
Abstract
As machine learning continues to gain momentum in the neuroscience community, we witness the emergence of novel applications such as diagnostics, characterization, and treatment outcome prediction for psychiatric and neurological disorders, for instance, epilepsy and depression. Systematic research into these mental disorders increasingly involves drawing clinical conclusions on the basis of data-driven approaches; to this end, structural and functional neuroimaging serve as key source modalities. Identification of informative neuroimaging markers requires establishing a comprehensive preparation pipeline for data which may be severely corrupted by artifactual signal fluctuations. We propose a new unified data analysis pipeline for neuroimaging-based diagnostic classification problems using various different feature extraction techniques, Machine Learning algorithms and processing toolboxes for brain imaging. We illustrate the approach by discovering potential candidates for new biomarkers for diagnostics of epilepsy and depression presence in simple and complex cases based on clinical and MRI data for patients and healthy volunteers. We also demonstrate that the proposed pipeline in many classification tasks provides better performance than conventional ones.
This study was performed in the scope of Skoltech SBI Gelfand/Bernstein and Skoltech NGP Solomon/Burnaev projects.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Nowadays, Pattern Recognition (PR), Machine Learning (ML), and Intelligent data analysis techniques are used in medical research for diagnostic biomarkers discovery and treatment outcomes prediction with the use of neuroimaging data collected for the targeted groups of patients or healthy volunteers. To unify these processes, we offer a common data preprocessing and analysis pipeline for structural and functional magnetic resonance imaging (MRI) data which dramatically reduces research time and allows a researcher to try many preprocessing/data cleaning/feature extraction/classification options and compare results. In future, it is planned to add a visualization step (of informative features) together with classification results, which is highly desirable by medical community.
One challenge for the successful applications of automated diagnostics based on pattern recognition approaches in clinical settings is to ensure the highest possible quality of source signal employed for decision making. Cleaning the artifactual (irrelevant to the process in question) noise incidental to scanning deems necessary, as such fluctuations drastically hurt recognition performance, blocking the way to the identification of neuroimaging markers for mental disorders [4]. To this end, denoising schemes must be proposed, which involve the extensive examination of spatiotemporal constituents of the source signal and identification of the relevant components against the artifactual noise [3, 28]. In the present work, we investigate a pattern classification pipeline for mental disorders featuring a denoising step, and observe consistent performance improvements w.r.t. the baseline approach.
A different but important challenge is to design highly sensitive and robust predictive models. Research indicates that the pattern of brain activity changes associated with disorders such as depression might have limited discriminative power, leading to performance drops for common machine learning algorithms. Current accuracy of around 75%, thus, does not allow direct clinical application of these models [18].
Data used in the pilot study consists of structural and functional MR-images from 100 subjects: 25 healthy volunteers (H), 25 patients with major depressive disorder in an acute depressive episode (D), as well as 25 epilepsy patients (E) and 25 epilepsy patients with major depressive disorder (ED).
In summary, our contributions in this work are the following:
-
We provide a short review of current fMRI applications and data cleaning methods prior to feature extraction;
-
We propose a principled noise-aware pattern recognition pipeline for neuroimaging tailored to pattern classification;
-
Using a real MRI/fMRI dataset, we demonstrate the effectiveness of our methodology, searching for epilepsy-specific patterns. We aim to discriminate between healthy controls, patients with epilepsy, and patients with both epilepsy and depression.
The potential importance of the work arises from the fact that the majority of commercial and clinical scanners are 1.5T compared to high quality 3T and 7T research scanners. Here we prove that both structural and (low quality and short duration) resting-state data could be enough for epilepsy/depression diagnostics.
2 MR Data Properties, Preprocessing and Feature Extraction
Magnetic resonance imaging (MR imaging, MRI) and its part — functional magnetic resonance imaging (fMRI) — use strong magnetic fields to create images of biological tissues and physiological changes in them.
Upon acquisition, MRI data should be cleaned to eliminate the noise associated with the scanning procedure (low-level hardware artefacts such as magnetic field inhomogeneity, radiofrequency noise, surface coil artefacts and others) and signal processing (chemical shift, partial volume, etc.); besides there are artefacts associated with the scanned patient (physiological noise such as blood flow, movements, etc.). The artefacts should be considered in accordance with the noise origin and filtered out [9].
In addition to MRI data cleaning problem, there is another common challenge of the brain imaging analysis related to the large dimensionality of the measured data, which mostly depends on resolution parameters of the scanner inductive detection coil. For instance, standard voxel sizes are within 0.5–2 mm\(^3\) in case of structural imaging (resulting in \(10^7\) voxels for the whole brain volume). Thus, an MRI image, composed of huge number of small sized voxels, has higher spatial resolution and, hence, high dimensionality. To avoid the curse of the dimensionality phenomenon, ML methods are usually applied to lower dimensional features extracted from original scans by feature selection procedures. These procedures are also included into the preprocessing stage.
2.1 Structural MRI Preprocessing and Feature Extraction
Preprocessing stage has two main goals: MRI data cleaning and avoiding the curse of the dimensionality phenomenon caused by high dimensionality of initial MRI data. The latter goal can be achieved by constructing lower dimensional and biomedically interpretable brain characteristics from the initial data.
The goal of this sub-stage is to extract informative features (biomedically significant brain characteristics, clinically meaningful features) with lower dimensionality. The approach is typically realized in several steps:
-
selection of an appropriate brain atlas [17] which splits the brain into the anatomical areas (e.g. Hippocampi, cortical areas and etc.),
-
3D MRI images segmentation into disjoint sets (sub-images), consisting of voxels, corresponding to different brain regions (Regions of Interest, ROIs),
-
various characteristics calculation for each ROI.
The examples of such characteristics could be structural morphometric parameters (volumes, thicknesses, curvatures) of the selected anatomical areas from the MRI-image, which together form a volumetric vector. For example, MRI processing toolbox [12] parcels MRI images into regions corresponding to the chosen Desikan-Killiany atlas; calculates 7 volumetric characteristics for each cortical region (NVoxels, Volume_mm3, normMean, normStdDev, normMin, normMax, normRange) and 9 geometric characteristics of subcortical regions (NumVert, SurfArea, GrayVol, ThickAvg, ThickStd, MeanCurv, GausCurv, FoldInd, CurvInd).
For constructed objects different characteristics reflecting meaningful properties of these objects, can be computed for further use in Machine learning studies like segments of MRI-image consisting of 3D MRI-voxels from chosen brain areas (to be used as inputs for deep learning procedures [23]). Most often domain-specific lower dimensional features (morphometric or functional connectivity features) could be extracted from original data in specialized MRI processing toolboxes [2].
2.2 Functional MRI Preprocessing and Feature Extraction
fMRI-Related Noise.
Not depending on equipment, fMRI signal is very noisy. As T2*-weighted image (BOLD-contrast) is a mixture of signals from many sources, the desired signal from the neuronal activity only represents a relatively small percentage of the variance of the signal [3]. Non-neuronal contributions to the BOLD fMRI time series include receiver coil thermal noise, instrumental drifts, spike-like artifactual signals induced by the hardware instabilities, rapid and high-amplitude spikes due to the head motion. The physiological noise of non-neuronal origin (which is essentially BOLD-signal, but of no interest) comprises of cardiac and respiratory noise, changes in arterial carbon dioxide concentration associated with varying respiration rate, vasomotor effects, changes in blood pressure and cerebral autoregulation mechanisms [20].
Noise Identification and Suppression.
Three significantly different general approaches for noise identification and removal in fMRI data can be highlighted [5, 28]: the first is based on using additional sensors measuring physiological activities exploitation (model-based approach, [14]), the second is noise elimination specific for each type of noise (e.g. motion correction or thermal noise cleaning), finally the third one is data-driven using only fMRI data itself and prior information about fMRI signal and noise. The first approach is limited as it covers only physiological nature of the noise and can’t handle e.g. scanner artifacts. Moreover, large amounts of data have already been collected (and are being collected) without additional “noise” information, so the aforementioned method cannot be useful here. Data collection with additional equipment introduces additional challenges from increased experimental time to equipment cost, MR-compatibility, and instability.
Independent Component Analysis (ICA) based technique could be viewed as a second step as it might be applied to components extracted by PCA [26]. The resulting independent components are assumed to be either noise-related or signal-related, each representing one of the sources in a source separation task solved by ICA. ICA transforms source fMRI signal into a set of components with distinct spatial and temporal structures, which further could be classified as noise or signal. Three possible approaches to this classification can be highlighted.
The first one is an expert-based technique: an individual with expertise in fMRI processing must examine every component (time courses, spatial distribution, and spectrum) and manually label it as either signal or noise [15, 19]. [15] present a detailed guideline for evaluating and categorizing independent components and provide examples of each component class. Expert-based categorization may be tedious and error-prone for data with low SNR ratios, e.g. for ubiquitous medical 1.5T scanners.
Another option is to utilize a pre-trained classifier such as the one provided by the FIX package of FSL that achieves 99% classification accuracy based on the annotation created by human experts [28]. In this work, ICA components are used to extract features for the machine learning methods (supervised learning classifiers) that aim to classify noise components from signal automatically based on labeled training data. 46 temporal and 131 spatial features are extracted and a feature selection procedure is performed during classifier training.
Finally, the third approach is to combine the first two approaches, i.e. to calibrate the existing model pre-trained on vast amounts of data with different characteristics (such as the one provided by the FIX package) for the particular problem. This requires creating a new task-oriented labeled dataset using the expert knowledge and using transfer learning techniques known from machine learning to ’fine-tune’ the classification model on the newly labeled data. This approach seems to be the most promising when data quality is low and number of patients is relatively high.
Described approaches to signal-noise separation for fMRI data might prove useful for classification tasks in the medical domains described above, specifically epilepsy, schizophrenia, and depression diagnostics. The crucial point here is that physiological noise having no direct relation to the neuronal activity (i.e. signal), might still carry valuable discriminating information for the classification task. For instance, cerebral blood flow fluctuations might reveal unobservable brain states, which correlate with the target variable (disease/no disease). Broadly speaking, two ways to approaching the classification problem exist. The first assumes building classifier based on the hand-crafted features extracted from the independent components (such as, for instance, described in [28]), that could prove effective for discriminating between patients vs. healthy controls. An alternative approach may be based on the reconstruction of the 4D fMRI signal itself after noise elimination and its utilization as a source data for training (i.e. data might be denoised, or its signal and noise parts investigated separately).
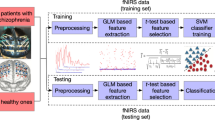
3 The Proposed Pipeline
The literature review has allowed us to identify established and prospective building blocks and organize them into a unified and highly automated fMRI processing pipeline, see [13] for detailed discussion. Our pipeline accepts raw functional and structural scans of a subject and outputs the predicted task-specific scores, whose meaning vary according to the application. For instance, for a depression vs. healthy control classification task, our pipeline should score the patient according to a probability of depression diagnosis for him. The entire chain of steps can be implemented in a modular way via existing or prospective software by respecting interfaces between the modules. We note that as some of the modules may carry computationally intensive processing, the runtime of the pipeline may vary from minutes to several hours. We briefly describe our proposed pipeline below.
The input to our pipeline comprises of functional and structural MRI scans. The raw scans are passed through a standard preprocessing step, an established low-level MRI handling stage (involving slice-time correction, motion correction, filtering in space and time, anatomical alignment across individuals) [7], yielding preprocessed data on the same scale and format. A second stage accepts preprocessed scans and runs a manual denoising procedure analogous to the one discussed in [15], producing a scan with irrelevant components excluded and an increased SNR. The third stage of our pipeline performs correlation-based and graph-based feature extraction for fMRI and structural morphometric parameters (volumes, thicknesses, curvatures) extraction for structural MRI data, which together form a volumetric vector. Lastly, our pipeline performs pattern recognition by making use of available implementations of conventional machine learning approaches such as SVMs [29], neural networks [25], and decision trees combined with imbalanced classification approaches [24], to name a few. Additionally, for each selected combination of analysis steps it is possible to select and visualize most informative structural/functional features (i.e., potentical candidates for biomarkers) and evaluate True Positive Rate (TPR) with any fixed False Positive Rate (FPR), which is extremely useful in medical practice.
4 Illustrative Example: Pattern Recognition for Epilepsy Detection
4.1 fMRI-based Pattern Recognition
The purpose of this example study is to demonstrate the possible advantages of using novel sophisticated artifact removal procedures prior to feature extraction in clinical diagnostics. The data at our disposal consisted of functional MRI scans of four groups of subjects: 25 patients with epilepsy, 25 patients with depression, 25 patients with both epilepsy and depression, and 25 healthy controls. We aimed at finding patterns connected to epilepsy, thus discriminating patients with epilepsy against the rest of the sample: the diagnostic question is whether a particular subject has epilepsy (otherwise he might be healthy or have depression). Resting-state functional MRI was collected at 1.5T EXCEL ART VantageAtlas-X Toshiba scanner at Z.P.Solovyev Research and Clinical Center for NeuropsychiatryFootnote 1.
Raw data were preprocessed according to two different protocols:
-
1.
Spectrum: standard preprocessing pipeline implemented in SPM12 including slice-timing correction, bad-slices interpolation, motion-correction (bad volumes interpolation), coregistration with T1 images and spatial normalization.
-
2.
Manual: a combination of standard pipeline with manual ICA classification into signal and noise components by fMRI experts.
For the parcellation of the brain, we used an Automatic Anatomic Labeling (AAL) atlas consisting of 117 regions. For each region corresponding time series were assigned, and then a correlation matrix was computed from them. Significant correlation values (\(p = 0.05\), Bonferroni corrected) were set to ones, all other values were set to zeros, yielding a binary adjacency matrix of dimensionality \(117 \times 117\). An example of raw and binarized matrix is in Fig. 1.

Visualization of fMRI patterns used for the classification task. A depicts the correlation matrix, from left to right: raw, binarized (threshold = 0.15), binarized (threshold = 0.4). B depicts the functionally connected brain areas according to the elements of the correlation matrix in A.
The python library NetworkX was used to calculate features corresponding to each region of interest, explaining the level of functional activity of the region in terms of graph nodes.We calculated 5 metrics corresponding to each region of the brain: clustering coefficient, degree centrality, closeness centrality, betweenness centrality, average neighbor degree, and 2 metrics describing the graph in general: local efficiency and global efficiency [22]. Then the standard machine learning classifiers were applied: Support Vector Machine (SVM), Random Forests (RF), and Logistic Regression (LR).
Each model was validated using leave-one-out approach. Four comparisons were performed:
-
EvsH. 25 epilepsy only patients vs. 25 healthy controls,
-
EDvsE. 25 epilepsy only patients vs. 25 epilepsy + depression patients,
-
EvsNE. 50 subjects with epilepsy vs. 50 subjects without epilepsy (including healthy controls and subjects with depression).
-
EDvsD. 25 depression only patients vs. 25 epilepsy + depression patients.
The results for each classification task are in Tables 1, 2, 3 and 4. Summary of classification results in terms of prediction accuracy for the two competing preprocessing pipelines is provided in Table 5.
Firstly, it can be seen that Spectrum preprocessing does not perform well when working on simple features (functional connectivity). Next, Manual shows relatively high performance in terms of accuracy and true positive rate, which means that additional sophisticated data cleaning could be beneficial prior to feature extraction for fMRI classification tasks. In all except EvsNE the classifier performance is rather high and stable after cross-validation meaning that epilepsy-specific fMRI pattern could be found, thus in it might be hard to distinguish between complex epilepsy + depression patients possibly due to similar brain disruptions. An additional work is needed here to construct new features sensitive to subtle differences between patients.
4.2 Structural MRI-based Pattern Recognition
Structural MRI data were cleaned, preprocessing and their features were extracted using MRI processing toolboxes [1, 2] as described below (see also Fig. 2).
Structural morphometric features were calculated from T1w images using [12]; for more than 100 brain regions corresponding features explaining brain structure (volumes, surface areas, thicknesses, etc.) were computed producing a vector with 894 features for each subject.

An example of brain parcellaton used for feature extraction: structural brain MRI split into anatomical regions performed in Freesurfer 6.0 according to the Desikan-Killiany atlas. A: coronal view, B: axial view, C: saggital view.
Next, the ML exploratory pipeline was implemented on Ipython using scikit-learn libraryFootnote 2 and organized as follows:
-
We considered two geometrical methods for dimensionality reduction: (1) Locally Linear Embedding, (2) Principal Component Analysis (see description of a weighted version in [6]).
-
We considered two methods of feature selection: (1) feature selection based on Pearson’s chi-squared test and ANOVA scoring, implemented via SelectKBest function in scikit-learn; (2) selection of relevant features based on a particular classification model used with Logistic Regression (LR), K-Nearest Neighbors (KNN) and Random Forest Classifier (RFC), implemented via the SelectFromModel function in scikit-learn.
-
We performed grid search for a number of selected features and for a number of components in dimension reduction procedure in the sets \(\{10, 20, 50, 100\}\) and \(\{5, 10, 15, 20\}\), correspondingly.
Data was whitened before training. Feature reduction was performed without double-dipping [21], therefore training and testing datasets are separated before feature selection/dimensionality reduction. Hyper-parameters grid search was based on cross-validation with stratification, repeated 10 times for each person being in test.
As mentioned above, the dataset explored with the proposed pipeline contains four groups of subjects. Patients from epilepsy and epilepsy with depression groups represent cohorts with several types of epilepsy localization: temporal, frontal, parietal, mixed and unknown cases. That allows exploration of general patterns of epilepsy, independently to the localization, which are known to be tacked particular subcortical regions as hippocampus. Then in other research, the ML methods are applied to classify epilepsy with a known epilepsy localization. There are two types of epilepsy being extensively explored: temporal lobe epilepsy (TLE) or even precisely TLE with mesial temporal sclerosis (TLE-MTS), and focal cortical dysplasia patients with TLE (TLE-FCD) [8, 10, 16]. In some cases, TLE patients from these selected groups are further separated in groups by the loci localization as right and left [11].
The results for each classification task are in Tables 6, 7, 8 and 9. Summary of classification results in terms of prediction accuracy is provided in Table 10. Thus, the obtained results on the in-homogenized cohort are the firstly reported and we consider the results with the classification accuracy more than 0.7 statistically significant with .05 level of confidence on the explored cohort of 50 patients. We provide the results for EvsH classification task in Table 6. Note that we obtain statistically significant results on structural MRI features. This could be explained by the fact that epilepsy leads to significant changes in brain structure, which can yield more accurate classification. Table 9 presents results for EDvsE classification task. We conclude that model performance is not statistically significant, highlighting the difficulty of isolation of depression against the complex illness picture based on MRI data alone. The results for EvsNE are in Table 8; here the model performance is comparable to ones from preselected cohort of patients [8, 10, 11, 16] as for EvsH case, cf. table, where TPR reaches 80% with FPR fixed at 30%.
The most by score important features from models EvsH and EvsNE are: Ventral Diencephalon Right, Hippocampus Left, Thalamus Left, Putamen Left, Angular gyrus Right, Frontal gyrus Right (Superior), Paracentral lobule Left, Postcentral gyrus Right, Precentral gyrus Left, Supra Marginal gyrus Left, Temporal Pole Left. These findings are in line with current knowledge of epileptogenic zones and brain areas mostly affected from epileptic seizures [27] as well as provide some new information on possible targets in epilepsy diagnostics and treatment.
5 Conclusions
In the current work, we reviewed some approaches to neuroimaging data cleaning aimed at the elimination of artifacts harmful for further pattern recognition. Based on well established and novel approaches, we proposed a principled noise-aware pattern recognition pipeline for neuroimaging tailored to pattern classification and showed the potential effectiveness of our proposed methodology in a pilot classification study. Our general data preprocessing and analysis pipeline for structural and functional MRI data could dramatically reduce research time, thus allowing a researcher to investigate a larger variety of preprocessing, data cleaning, feature extraction, and classification options as well as compare results based on desired metrics. From top performing combinations of analysis steps we obtained a number of stable structural and functional features (i.e., potential candidates for biomarkers), some of which are known and well established, whereas some of which are new and could possibly provide new medical knowledge on epilepsy mechanisms and its robust detection. We also evaluated True Positive Rates (TPR) with different fixed False Positive Rates (FPR), which is much more useful for clinicians than classification accuracy alone. According to the proposed pipeline, we found the ICA-based cleaning step to be crucial for further pattern recognition task: denoised data provides clearer and more informative features for machine learning-based diagnostics, and yields significant improvements in finding epilepsy-specific pattern in a group of patients with only epilepsy versus epilepsy + depression patients and healthy controls. We strongly believe that application of pattern recognition in functional neuroimaging is promising for clinical diagnostics of psychiatric disorders such as depression and neurological diseases such as epilepsy, though the classification performance achieved in our study may be not enough for immediate medical applications. We don’t consider end-to-end (deep learning-based) pipeline, as we believe deep learning-based approaches would face strict limitations with raw data without any preprocessing due to (1) high dimensionality, (2) very low SNR ratios, and (3) very small sample size in comparison to usual deep learning problems.
The analyzed dataset has several obvious drawbacks: it is small and well balanced, which is not the usual case in clinical practice. As the number of public sources of epilepsy/depression clinical data is limited and the access to these datasets is difficult to obtain, it is hard to compare our results with other research groups, though several studies with similar objectives are discussed above.
We nevertheless obtained statistically significant results for EvsH, EvsNE, and EDvsD models. The epilepsy classification on mixed cohort EvsNE reached FPR 30% (model sensitivity 70%), and TNR 80% (specificity 80%) is comparable to the research conducted on pre-selected groups of patients [8, 10, 11, 16], allowing the exploration of generalized disease biomarkers which were not analyzed with ML methods before.
Despite the limitations, the proposed approach is universal and has the potential to be implemented into clinical practice, as it is not based on high-quality data and sophisticated ML algorithms, but could be useful in real applications or serve as a starting point tutorial for building new MR processing pipelines.
Notes
- 1.
Skoltech biomedical partner. Website (in Russian): http://npcpn.ru/.
- 2.
References
Behroozi, M., Daliri, M.: Software tools for the analysis of functional magnetic resonance imaging. Basic Clin. Neurosci. 3(5), 71–83 (2012)
Bernstein, A., Akzhigitov, R., Kondrateva, E., Sushchinskaya, S., Samotaeva, I., Gaskin, V.: MRI brain imagery processing software in data analysis. In: Perner, P. (ed.) Advances in Mass Data Analysis of Images and Signals in Medicine, Biotechnology, Chemistry and Food Industry. Proceedings of 13th International Conference on Mass Data Analysis of Images and Signals (MDA 2018). Springer (2018)
Bianciardi, M.: Sources of functional magnetic resonance imaging signal fluctuations in the human brain at rest: a 7 T study. Mag. Reson. Imaging 27(8), 1019–1029 (2009)
Birn, R.M., Murphy, K., Handwerker, D.A., Bandettini, P.A.: fMRI in the presence of task-correlated breathing variations. Neuroimage 47(3), 1092–1104 (2009)
Caballero-Gaudes, C., Reynolds, R.C.: Methods for cleaning the bold fMRI signal. Neuroimage 154, 128–149 (2017)
Chernova, S., Burnaev, E.: On an iterative algorithm for calculating weighted principal components. J. Commun. Technol. Electron. 60(6), 619–624 (2015)
Cohen, J.D., et al.: Computational approaches to fMRI analysis. Nature Neurosci. 20(3), 304 (2017)
Del Gaizo, J.: Using machine learning to classify temporal lobe epilepsy based on diffusion MRI. Brain Behav. 7(10), e00801 (2017)
Erasmus, L., Hurter, D., Naude, M., Kritzinger, H., Acho, S.: A short overview of MRI artefacts. SA J. Radiol. 8, 13–17 (2004)
Fang, P., An, J., Zeng, L.L., Shen, H., Qiu, S., Hu, D.: Mapping the convergent temporal epileptic network in left and right temporal lobe epilepsy. Neurosci. Lett. 639, 179–184 (2017)
Focke, N.K., Yogarajah, M., Symms, M.R., Gruber, O., Paulus, W., Duncan, J.S.: Automated MR image classification in temporal lobe epilepsy. Neuroimage 59(1), 356–362 (2012)
FreeSurfer: Freesurfer toolbox - an open source software suite for processing and analyzing (human) brain MRI images (2018). https://surfer.nmr.mgh.harvard.edu/
Friston, K.J., Ashburner, J.T., Kiebel, S.J., Nichols, T.E., Penny, W.D.: Statistical Parametric Mapping: The Analysis of Functional Brain Images, vol. 8 (2007)
Glover, G.H., Li, T.Q., Ress, D.: Image-based method for retrospective correction of physiological motion effects in fMRI: retroicor. Mag. Reson. Med. 44(1), 162–167 (2000)
Griffanti, L., et al.: Hand classification of fMRI ica noise components. Neuroimage 154, 188–205 (2017)
Hong, S.J., Kim, H., Schrader, D., Bernasconi, N., Bernhardt, B.C., Bernasconi, A.: Automated detection of cortical dysplasia type II in MRI-negative epilepsy. Neurology 83(1), 48–55 (2014)
Jean, T., Tournoux, P.: Co-Planar Stereotaxic Atlas of the Human Brain: 3-D Proportional System: An Approach to Cerebral Imaging (1988)
Kambeitz, J., et al.: Detecting neuroimaging biomarkers for schizophrenia: a meta-analysis of multivariate pattern recognition studies. Neuropsychopharmacology 40(7), 1742 (2015)
Kelly Jr., R.E., et al.: Visual inspection of independent components: defining a procedure for artifact removal from fmri data. J. Neurosci. Methods 189(2), 233–245 (2010)
Murphy, K., Birn, R.M., Bandettini, P.A.: Resting-state fMRI confounds and cleanup. Neuroimage 80, 349–359 (2013)
Mwangi, B., Tian, T.S., Soares, J.C.: A review of feature reduction techniques in neuroimaging. Neuroinformatics 12(2), 229–244 (2014)
Networkx: Networkx - software for complex networks (2018). https://networkx.github.io/
Notchenko, A., Kapushev, Y., Burnaev, E.: Large-scale shape retrieval with sparse 3D convolutional neural networks. In: van der Aalst, W.M., et al. (eds.) Analysis of Images, Social Networks and Texts, pp. 245–254. Springer International Publishing, Cham (2018)
Papanov, A., Erofeev, P., Burnaev, E.: Influence of resampling on accuracy of imbalanced classification. In: Verikas, A., Radeva, P., Nikolaev, D. (eds.) Proceedings of SPIE 9875, Eighth International Conference on Machine Vision, Barcelona, Spain, 8 December 2015, vol. 9875. SPIE (2015)
Prikhod’ko, P.V., Burnaev, E.V.: On a method for constructing ensembles of regression models. Autom. Remote Control 74(10), 1630–1644 (2013). https://doi.org/10.1134/S0005117913100044
Rasmussen, P.M., Abrahamsen, T.J., Madsen, K.H., Hansen, L.K.: Nonlinear denoising and analysis of neuroimages with Kernel principal component analysis and pre-image estimation. NeuroImage 60(3), 1807–1818 (2012)
Richardson, E., et al.: Structural and functional neuroimaging correlates of depression in temporal lobe epilepsy. Epilepsy Behav. 10(2), 242–249 (2007)
Salimi-Khorshidi, G., Douaud, G., Beckmann, C.F., Glasser, M.F., Griffanti, L., Smith, S.M.: Automatic denoising of functional MRI data: combining independent component analysis and hierarchical fusion of classifiers. Neuroimage 90, 449–468 (2014)
Smolyakov, D., Erofeev, P., Burnaev, E.: Model selection for anomaly detection. In: Verikas, A., Radeva, P., Nikolaev, D. (eds.) Proceedings of SPIE 9875, Eighth International Conference on Machine Vision, Barcelona, Spain, 8 December 2015. SPIE, vol. 9875 (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Sharaev, M. et al. (2018). Pattern Recognition Pipeline for Neuroimaging Data. In: Pancioni, L., Schwenker, F., Trentin, E. (eds) Artificial Neural Networks in Pattern Recognition. ANNPR 2018. Lecture Notes in Computer Science(), vol 11081. Springer, Cham. https://doi.org/10.1007/978-3-319-99978-4_24
Download citation
DOI: https://doi.org/10.1007/978-3-319-99978-4_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-99977-7
Online ISBN: 978-3-319-99978-4
eBook Packages: Computer ScienceComputer Science (R0)
