
Abstract
The two main challenges typically associated with mining data streams are concept drift and data contamination. To address these challenges, we seek learning techniques and models that are robust to noise and can adapt to changes in timely fashion. In this paper, we approach the stream-mining problem using a statistical estimation framework, and propose a discriminative model for fast mining of noisy data streams. We build an ensemble of classifiers to achieve adaptation by weighting classifiers in a way that maximizes the likelihood of the data. We further employ robust statistical techniques to alleviate the problem of noise sensitivity. Experimental results on both synthetic and real-life data sets demonstrate the effectiveness of this new discriminative model.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others
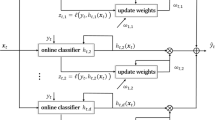

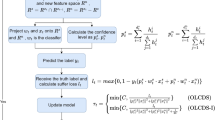
References
Aggarwal, C., Yu, P.: Outlier detection for high dimensional data. In: Int’l Conf. Management of Data, SIGMOD (2001)
Aha, D., Kibler, D., Albert, M.: Instance-based learning algorithms. Machine Learning 6(1), 37–66 (1991)
Bilmes, J.: A gentle tutorial on the em algorithm and its application to parameter estimation for gaussian mixture and hidden markov models. In Technical Report ICSI-TR-97-021 (1998)
Breiman, L.: Bagging predictors. Machine Learning 24(2), 123–140 (1996)
Breunig, M., Kriegel, H., Ng, R., Sander, J.: LOF: identifying density-based local outliers. In: Int’l Conf. Management of Data, SIGMOD (2000)
Brodley, C., Friedl, M.: Identifying and eliminating mislabeled training instances. Artificial Intelligence, 799–805 (1996)
Domeniconi, C., Gunopulos, D.: Incremental support vector machine construction. In: Int’l Conf. Data Mining, ICDM (2001)
Hastie, T., Tibshirani, R., Friedman, J.: The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer, Heidelberg (2000)
Hulten, G., Spencer, L., Domingos, P.: Mining time-changing data streams. In: Int’l Conf. on Knowledge Discovery and Data Mining, SIGKDD (2001)
Kolter, J., Maloof, M.: Dynamic weighted majority: A new ensemble method for tracking concept drift. In: Int’l Conf. Data Mining, ICDM (2001)
Kubica, J., Moore, A.: Probabilistic noise identification and data cleaning. In: Int’l Conf. Data Mining, ICDM (2003)
Oza, N.C., Russell, S.: Online bagging and boosting. Artificial Intelligence and Statistics, 105–112 (2001)
Ramaswamy, S., Rastogi, R., Shim, K.: Efficient algorithms for mining outliers from large data sets. In: Int’l Conf. Management of Data, SIGMOD (2000)
Schlimmer, J., Granger, F.: Beyond incremental processing: Tracking concept drift. In: Proc. of Int’l Conf. on Artificial Intelligence, pp. 502–507 (1986)
Stolfo, S., Fan, W., Lee, W., Prodromidis, A., Chan, P.: Credit card fraud detection using meta-learning: Issues and initial results. In: AAAI 1997 Workshop on Fraud Detection and Risk Management (1997)
Street, W., Kim, Y.: A streaming ensemble algorithm (sea) for large-scale classification. In: Int’l Conf. on Knowledge Discovery and Data Mining, SIGKDD (2001)
Wang, H., Fan, W., Yu, P., Han, J.: Mining concept-drifting data streams using ensemble classifiers. In: Int’l Conf. on Knowledge Discovery and Data Mining, SIGKDD (2003)
Widmer, G., Kubat, M.: Learning in the presence of concept drift and hidden contexts. Machine Learning 23, 69–101 (1996)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2004 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Chu, F., Wang, Y., Zaniolo, C. (2004). Mining Noisy Data Streams via a Discriminative Model. In: Suzuki, E., Arikawa, S. (eds) Discovery Science. DS 2004. Lecture Notes in Computer Science(), vol 3245. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-30214-8_4
Download citation
DOI: https://doi.org/10.1007/978-3-540-30214-8_4
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-23357-2
Online ISBN: 978-3-540-30214-8
eBook Packages: Springer Book Archive