
Abstract
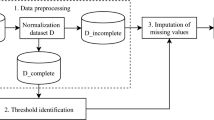
We propose an efficient nonparametric missing value imputation method based on clustering, called CMI (Clustering-based Missing value Imputation), for dealing with missing values in target attributes. In our approach, we impute the missing values of an instance A with plausible values that are generated from the data in the instances which do not contain missing values and are most similar to the instance A using a kernel-based method. Specifically, we first divide the dataset (including the instances with missing values) into clusters. Next, missing values of an instance A are patched up with the plausible values generated from A’s cluster. Extensive experiments show the effectiveness of the proposed method in missing value imputation task.
This work is partially supported by Australian Large ARC grants (DP0559536 and DP0667060), China NSF major research Program (60496327), China NSF grant for Distinguished Young Scholars (60625204), China NSF grants (60463003, 10661003), an Overseas Outstanding Talent Research Program of Chinese Academy of Sciences (06S3011S01), an Overseas-Returning High-level Talent Research Program of China Ministry of Personnel, China NSF grant for Distinguished Young Scholars (60625204), a Guangxi NSF grant, and an Innovation Project of Guangxi Graduate Education (2006106020812M35).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


References
Zhang, S.C., et al.: Information Enhancement for Data Mining. IEEE Intelligent Systems, 2004 19(2), 12–13 (2004)
Zhang, S.C., et al.: Missing is useful: Missing values in cost-sensitive decision trees. IEEE Transactions on Knowledge and Data Engineering 17(12), 1689–1693 (2005)
Qin, Y.S., et al.: Semi-parametric Optimization for Missing Data Imputation. Applied Intelligence 27(1), 79–88 (2007)
Zhang, C.Q., et al.: An Imputation Method for Missing Values. In: Zhou, Z.-H., Li, H., Yang, Q. (eds.) PAKDD 2007. LNCS (LNAI), vol. 4426, pp. 1080–1087. Springer, Heidelberg (2007)
Quinlan, J.R.: C4.5: Programs for Machine Learning. Morgan Kaufmann, San Francisco (1993)
Han, J., Kamber, M.: Data Mining: Concepts and Techniques, 2nd edn. Morgan Kaufmann, San Francisco (2006)
Chen, J., Shao, J.: Jackknife variance estimation for nearest-neighbor imputation. J. Amer. Statist. Assoc. 96, 260–269 (2001)
Lall, U., Sharma, A.: A nearest-neighbor bootstrap for resampling hydrologic time series. Water Resource. Res. 32, 679–693 (1996)
Chen, S.M., Chen, H.H.: Estimating null values in the distributed relational databases environments. Cybernetics and Systems: An International Journal 31, 851–871 (2000)
Chen, S.M., Huang, C.M.: Generating weighted fuzzy rules from relational database systems for estimating null values using genetic algorithms. IEEE Transactions on Fuzzy Systems 11, 495–506 (2003)
Magnani, M.: Techniques for dealing with missing data in knowledge discovery tasks (2004) (Version of June 2004), http://magnanim.web.cs.unibo.it/data/pdf/missingdata.pdf
Kahl, F., et al.: Minimal Projective Reconstruction Including Missing Data. IEEE Trans. Pattern Anal. Mach. Intell. 23(4), 418–424 (2001)
Gessert, G.: Handling Missing Data by Using Stored Truth Values. SIGMOD Record, 2001 20(3), 30–42 (1991)
Pesonen, E., et al.: Treatment of missing data values in a neural network based decision support system for acute abdominal pain. Artificial Intelligence in Medicine 13(3), 139–146 (1998)
Ramoni, M., Sebastiani, P.: Robust Learning with Missing Data. Machine Learning 45(2), 147–170 (2001)
Pawlak, M.: Kernel classification rules from missing data. IEEE Transactions on Information Theory 39(3), 979–988 (1993)
Forgy, E.: Cluster analysis of multivariate data: Efficiency vs. interpretability of classifications. Biometrics 21, 768 (1965)
Blake, C.L., Merz, C.J.: UCI Repository of machine learning databases (1998)
Hamerly, H., Elkan, C.: Learning the k in k-means. In: Proc. of the 17th intl. Conf. of Neural Information Processing System (2003)
Zhang, S.C., et al.: Optimized Parameters for Missing Data Imputation. In: Yang, Q., Webb, G. (eds.) PRICAI 2006. LNCS (LNAI), vol. 4099, pp. 1010–1016. Springer, Heidelberg (2006)
Wang, Q., Rao, J.: Empirical likelihood-based inference in linear models with missing data. Scand. J. Statist. 29, 563–576 (2002a)
Wang, Q., Rao, J.N.K.: Empirical likelihood-based inference under imputation for missing response data. Ann. Statist. 30, 896–924 (2002b)
Silverman, B.: Density Estimation for Statistics and Data Analysis. Chapman and Hall, New York (1986)
Friedman, J., et al.: Lazy Decision Trees. In: Proceedings of the 13th National Conference on Artificial Intelligence, pp. 717–724 (1996)
John, S., Cristianini, N.: Kernel Methods for Pattern Analysis. Cambridge (2004)
Lakshminarayan, K., et al.: Imputation of Missing Data Using Machine Learning Techniques. KDD 1996, 140–145 (1996)
Author information
Authors and Affiliations
Editor information
Rights and permissions
Copyright information
© 2008 Springer-Verlag Berlin Heidelberg
About this chapter
Cite this chapter
Zhang, S., Zhang, J., Zhu, X., Qin, Y., Zhang, C. (2008). Missing Value Imputation Based on Data Clustering. In: Gavrilova, M.L., Tan, C.J.K. (eds) Transactions on Computational Science I. Lecture Notes in Computer Science, vol 4750. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-79299-4_7
Download citation
DOI: https://doi.org/10.1007/978-3-540-79299-4_7
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-79298-7
Online ISBN: 978-3-540-79299-4
eBook Packages: Computer ScienceComputer Science (R0)