
Abstract
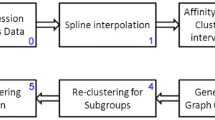
Clustering still represents the most commonly used technique to analyze gene expression data—be it classical clustering approaches that aim at finding biologically relevant gene groups or biclustering methods that focus on identifying subset of genes that behave similarly over a subset of conditions. Usually, the measurements of different experiments are mixed together in a single gene expression matrix, where the information about which experiments belong together, e.g., in the context of a time course, is lost. This paper investigates the question of how to exploit the information about related experiments and to effectively use it in the clustering process. To this end, the idea of order preserving clusters that has been presented in [2] is extended and integrated in an evolutionary algorithm framework that allows simultaneous clustering over multiple time course experiments while keeping the distinct time series data separate.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


References
Bar-Joseph, Z.: Analizing time series gene expression data. Bioinformatics 20(16), 2493–2503 (2004)
Ben-Dor, A., Chor, B., Karp, R., Yakhini, Z.: Discovering local structure in gene expression data: The order-preserving submatrix problem. In: Conference on Computational Biology (RECOMB 2002), pp. 49–57. ACM Press, New York (2002)
Bleuler, S., Prelić, A., Zitzler, E.: An EA framework for biclustering of gene expression data. In: Congress on Evolutionary Computation (CEC 2004), Piscataway, NJ, pp. 166–173. IEEE, Los Alamitos (2004)
Bolstad, B.M., Irizarry, R.A., Astrand, M., Speed, T.P.: A comparison of normalization methods for high density oligonucleotide array based on variance and bias. Bioinformatics 19(2), 185–193 (2003)
Cheng, Y., Church, G.M.: Biclustering of gene expression data. In: ISMB 2000, pp. 93–103 (2000), http://cheng.ecescs.uc.edu/biclustering
Eisen, M.B., Spellman, P.T., Brown, P.O., Botstein, D.: Cluster analysis and display of genome-wide expression patterns. PNAS 95, 14863–14868 (1998)
Liu, J., Yang, J., Wang, W.: Biclustering in gene expression data by tendency. In: Computational Systems Bioinformatics Conference (CSB 2004). IEEE, Los Alamitos (2004)
Reinelt, G.: The Linear Ordering Problem. Heldermann, Berlin (1985)
Scharnow, J., Tinnefeld, K., Wegener, I.: Fitness landscapes based on sorting and shortest path problems. In: Guervós, J.J.M., Adamidis, P.A., Beyer, H.-G., Fernández-Villacañas, J.-L., Schwefel, H.-P. (eds.) PPSN 2002. LNCS, vol. 2439, pp. 54–63. Springer, Heidelberg (2002)
Segal, E., Battle, A., Koller, D.: Decomposing gene expresision into cellular processes. In: Pacific Symposium on Biocomputing, pp. 89–100 (2003)
Tamayo, P., et al.: Interpreting patterns of gene expression with self-organizing maps: Methods and applicataion to hematopoietic differentiation. PNAS 96, 2907–2912 (1999)
Tanay, A., Sharan, R., Shamir, R.: Discovering statistically significant biclusters in gene expression data. Bioinformatics 18(suppl. 1), S136–S144 (2002)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2005 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Bleuler, S., Zitzler, E. (2005). Order Preserving Clustering over Multiple Time Course Experiments. In: Rothlauf, F., et al. Applications of Evolutionary Computing. EvoWorkshops 2005. Lecture Notes in Computer Science, vol 3449. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-32003-6_4
Download citation
DOI: https://doi.org/10.1007/978-3-540-32003-6_4
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-25396-9
Online ISBN: 978-3-540-32003-6
eBook Packages: Computer ScienceComputer Science (R0)