-component applications can be decentralised, e.g., by distributing its orchestration over the components forming an application. The investigation of such a kind of solutions is in the scope of our future work.
In the scope of our future work we also plan to follow two other interesting directions. On the one hand, we plan to validate our approach by implementing a prototype supporting the modelling and analysis of true concurrent management protocols, and by assessing our approach with case studies and controlled experiments, similarly to what we did in [7]. On the other hand, we plan to further extend management protocols to account for QoS attributes, including cost, so as to enable determining the best plan to achieve a management goal.
Notes
- 1.
The notions of well-formedness, determinism and race-freedom of management protocols, as well as the techniques for automatically completing them, can be defined as the natural extensions of those presented in [7].
- 2.
We assume that the names of states, requirements, capabilities, and operations of a node are all disjoint. We also assume that, given two different nodes in a topology, the names of their states, requirements, capabilities, and operations are disjoint.
- 3.
In this way, the fault handling transition is guaranteed to handle all the faults on the node, while at same time minimising the amount of requirements that stop being assumed (even though the corresponding capabilities continue to be provided).
- 4.
A sequential trace of \(P_A\) is one of the sequencing of \({\bullet }o\) and \(o{\bullet }\) (with o in \(P_A\)) obtained by topologically sorting the DAG modelling the partial ordering defined by \(P_A\).
- 5.
Due to space limitations, we are not including the natural adaptation of all such notions and techniques in this paper.
References
de Alfaro, L., Henzinger, T.A.: Interface automata. In: Proceedings of the 8th European Software Engineering Conference Held Jointly with 9th ACM SIGSOFT International Symposium on Foundations of Software Engineering, ESEC/FSE-9, pp. 109–120. ACM (2001)
Alhosban, A., Hashmi, K., Malik, Z., Medjahed, B., Benbernou, S.: Bottom-up fault management in service-based systems. ACM Trans. Internet Technol. 15(2), 7:1–7:40 (2015)
Bergmayr, A., et al.: A systematic review of cloud modeling languages. ACM Comput. Surv. 51(1), 22:1–22:38 (2018)
Betin Can, A., Bultan, T., Lindvall, M., Lux, B., Topp, S.: Eliminating synchronization faults in air traffic control software via design for verification with concurrency controllers. Autom. Softw. Eng. 14(2), 129–178 (2007)
Binz, T., Breitenbücher, U., Kopp, O., Leymann, F.: TOSCA: portable automated deployment and management of cloud applications. In: Bouguettaya, A., Sheng, Q., Daniel, F. (eds.) Advanced Web Services, pp. 527–549. Springer, New York (2014). https://doi.org/10.1007/978-1-4614-7535-4_22
Brogi, A., Canciani, A., Soldani, J.: Fault-aware application management protocols. In: Aiello, M., Johnsen, E.B., Dustdar, S., Georgievski, I. (eds.) ESOCC 2016. LNCS, vol. 9846, pp. 219–234. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-44482-6_14
Brogi, A., Canciani, A., Soldani, J.: Fault-aware management protocols for multi-component applications. J. Syst. Softw. 139, 189–210 (2018)
Candea, G., Brown, A.B., Fox, A., Patterson, D.: Recovery-oriented computing: building multitier dependability. Computer 37(11), 60–67 (2004)
Cook, R.I.: How complex systems fail. Cognitive Technologies Laboratory, University of Chicago. Chicago IL (1998)
Degano, P., Nicola, R.D., Montanari, U.: A partial ordering semantics for CCS. Theoret. Comput. Sci. 75(3), 223–262 (1990)
Di Cosmo, R., Mauro, J., Zacchiroli, S., Zavattaro, G.: Aeolus. Inf. Comput. 239(C), 100–121 (2014)
Durán, F., Salaün, G.: Robust and reliable reconfiguration of cloud applications. J. Syst. Softw. 122(C), 524–537 (2016)
Etchevers, X., Salaün, G., Boyer, F., Coupaye, T., DePalma, N.: Reliable self-deployment of distributed cloud applications. Softw. Pract. Experience 47(1), 3–20 (2017)
Fischer, J., Majumdar, R., Esmaeilsabzali, S.: Engage: a deployment management system. In: Proceedings of the 33rd ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2012, pp. 263–274. ACM (2012)
Grunske, L., Kaiser, B., Papadopoulos, Y.: Model-driven safety evaluation with state-event-based component failure annotations. In: Heineman, G.T., Crnkovic, I., Schmidt, H.W., Stafford, J.A., Szyperski, C., Wallnau, K. (eds.) CBSE 2005. LNCS, vol. 3489, pp. 33–48. Springer, Heidelberg (2005). https://doi.org/10.1007/11424529_3
Johnsen, E., Owe, O., Munthe-Kaas, E., Vain, J.: Incremental fault-tolerant design in an object-oriented setting. In: Proceedings of the Second Asia-Pacific Conference on Quality Software, APAQS, p. 223. IEEE Computer Society (2001)
Kaiser, B., Liggesmeyer, P., Mäckel, O.: A new component concept for fault trees. In: Proceedings of the 8th Australian Workshop on Safety Critical Systems and Software, SCS, vol. 33, pp. 37–46. Australian Computer Society, Inc. (2003)
Kopp, O., Binz, T., Breitenbücher, U., Leymann, F.: Winery – a modeling tool for TOSCA-based cloud applications. In: Basu, S., Pautasso, C., Zhang, L., Fu, X. (eds.) ICSOC 2013. LNCS, vol. 8274, pp. 700–704. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-45005-1_64
OMG: Business process model and notation (bpmn), version 2.0. https://www.omg.org/spec/BPMN/2.0/ (2011)
Pahl, C., Brogi, A., Soldani, J., Jamshidi, P.: Cloud container technologies: a state-of-the-art review. IEEE Trans. Cloud Comput. (2017, in press) https://doi.org/10.1109/TCC.2017.2702586
Pahl, C., Jamshidi, P., Zimmermann, O.: Architectural principles for cloud software. ACM Trans. Internet Technol. 18(2), 17:1–17:23 (2018)
Qiang, W., Yan, L., Bliudze, S., Xiaoguang, M.: Automatic fault localization for BIP. In: Li, X., Liu, Z., Yi, W. (eds.) SETTA 2015. LNCS, vol. 9409, pp. 277–283. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-25942-0_18
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 IFIP International Federation for Information Processing
About this paper

Cite this paper
Brogi, A., Canciani, A., Soldani, J. (2018). True Concurrent Management of Multi-component Applications. In: Kritikos, K., Plebani, P., de Paoli, F. (eds) Service-Oriented and Cloud Computing. ESOCC 2018. Lecture Notes in Computer Science(), vol 11116. Springer, Cham. https://doi.org/10.1007/978-3-319-99819-0_2
Download citation
DOI: https://doi.org/10.1007/978-3-319-99819-0_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-99818-3
Online ISBN: 978-3-319-99819-0
eBook Packages: Computer ScienceComputer Science (R0)