
Abstract
Automatic semantic annotation of video events has received a large attention from the scientific community in the latest years, since event recognition is an important task in many applications. Events can be defined by spatio-temporal relations and properties of objects and entities, that change over time; some events can be described by a set of patterns.
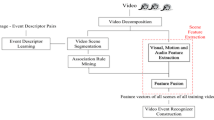
In this paper we present a framework for semantic video event annotation that exploits an ontology model, referred to as Pictorially Enriched Ontology, and ontology reasoning based on rules. The proposed ontology model includes: high-level concepts, concept properties and concept relations, used to define the semantic context of the examined domain; concept instances, with their visual descriptors, enrich the video semantic annotation. The ontology is defined using the Web Ontology Language (OWL) standard. Events are recognized using patterns defined using rules, that take into account high-level concepts and concept instances. In our approach we propose an adaptation of the First Order Inductive Learner (FOIL) technique to the Semantic Web Rule Language (SWRL) standard to learn rules. We validate our approach on the TRECVID 2005 broadcast news collection, to detect events related to airplanes, such as taxiing, flying, landing and taking off. The promising experimental performance demonstrates the effectiveness of the proposed framework.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


References
aceMedia project (IST EC-FP6): Integrating knowledge, semantics and content for user-centered intelligent media services, http://www.acemedia.org/
Aim@Shape project (IST EC-FP6): Advanced and innovative models and tools for the development of semantic-based systems for handling, acquiring, and processing knowledge embedded in multidimensional digital objects, http://www.aimatshape.net/
Boemie project (IST EC-FP6): Knowledge acquisition from multimedia content, http://www.boemie.org/
VidiVideo project (IST EC-FP6): Improving the accessibility of video, http://www.vidivideo.info/
Snoek, C., Huurnink, B., Hollink, L., de Rijke, M., Schreiber, G., Worring, M.: Adding semantics to detectors for video retrieval. IEEE Transactions on Multimedia 9(5), 975–986 (2007)
Zha, Z.J., Mei, T., Wang, Z., Hua, X.S.: Building a comprehensive ontology to refine video concept detection. In: Proc. of ACM Int’l Workshop on Multimedia Information Retrieval, Augsburg, Germany, pp. 227–236 (September 2007)
Simou, N., Saathoff, C., Dasiopoulou, S., Spyrou, E., Voisine, N., Tzouvaras, V., Kompatsiaris, I., Avrithis, Y., Staab, S.: An ontology infrastructure for multimedia reasoning. In: Atzori, L., Giusto, D.D., Leonardi, R., Pereira, F. (eds.) VLBV 2005. LNCS, vol. 3893. Springer, Heidelberg (2006)
Dasiopoulou, S., Mezaris, V., Kompatsiaris, I., Papastathis, V.K., Strintzis, M.G.: Knowledge-assisted semantic video object detection. IEEE Transaction on Circuits and Systems for Video Technology 15(10), 1210–1224 (2005)
Bertini, M., Del Bimbo, A., Torniai, C., Cucchiara, R., Grana, C.: Dynamic pictorial ontologies for video digital libraries annotation. In: Proc. ACM Int’l Workshop on the Many Faces of Multimedia Semantics, Augsburg, Germany, pp. 47–56 (2007)
Snoek, C., Worring, M.: Multimedia event-based video indexing multimedia event-based video indexing using time intervals. IEEE Transactions on Multimedia 7(4), 638–647 (2005)
Francois, A., Nevatia, R., Hobbs, J., Bolles, R., Smith, J.: VERL: an ontology framework for representing and annotating video events. IEEE Multimedia 12(4), 76–86 (2005)
Qasemizadeh, B., Haghi, H., Kangavari, M.: A framework for temporal content modeling of video data using an ontological infrastructure. In: Proc. Semantics, Knowledge and Grid, Guilin, China, November 2006, p. 38 (2006)
Bai, L., Lao, S., Jones, G., Smeaton, A.F.: Video semantic content analysis based on ontology. In: Proc. of Int’l Machine Vision and Image Processing Conference, Maynooth, Ireland, pp. 117–124 (2007)
Dorado, A., Calic, J., Izquierdo, E.: A rule-based video annotation system. Circuits and Systems for Video Technology. IEEE Transactions 14(5), 622–633 (2004)
Shyu, M.L., Xie, Z., Chen, M., Chen, S.C.: Video semantic event/concept detection using a subspace-based multimedia data mining framework. Multimedia, IEEE Transactions 10(2), 252–259 (2008)
Liu, K.H., Weng, M.F., Tseng, C.Y., Chuang, Y.Y., Chen, M.S.: Association and temporal rule mining for post-filtering of semantic concept detection in video. Multimedia, IEEE Transactions 10(2), 240–251 (2008)
Quinlan, J.R.: Learning logical definitions from relations. Mach. Learn. 5(3), 239–266 (1990)
Kennedy, L.: Revision of LSCOM event/activity annotations, DTO challenge workshop on large scale concept ontology for multimedia. Advent technical report #221-2006-7, Columbia University (December 2006)
Bagdanov, A.D., Del Bimbo, A., Dini, F., Nunziati, W.: Improving the robustness of particle filter-based visual trackers using online parameter adaptation. In: Proc. of IEEE Int’l Conference on AVSS, London, UK, pp. 218–223 (September 2007)
Author information
Authors and Affiliations
Editor information
Rights and permissions
Copyright information
© 2008 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Bertini, M., Del Bimbo, A., Serra, G. (2008). Learning Rules for Semantic Video Event Annotation. In: Sebillo, M., Vitiello, G., Schaefer, G. (eds) Visual Information Systems. Web-Based Visual Information Search and Management. VISUAL 2008. Lecture Notes in Computer Science, vol 5188. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-85891-1_22
Download citation
DOI: https://doi.org/10.1007/978-3-540-85891-1_22
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-85890-4
Online ISBN: 978-3-540-85891-1
eBook Packages: Computer ScienceComputer Science (R0)