
Abstract
Feature selection plays an important role in text categorization. Many sophisticated feature selection methods such as Information Gain (IG), Mutual Information (MI) and χ2 statistic measure (CHI) have been proposed. However, when compared to these above methods, a very simple technique called Document Frequency thresholding (DF) has shown to be one of the best methods either on Chinese or English text data. A problem is that DF method is usually considered as an empirical approach and it does not consider Term Frequency (TF) factor. In this paper, we put forward an extended DF method called TFDF which combines the Term Frequency (TF) factor. Experimental results on Reuters-21578 and OHSUMED corpora show that TFDF performs much better than the original DF method.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

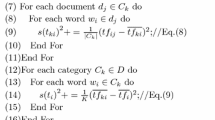

References
Liu-ling, D., He-yan, H., Zhao-xiong, C.: A comparative Study on Feature Selection in Chinese Text Categorization. Journal of Chinese Information Processing 18(1), 26–32 (2005)
Dumais, S.T., Platt, J., Heckerman, D., Sahami, M.: Inductive learning algorithms and representations for text categorization. In: Proceedings of CIKM 1998, pp. 148–155 (1998)
Sebastiani, F.: Machine learning in automated text categorization. ACM Computing Surveys 34(1), 1–47 (2002)
Itner, D.J., Lewis, D.D.: Text categorization of low quality images. In: Proceedings of SDAIR 1995, pp. 301–315 (1995)
Komorowski, J., Pawlak, Z., Polkowski, L., Skowron, A.: Rough sets: A tutorial. In: A New Trend in Decision-Making, pp. 3–98. Springer, Singapore (1999)
Li, Y.H., Jain, A.K.: Classification of text documents. Comput. J. 41(8), 537–546 (1998)
Maron, M.: Automatic indexing: an experimental inquiry. J. Assoc. Comput. Mach. 8(3), 404–417 (1961)
Pawlak, Z.: Rough Sets. International Journal of Computer and Information Science 11(5), 341–356 (1982)
Salton, G., Buckley, C.: Term-weighting approaches in automatic text retrieval. Inform. Process. Man 24(5), 513–523 (1988)
Salton, G., Wong, A., Yang, C.: A vector space model for automatic indexing. Commun. ACM 18(11), 613–620 (1975)
Songwei, S., Shicong, F., Xiaoming, L.: A Comparative Study on Several Typical Feature Selection Methods for Chinese Web Page Categorization. Journal of the Computer Engineering and Application 39(22), 146–148 (2003)
Yang, S.M., Wu, X.-B., Deng, Z.-H., Zhang, M., Yang, D.-Q.: Modification of Feature Selection Methods Using Relative Term Frequency. In: Proceedings of ICMLC 2002, pp. 1432–1436 (2002)
Yang, Y., Pedersen, J.O.: Comparative Study on Feature Selection in Text Categorization. In: Proceedings of ICML 1997, pp. 412–420 (1997)
Yang, Y., Liu, X.: A re-examination of text categorization methods. In: SIGIR 1999, pp. 42–49 (1999)
Yang, Y.: An evaluation of statistical approaches to text categorization. Journal of Information Retrieval 1(1/2), 67–88 (1999)
Zhang, H.: The optimality of naive Bayes. In: The 17th International FLAIRS conference, Miami Beach, May 17-19 (2004)
Reuters 21578, http://www.daviddlewis.com/resources/testcollections/reuters21578/
Author information
Authors and Affiliations
Editor information
Rights and permissions
Copyright information
© 2008 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Xu, Y., Wang, B., Li, J., Jing, H. (2008). An Extended Document Frequency Metric for Feature Selection in Text Categorization. In: Li, H., Liu, T., Ma, WY., Sakai, T., Wong, KF., Zhou, G. (eds) Information Retrieval Technology. AIRS 2008. Lecture Notes in Computer Science, vol 4993. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-68636-1_8
Download citation
DOI: https://doi.org/10.1007/978-3-540-68636-1_8
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-68633-0
Online ISBN: 978-3-540-68636-1
eBook Packages: Computer ScienceComputer Science (R0)